一、IntHashMap
1.1 准备
先从官网下载jar包:javasoft-collection.jar,解压后将jar包build到Java项目中.
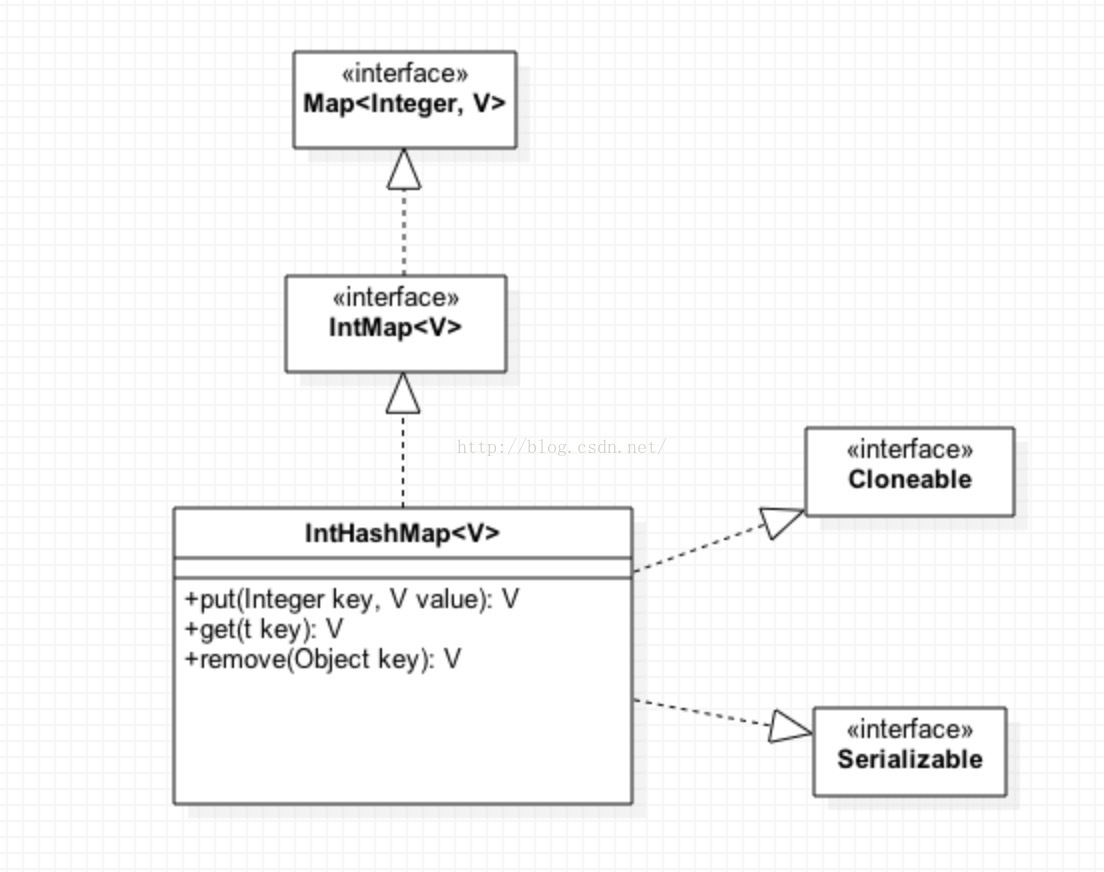
1.2 IntHashMap类图
1.3 IntHashMap流程图
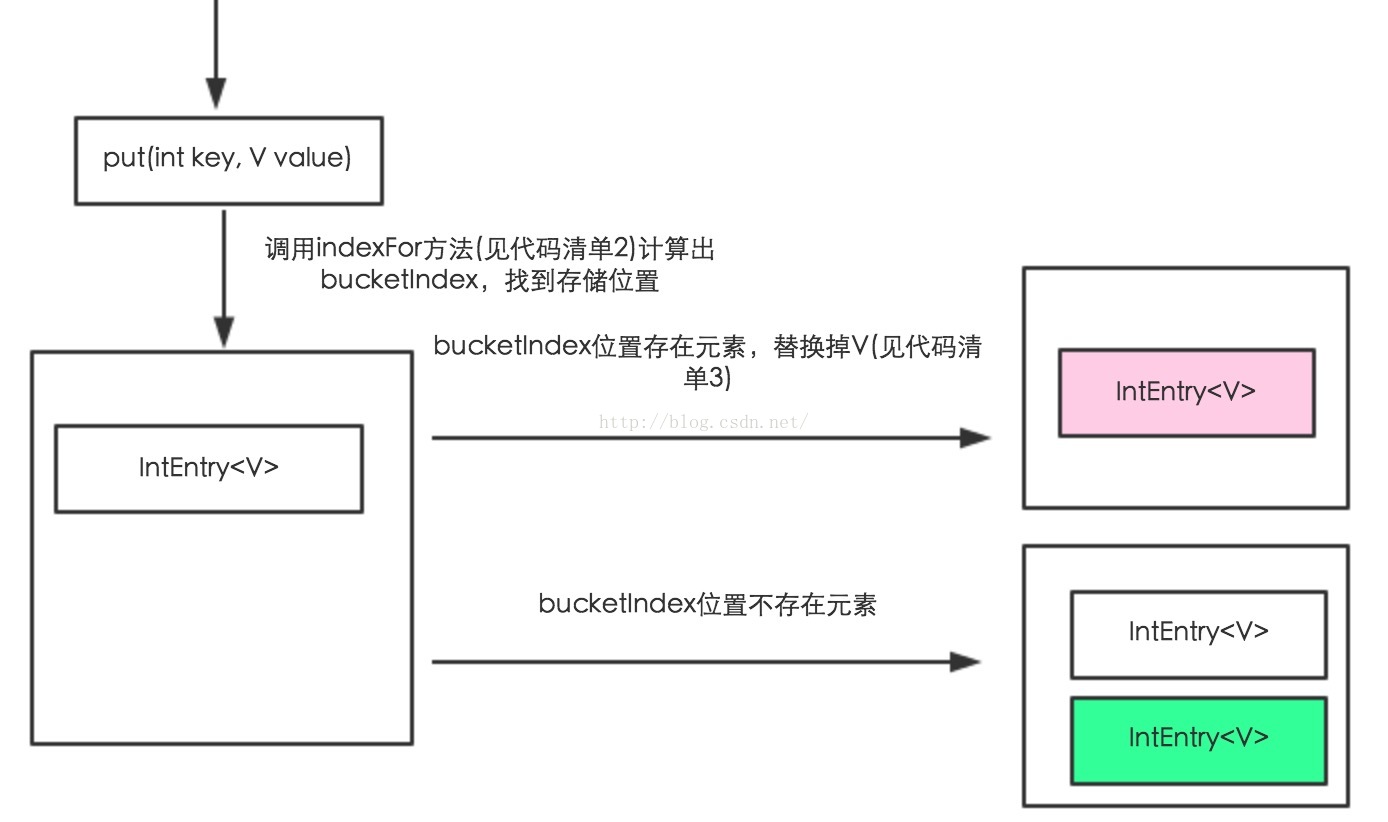
从上面类图可以看出IntHashMap和HashMap一样都是基于Map接口,在Map中最常用的2个方法是put()和get()方法。大家都知道Map是从键到值的映射,每个键不能出现重复且每个键最多只能映射到一个值。那么IntHashMap是如何保证键的唯一性?可能大家会想IntHashMap的键是int类型,使用==来比较,这样子虽然能保证键的唯一。但是随着元素的增加,每次都进行比较效率会越来越低。什么样的数据结构能快速的存储元素?答案是数组。在HashMap中是通过hash计算出bucketIndex位置找到数组中对应的元素,那么IntHashMap呢?IntHashMap亦如此,唯一不同的是计算bucketIndex的算法。通过indexFor()方法拿到bucketindex后。它会先去数组中找这个位置上的元素IntEntry<V>是否存在,如果存在的话,再通过key去查找value,然后将新值替换掉旧value。
代码清单2如下:
-
-
-
- protected int indexFor(int key, int length) {
- key += ~(key << 9);
- key ^= (key >>> 14);
- key += (key << 4);
- key ^= (key >>> 10);
- return key & (length-1);
- }
代码清单3如下:
- int i = indexFor(key, table.length);
-
- for (IntEntry<V> e = table[i]; e != null; e = e.next) {
- if (e.key == key) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
二、IntHashMap与HashMap比较
2.1 运行效率比较
创建一个测试类,分别往IntHashMap和HashMap各插入1万和5万条数据来测试它们性能、GC和内存使用
- package com.lll.operator;
-
- import java.util.HashMap;
- import java.util.Map;
-
- import ch.javasoft.util.intcoll.IntHashMap;
-
- public class ShiftTest {
-
-
- HashMap<Integer,String> map = new HashMap<Integer,String>();
-
- public void add()
- {
- for (int i = 0; i < 10000;i++) {
- for(int j = 0;j<50000;j++)
- {
- if(map.get(j) == null)
- {
- map.put(j, "小毛驴");
- }
- }
- }
- }
- public static void main(String[] args) {
- long curTime = System.currentTimeMillis();
- ShiftTest shiftTest = new ShiftTest();
- shiftTest.add();
- long curTime2 = System.currentTimeMillis();
- System.out.println("耗时:"+(curTime2-curTime)+"ms");
- try {
- Thread.sleep(5000);
- } catch (InterruptedException e) {
-
- e.printStackTrace();
- }
- }
-
- }
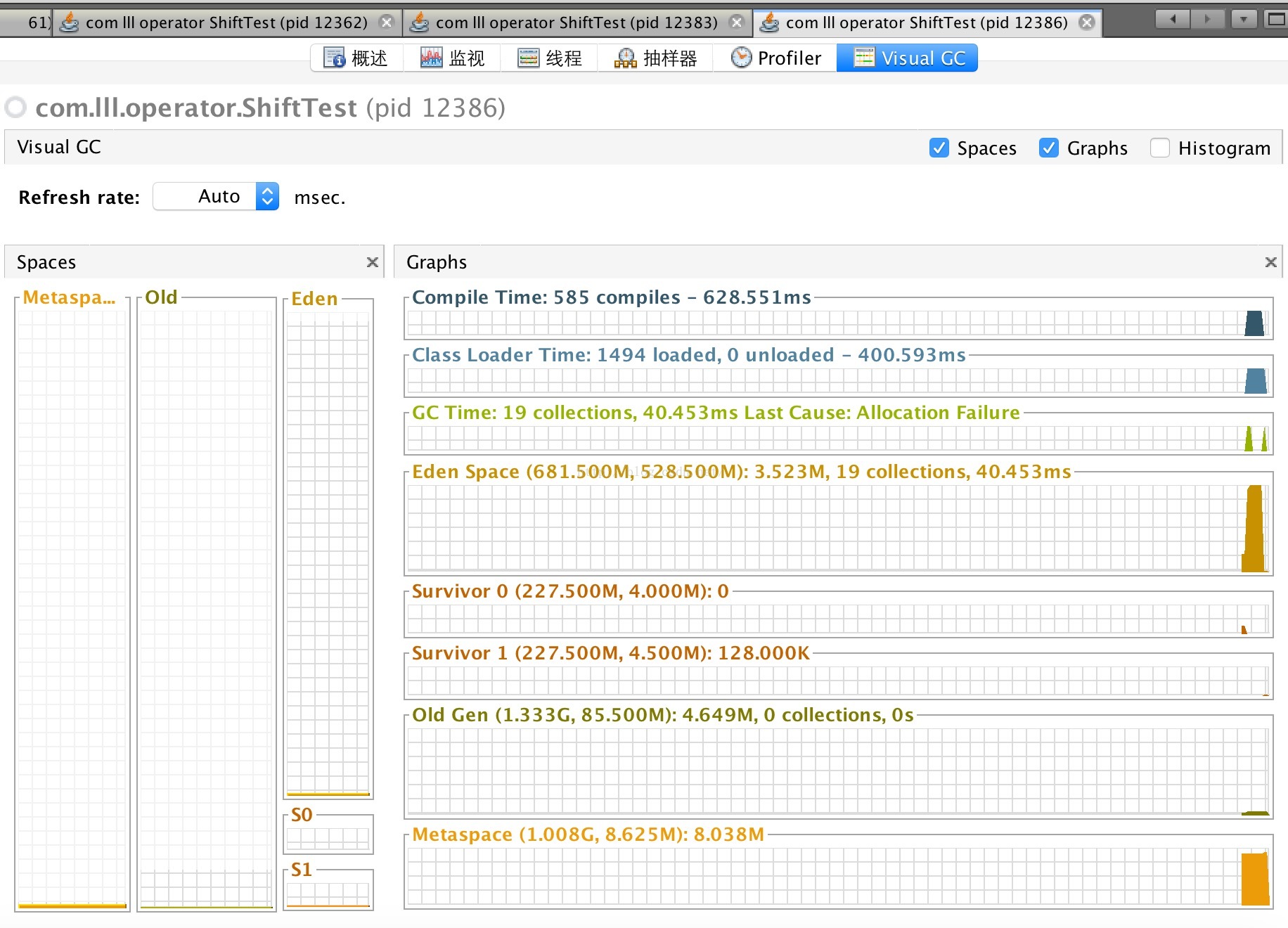
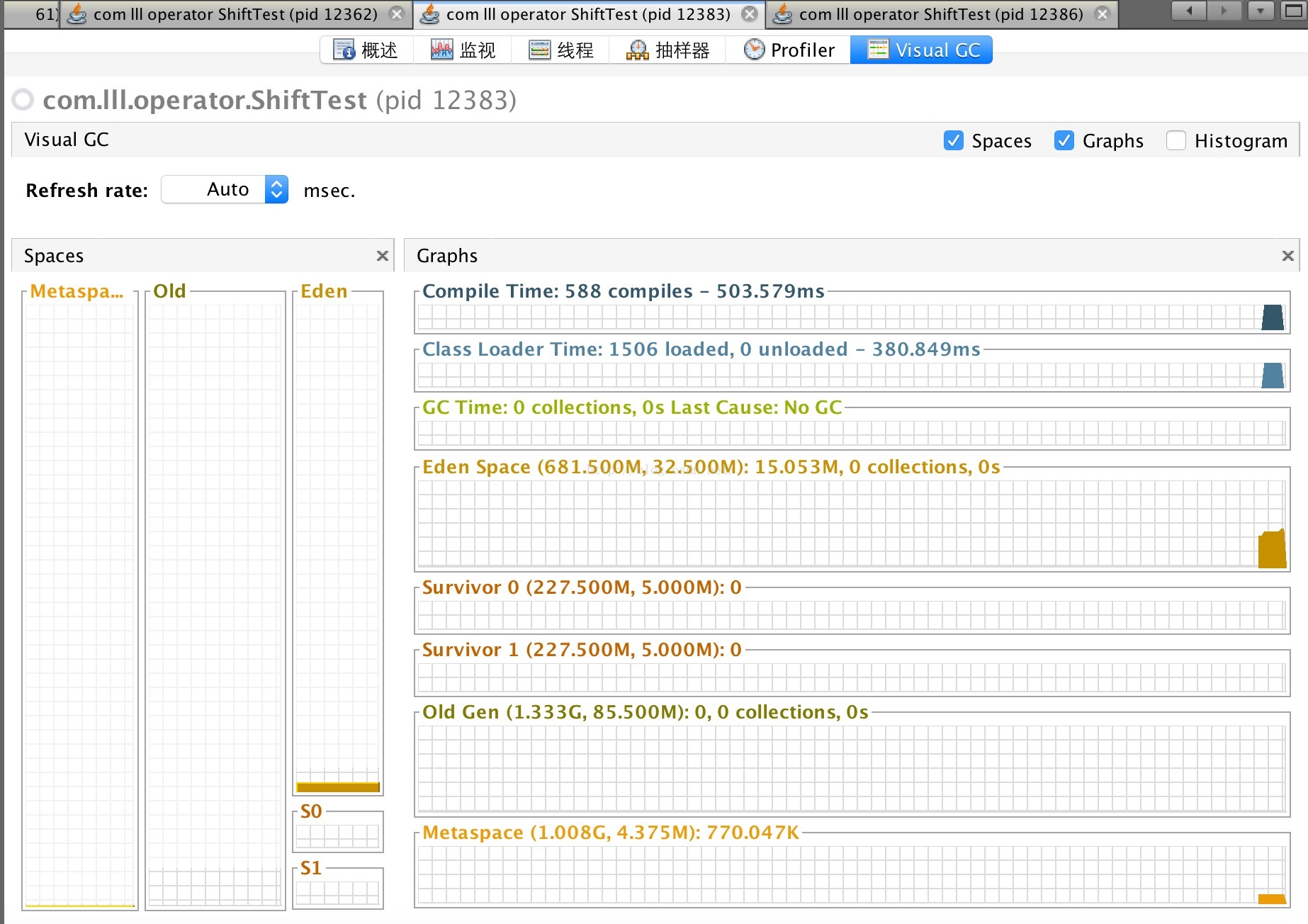
2.2 Visual GC比较
HashMap:
IntHashMap:
2.3 结果分析
10000条数据测
试结果:
| Map类型 | 第一次取样 | 第二次取样 | 第三次取样 | GC |
| IntHashMap | 795ms | 815ms | 807ms | NO GC |
| HashMap | 866ms | 927ms | 861ms | 11.978ms |
50000条数据测
试结果:
| Map类型 | 第一次取样 | 第二次取样 | 第三次取样 | GC时间 |
| IntHashMap | 5166ms | 4817ms | 4997ms | NO GC |
| HashMap | 4388ms | 4430ms | 3876ms | 40.453ms |
从上面的测试结果可以看出,HashMap会随着容器大小的变化效率明显变慢。也许从数据测试结果来看使用IntHashMap在性能上比HashMap并没有太大优势甚至效率还要低些,但是从GC上来看明显IntHashMap更有优势。那么是什么让他们产生这样的差异?
2.4 差异一
HashMap在插入元素过程中会在堆中产生大量的Integer实例(如下图-Profiler界面),参考代码清单4。而IntHashMap不一样,它是以int作为key值类型(见代码清单5),能够减少Integer实例的产生,减少GC负担。
Profiler界面

代码清单4:
- static class Entry<K,V> implements Map.Entry<K,V> {
- final K key;
- V value;
- Entry<K,V> next;
- int hash;
-
-
-
-
- Entry(int h, K k, V v, Entry<K,V> n) {
- value = v;
- next = n;
- key = k;
- hash = h;
- }
代码清单5:
- public static class IntEntry<VV> implements IntMap.IntEntry<VV> {
- protected final int key;
- protected VV value;
- protected IntEntry<VV> next;
-
-
-
-
- protected IntEntry(int k, VV v, IntEntry<VV> n) {
- value = v;
- next = n;
- key = k;
- }
2.5 差异二
在遍历时,IntHashMap(代码清单6)没有对hash进行比较。
代码清单6
- public V get(int key) {
- int i = indexFor(key, table.length);
- IntEntry<V> e = table[i];
- while (true) {
- if (e == null)
- return null;
- if (e.key == key)
- return e.value;
- e = e.next;
- }
- }
HashMap遍历代码清单7
- final Entry<K,V> getEntry(Object key) {
- int hash = (key == null) ? 0 : hash(key);
- for (Entry<K,V> e = table[indexFor(hash, table.length)];
- e != null;
- e = e.next) {
- Object k;
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- return e;
- }
- return null;
- }
文章如有错误之处,还请见谅并能给予指正!
本博客中未标明转载的文章归作者
小毛驴所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。























 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









