






本文结构思维导图

概述
友情提示:
1. 对于本文中数据集,训练集,特征点,空间等基础概念,请参考周志华老师的《机器学习》第一章的内容
2. Python的语法并不难理解,有编码基础的可以直接看懂,如果不懂,请参考廖雪峰老师的个人博客中Python的教学内容
http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
信息技术的发展分为五个阶段:
- 语言的使用,语言成为人类进行思想交流和信息传播不可缺少的工具。
- 文字的出现和使用,使人类对信息的保存和传播取得重大突破,较大地超越了时间和地域的局限。
- 印刷术的发明和使用,使书籍、报刊成为重要的信息储存和传播的媒体。
- 电话、广播、电视的使用,使人类进入利用电磁波传播信息的时代。
- 计算机与互连网的使用,即网际网络的出现。
在信息技术发展的第五个阶段之后,信息革命已经进入了重点阶段。每天大量的数据被产生,全世界约90%的数据是近两年产生的,在现代计算机计算性能的提高,于大量各种各样的数据作为支持下,机器学习技术迎来了高速发展的新机遇。
在概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科支持下。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
人工智能的核心就是机器学习,这是使计算机具有智能的根本方法,机器学期相关的应用遍及生活中的各个领域,比如专家系统、自动推理、模式识别、智能机器人、数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。它主要使用归纳、综合而不是演绎。
什么是机器学习,为什么要学习机器学习
现在特斯拉公司的无人车已经在国内外显示生活中开始使用,虽然现在无人车的技术不是十分的成熟,车祸事情时有发生,但是假以时日,无人车完全代替人类驾驶,交通事故率将会下降很多。
机器学习相关的岗位
精准推荐:负责推荐系统算法的开发,针对特定问题进行数学建模,并解决各种应用问题,如音乐歌曲的推荐,页面广告的推荐,相关信息的推送等。
数据挖掘:应用各类大数据技术,分析数据与记录,如挖掘用户的兴趣和意图,或从海量数据中发掘有价值的信息,建立多个维度上的模型,用于指导产品优化。
自然语言处理:机器翻译(machine translation,MT),自动文摘(automatic summarizing),信息检索(information retrieval),文档分类(document classification),问答系统(question-answering system),文字编辑和自动校对(atuomatic profreading),语言教学(language teaching),文字识别(OCR,optical character recognition),语音识别(speech recognition),文语转换(text-to-speech conversion),说话人识别验证(speaker recognition)。
此外还包括机器视觉,语音识别,图像识别,图像处理,深度学习,机器学习等岗位。
机器学习的五大流派
符号主义学派:将符号、现实规则和逻辑关系来表征知识和进行逻辑推理演绎,常用算法是 规则和决策树。
贝叶斯学派:根据事件发生的可能性与其他事件的关联性来判断,常用算法是 朴素贝叶斯或马尔可夫。
联结主义学派:使用概率矩阵和加权神经元来动态地识别和归纳的模型,常用算法是 神经网络。
进化主义学派:不断生成结果,寻找结果中的最优解方案,常用算法是 遗传算法。
Analogizer学派:根据约束条件来最大化的优化模型,常用算法是 支持向量机。
根据统计学分类机器学习算法
- 监督学习(有教师学习)
监督学习即输入的数据有相对应的标签,如识别猫的图片的时候,会标注哪些图像上有猫,哪些图像上没有猫,模型会学习图像上有猫的特征是是什么,和图像上没有猫的特征是什么。
结果就是让模型学习一个规则,当输入新的数据时可以得到一个预测或者分类的效果。
- 非监督学习(无教师学习)
非监督学习则相反,就是输入的信息不知道是什么分类,不知道规则,没有输出,结果就是寻找数据当中的规则。
- 半监督学习(半教师学习)
最近几年新起的半监督学习就是介于监督学习和半监督学习之间的,因为在实际生活环境中,人工标注数据成本过大,大部分的情况是遇到的数据都是没有经过标签的,所以用半监督学习可以先少量的标注一部分数据,然后寻找这部分数据的特征,自动给剩下的数据标注标签。
- 强化学习
增强学习强调如何基于环境而行动,以取得最大化的预期利益。有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。常被应用在机器人、无人机等领域。
根据数据处理方式分类机器学习算法
- 在线学习
在线学习就是在得到新的数据的时候直接加入到正在不断训练模型的数据集当中,这样可以不断的更新模型,但是对数据的要求比较高。好处在于可以随时更新模型的参数。
- 离线学习
与在线学习相反,当数据更新时,停下模型的训练,将原有数据一起预处理再输入到训练集中训练模型。
监督学习算法的分类
- 生成模型
生成模型是由数据学习联合概率分布P(X,Y),然后求出条件概率分布
P(Y|X)作为预测的模型,即生成模型:
P(Y|X)=P(X,Y)/P(X)模型表示了给定输入X产生输出Y的生成关系。典型的生成模型有:朴素贝叶斯方法和隐马尔可夫模型。
生成模型能够还原出联合概率分布P(X,Y);生成模型的收敛速度快,当样本容量增加的时候,学到的模型可以更快地收敛于真实模型;当存在隐变量时,仍可以使用生成学习方法,此时判别方法就不能用。
- 判别模型
判别方法由数据直接学习决策函数f(x)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。典型的判别模型包括:k近邻法、感知机、决策树、logistic回归模型、最大熵模型、支持向量机、提升方法和条件随机场。判别模型直接面对预测,往往学习的准确率越高。可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
机器学习和深度学习的区别
深度学习(deep learning)是机器学习里面的算法之一,是属于神经网络算法,但是今年来由于在图像图像,语音处理等领域取得了突破性的进展,所以被大家熟知。
人工智能,机器学习,深度学习关系与发展时间由下图所示。

机器学习的六大步骤
选择数据:将数据集分成三部分,分别是训练集、验证集和测试集。
模型数据:用训练集来构建相关特征的模型。
验证模型:将验证数据导入到模型中。
测试模型:测试集检查被验证模型的表现。
使用模型:训练好的模型在新数据上做预测,分类,聚类。
调优模型:用更多数据、不同的特征或调整过的参数来提升算法的性能表现,提高模型的泛化性。
机器学习问题的解决方案如下。

- 定义问题
在软件工程当中开始也是十分重要的一个环节就是软件的需求分析,同理,在“机器学习工程”当中开始的部分也是定义问题。一个问题是分类问题,聚类问题或者是预测问题在一开始就需要确定好。
- 对数据进行预处理
机器学习的所有算法和模型都是建立在数据之上的,好的数据对于问题的解决更加有益,所以数据的预处理就变得十分重要。首先是数据的收集过程,然后清理数据,去噪声,处理缺失数据,对于缺失数据是补充还是删除。
- 数据的分析
在kaggle中数据的分析的各种项目中是十分常见的步骤,数据的分析主要有两部组成。第一部分是数据的概述,第二部分是数据的可视化。数据的概述主要是对数据的结构和数据的分布做一个必要的分析,确认数据是以什么结构和数值型号存在的,其次是数据的分布,对于每一个维,特征点的选择,或许我们并不需要那么多的特征点,这里就要用正则化去删除一些关系性,对结果影响小的特征点。这一步中特征点的提取同样十分重要,合适特征点的选择直接影响了模型结果是否满意。数据的可视化就主要是对数据做一个散点图,条形图等便于直观理解数据的形式分布和类型即可。
- 算法的抽查
对于项目中的数据,可以用不同算法进行训练,然后选择初步效果最好的算法。如果数据集过于庞大,可以用部分数据进行训练。然后优化选中的算法,如果多次训练优化结果不满意,可以再试试别的算法再进行优化。

- 优化
如果模型的结果不满意,这时候就要对其进行优化。
- 算法调优(Algorithm tuning)
- 集成方法/集成学习(Ensembles)
- 极端特征工程(Extreme Feature Engineering)
算法调优:
机器学习的终极目标就是为了可以自动的从数据中构建模型,不需要认为的参与数据的处理,训练模型,评估模型,优化模型等步骤。但其中一个困难的点是算法的参数,模型当中的参数十分重要,如何调参将影响模型的最终结果。
比如用像KNN这样的分类算法,须指定使用的模型(或质心)中的K数,这时候可以为模型尝试许多不同的K值。
另一个例子,支持向量机(SVM)分类。SVM分类需要一个初始学习阶段,其中训练数据用于调整分类参数。这实际上是指初始参数调整阶段,可以像编程人员一样,尝试“调整”模型以获得高质量的结果。
现在,你可能会认为这个过程可能很繁琐,你是对的。事实上,由于难以确定哪些最优模型参数,一些研究人员在使用更好的调参进行更简单的替代方案之前,会使用复杂的学习算法。
集成方法/集成学习:
集成学习通过构建多个学习算法模型学习,最后整个成一个模块输出结果。换句话来说就是“三个臭皮匠顶个诸葛亮”,多个基础算法模型(又叫做弱学习器)集成一个结果输出。也可以理解为投票原则。

带入到二分类问题当中,结果有√和×2个结果,至少结果为2个√集成结果才为√。
| 分类器/数据集 | 数据集1 | 数据集2 | 数据集3 |
|---|---|---|---|
| 分类器结果1 | √ | √ | × |
| 分类器结果2 | × | √ | √ |
| 分类器结果3 | √ | × | √ |
| 集成结果 | √ | √ | √ |
集成学习之后效果提高。
| 分类器/数据集 | 数据集1 | 数据集2 | 数据集3 |
|---|---|---|---|
| 分类器结果1 | √ | √ | × |
| 分类器结果2 | √ | √ | × |
| 分类器结果3 | √ | √ | × |
| 集成结果 | √ | √ | × |
集成学习之后效果不好。
| 分类器/数据集 | 数据集1 | 数据集2 | 数据集3 |
|---|---|---|---|
| 分类器结果1 | √ | × | × |
| 分类器结果2 | × | √ | × |
| 分类器结果3 | × | × | √ |
| 集成结果 | × | × | × |
集成学习之后起到反作用,本来可以分类的算法反而集成之后无法实现分类。
现在集成学习的两个大放向为Boosting,和Bagging与随机森林。
Boosting是学习器之间存在强依赖关系。
Bagging与随机森林是学习器之间不存在强依赖关系,相互独立。
极端特征工程:
从数据集出发,分析数据结构,特征点提取之后进行分解或合并,优化特征点,这样得到的加工处理过的“新”数据集带入到模型训练当中会得到更好的结果。
- 结果展示
为了方便展示结果和便于人们理解,带入到实际应用当中,并展示结果。
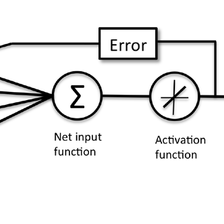
模型的训练过程主要分为以下四个步骤:

这里解释一下上图,举个简单的例子,高考复习是要做很多很多的练习题去巩固自己罪域知识点的理解是否透彻,然后再去做练习题,到期末检测或者质量检测的时候再不断的抓差补缺来不断的更新自己对于知识点的理解。等同于下图。

机器学习的起源与历史
人工智能发展史概述
1950年以前,统计方法被发现和并不断被改进。
1950年代,使用简单的算法进行开创性机器学习研究。
1970年代,机器学习表现性能不高的原因,悲观主义盛行,机器学习研究进入寒冬。
1980年代,反向传播的重新发现导致机器学习研究的复苏。
1990年代,机器学习的工作从知识驱动的方式转变为数据驱动的方法。科学家们开始创建计算机程序来分析大量数据,并从结果中得出结论或“学习”。支持向量机和复现神经网络变得流行起来。
2000年代,深度学习重新被广泛使用,神经网络看到广泛的商业用途。
2010年代,机器学习成为许多被广泛使用的软件服务的组成部分,并得到各大厂商的大力宣传。纷纷推出自己平台的计算硬件。
机器学习大事件纪年表
【贝叶斯定理的基础】1763年,托马斯·贝耶斯(ThomasBayes)的作品“解决机会原则”中的一个问题是在他死后两年出版的,经过贝叶斯的朋友理查德·价格的修改和编辑。这篇文章提出了支撑贝叶斯定理的工作。
【最小二乘法】1805,Adrien-MarieLegendre描述了以英文称为最小二乘法的“méthodedes moindrescarrés”。最小二乘法广泛应用于数据拟合。
【贝叶斯定理】1812年,Pierre-Simon Laplace发行ThéorieAnalytiquedesProbabilités,他扩展了贝叶斯的作品,并定义了现在称为贝叶斯定理。
【马尔可夫链】1913年,安德烈·马可夫首先描述了他用来分析一首诗的技巧。 这种技术后来被称为马尔科夫链。
【图灵机】1950年,艾伦·图灵(AlanTuring)提出了一种可以学习和人工智能的“学习机器”。图灵的具体建议预示着遗传算法的出现。
【第一个神经网络】1951年,Marvin Minsky和Edmonds建立了第一台能够学习SNARC的神经网络机器。
【机器跳棋程序】1952年,Arthur Samuel加入IBM的Poughkeepsie实验室,并开始研究一些机器学习计划,首先开发出下跳棋程序。
【感知机】1957年,Frank Rosenblatt在康奈尔航空实验室工作时发明了感知器算法。 大量的媒体报道了感知器算法被发明出来。
【k近邻算法(knn)】1967年,创建最近邻算法,这是基本模式识别的开始。 该算法被广泛应用于映射路由。
【神经网络的局限性】1969年,Marvin Minsky和Seymour Papert出版了他们的书Perceptrons,描述了感知器和神经网络的一些限制。 这本书显示神经网络基本上受到限制的解释被视为对神经网络研究的障碍。
【自动分化】1970年,Seppo Linnainmaa发布了嵌套可微分函数的离散连接网络的自动分化(AD)的一般方法。这与现代版本的反向传播相对应,但尚未被命名。
【斯坦福购物车】1979年,斯坦福大学的学生开发了一个可以导航和避开房间障碍物的推车。
【神经认知机】1980年,邦彦福岛首先出版他的Neocognitron作品,这是一种人工神经网络。认知后来激发卷积神经网络。
【基于解释学习】1981年,Gerald Dejong介绍了基于说明的学习,其中计算机算法分析数据并创建可以遵循的一般规则,并丢弃不重要的数据。
【递归神经网络】1982年,约翰·霍普菲尔德(Hop Hopfield)普及了霍普菲尔德网络(Hopfield Networks),一种可用作可内容寻址的内存系统的循环神经网络。
【NetTalk】1985年,Terry Sejnowski开发了一种学习用与婴儿相同的方式发音的程序。
【反向传播】1986年,反向传播的过程由David Rumelhart,Geoff Hinton和Ronald J. Williams描述。
【强化学习】1989年,克里斯托弗·沃特曼斯(Christopher Watkins)开发Q-learning,大大提高了强化学习的实用性和可行性。
【个人电脑上机器学习的商业化】1989年,Axcelis公司发布Evolver,这是第一个在个人电脑上使用遗传算法进行商业化的软件包。
【玩西洋双陆棋的机器】1992年,杰拉尔德·泰索罗(Gerald Tesauro)开发了TD-Gammon,一款计算机西洋双陆棋程序,它利用了使用时差学习训练的人造神经网络(因此以“TD”的名义)。 TD-Gammon能够与顶级人类西洋双陆棋玩家的能力相提并论,但并不总是超越。
【随机森林算法】1995年,田锦浩出版了一篇描述随机决策林的论文。
【IBM深蓝击败卡斯帕罗夫】1997年,IBM的Deep Blue在国际象棋中击败世界冠军。
【支持向量机】1995年,Corinna Cortes和Vladimir Vapnik发表了他们在支持向量机上的工作。
【LSTM】1997年,Sepp Hochreiter和JürgenSchmidhuber发明了长期记忆复发神经网络,大大提高了复发神经网络的效率和实用性。
【MNIST数据库】1998年,由Yann LeCun领导的团队发布了MNIST数据库,这是一个数据集,其中包含美国人口普查局员工和美国高中学生的手写数字。MNIST数据库已成为评估手写识别的基准。
【火炬机器学习库】2002年,火炬机器学习库首次发布。
【Netflix奖】2006年,Netflix大奖由Netflix推出。 比赛的目的是使用机器学习来击败Netflix自己的推荐软件的准确性,以预测用户对以前电影的评分至少10%的电影评级。该奖项在2009年获胜。
【Kaggle比赛】2010年,Kaggle是一个作为机器学习竞赛平台的网站。
【打败人类】2011年,使用机器学习,自然语言处理和信息检索技术的组合,IBM的沃森击败了两个人类的冠军。
【识别YouTube上的猫】2012年,由Andrew Ng和Jeff Dean领导的Google Brain团队创建了一个神经网络,通过观看从YouTube视频框架中获取的未标记图像,学习识别猫。
【人脸识别飞跃发展】2014年,Facebook研究人员在DeepFace上发表了自己的研究成果,该系统使用神经网络来识别具有97.35%准确度的面孔。 结果是比以前的系统和对手人类表现超过27%的改进。
【Sibyl】2014年,Google的研究人员详细介绍了Sibyl的工作,Sibyl是Google内部使用的大规模并行机器学习的专有平台,用于对用户行为进行预测并提供建议。
【谷歌的AlphaGo战胜人类】2016年,Google的AlphaGo计划成为第一个使用机器学习和树型搜索技术相结合的打击无障碍专业人员的“计算机科技”计划。
机器学习的实战步骤
分析问题
当遇到一个实际问题想要用机器学习的方法来解决的时候,首先要分析问题,确定问题类型,是要聚类分类,还是要预测结果。然后确定可以收集到的数据信息,更具数据的类型,特征量思考能否得出我们想要的结果,特征和结果之间有没有必然的联系。比如,我们要预测上海地区未来房租的价格,首先要收集的肯定是过去上海各地区的房租价格,然后想人口数量有可能会影响房租价格,人口越多,房租越贵,其次想到物价水平也有可能对房租产生影响,等等。但是中国北方下不下雨就对上海的房租影响就没有多大关系了。所以分析到这,影响上海地区房租水平的可能是过去的房租,人口数量和当年物价水平。与软件工程中的需求分析步骤相同,在整个机器学习问题中这一步十分重要。
数据的收集
数据的收集有很多种方法,网络上的信息可以用爬虫下载,现在也有很多数据网站,比如UCI,Kaggle,ImageNet等等。
数据的预处理
这一步是十分重要,数据的好坏直接影响训练集和好坏,这会直接影响模型的训练程度。首先观察数据信息是否有缺损,可以先用算法补全信息,这一步算是预测(数据补全)。其次可以用PCA等方法对数据进行降维处理,去除为结果影响度不高的特征量(数据清洗)。数据的结构也要统一,便于模型训练就好(数据变换)。建立数据仓库,将多个数据源的数据集中到一个数据集当中(数据集成)。在尽可能保持数据原貌的前提下,最大限度地精简数据量(数据归约)。
模型的训练
这一步就是编码,输入训练集,对模型进行训练,更新模型参数。
模型的评价
带入测试集测试模型,如果效果好则模型好,差则反之。
模型的改良
带入新的数据集对模型参数进一步更新优化,或者用别的算法,或者强化分类器等方法对模型进行优化。
机器学习的几个重要概念
奥卡姆剃刀
“若有多个假设与观察一致,则选择最简单的那一个。”即在多个模型效果相同的情况下,选择模型最简单的那一个。
比如给出两个点,(0,0)和(1,1),模型有2个,一个是y=x,另外一个是y=x^2,由于后一个是二元二次方程比前者二元一次方程要复杂,所以选择y=x比较简单的二元一次方程。
没有免费午餐理论(no free lunch theorems)
即在脱离实际问题的情况下是没有最好,最坏的算法。哪一个算法好,哪一个算法坏,必须要针对现实的问题具体分析。
欠拟合与过拟合

1. 欠拟合
模型较好地学习了训练集的特征量,不能很好地拟合数据。
解决方法:
适当加入特征量。
比如,模型y=x欠拟合,我们可以加入别的特征向量,把模型变成y=x1+x2+x3,这样特征量变多了可以更好的表示模型。降低正则化参数,正则化的作用是防止过拟合,如果模型出现了欠拟合,则需要降低正则化参数。

2. 过拟合
学习过训练集里的噪声数据,与欠拟合相反,模型过度的学习训练集的特征量,过好地拟合数据,模型的泛化能力太差,意思就是模型结果和数据集太吻合,放到别的测试集里效果就会变的很差。
解决方法:
再次清洗数据,数据不纯可能导致结果过拟合。
增加训练集,训练集过小可能导致结果过拟合。
正则化。
偏差与方差
偏差:模型预测结果与实际的结果相差的距离,差距越大,偏差越大,如下图第二行所示。
方差:模型预测结果的变化范围,离散横渡,如果数据分布越分散则数据方差越大。如下图右列所示。

机器学习常用开发工具
scikit-learn
http://scikit-learn.org/stable/
建立在NumPy,SciPy和matplotlib上,Python中的机器学习库,简单高效的数据挖掘和数据分析工具。
功能有分类(SVM,nearest neighbors,random forest等),回归(SVR, ridge regression, Lasso等),聚类(k-Means, spectral clustering, mean-shift等),降维(PCA, feature selection, non-negative matrix factorization等),选择模型(grid search, cross validation, metrics等),预处理(preprocessing, feature extraction等)。
OpenCV(图像处理与毕业论文大杀器)
OpenCV具有C ++,C,Python和Java接口,并支持Windows,Linux,Mac OS,iOS和Android。
OpenCV专为计算效率而设计,并强调实时应用。
以优化的C / C ++编写,库可以利用多核处理。
通过OpenCL启用,可以利用底层异构计算平台的硬件加速。
OpenCV已经通过世界各地的用户社区超过4.7万人,估计下载量超过1400万。
使用范围从互动艺术,到矿山检查,在网上缝合地图或通过先进的机器人。
http://blog.csdn.net/sileixinhua/article/details/72810858
使用OpenCV,40行代码检测人脸图像。
tensorflow
TensorFlow™是使用数据流图进行数值计算的开源软件库。
图中的节点表示数学运算,而图形边缘表示在它们之间传递的多维数据阵列(张量)。
灵活的架构允许您使用单个API将计算部署到桌面,服务器或移动设备中的一个或多个CPU或GPU。
TensorFlow用于进行机器学习和深层神经网络研究,但该系统普遍足以适用于各种其他领域。
caffe
http://caffe.berkeleyvision.org/
Caffe是一个深度学习框架,特点为速度和模块化。
http://demo.caffe.berkeleyvision.org/
cffe官方一个分类器的demo,可以上传照片然后查看分类结果
pyTouch
PyTorch是一个深度学习框架,将Python放在首位。
近年来PyTorch热度上升,值得学习。
Java-ML
http://java-ml.sourceforge.net/
Java-ML简而言之,机器学习算法的集合,有每种算法的公共接口和类型,主要针对软件工程师和程序员,所以没有GUI,但界面清晰,良好的源代码。,大量的代码示例和教程。
如果你实际开发环境是java的话比较推荐。
Spark
Apache Spark是用于大规模数据处理的快速和通用引擎。
运行程序比Hadoop MapReduce在内存中快100倍,或者在磁盘上运行速度要快10倍。
在Java,Scala,Python,R中快速编写应用程序。
结合SQL,流式传输和复杂分析。
Spark在Hadoop,Mesos,独立或云端运行。 它可以访问不同的数据源,包括HDFS,Cassandra,HBase和S3。
NumPy,pandas,matplotlib
NumPy是使用Python进行科学计算的基础软件包。
强大的N维数组对象,复杂(广播)功能,用于集成C / C ++和Fortran代码的工具,有用的线性代数,傅里叶变换和随机数能力。
pandas为Python编程语言提供高性能,易于使用的数据结构和数据分析工具。
Matplotlib是一个Python 2D绘图库,可以跨平台生成各种硬拷贝格式和交互式环境的出版品质量图。 Matplotlib可用于Python脚本,Python和IPython shell,jupyter笔记本,Web应用程序服务器和四个图形用户界面工具包。
keras
Keras是一种高级神经网络API,用Python编写,能够运行在TensorFlow,CNTK或Theano之上。
开发重点是实现快速实验。能够从想法到结果尽可能快速的实现。
允许简单快速的原型(通过用户友好,模块化和可扩展性)。
支持卷积网络和递归网络,以及两者的组合。
在CPU和GPU上无缝运行。
theano
http://deeplearning.net/software/theano/
Theano是一个Python库,定义,优化和评估涉及多维数组的数学表达式。
与NumPy紧密集成 - 在Theano编译的函数中使用numpy.ndarray。
透明使用GPU - 执行数据密集型计算比在CPU上快得多。
有效的象征性差异 - Theano用一个或多个投入为衍生工具做功能。
速度和稳定性优化 - 即使x很小,也能为日志(1 + x)找到正确的答案。
动态C代码生成 - 更快地评估表达式。
广泛的单元测试和自我验证 - 检测和诊断许多类型的错误。
NLTK
NLTK是构建Python程序以处理人类语言数据的领先平台。
它为超过50种语料库和词汇资源(如WordNet)提供易于使用的界面,
以及一套用于分类,标记化,词根,标记,解析和语义推理的文本处理库,可用于工业级应用。
jieba
https://pypi.python.org/pypi/jieba/
“结巴”中文分词:做最好的 Python 中文分词组件。
Storm
最火的流式处理框架。
Storm可以轻松地可靠地处理无限流数据,实时处理Hadoop对批处理的处理。
可用于实时分析,在线机器学习,连续计算,分布式RPC,ETL等。
Julia/R
Julia是数字计算中高性能动态编程语言。
它提供了一个复杂的编译器,可以分布式并行执行,高精度数字和广泛的数学函数库。
Julia的基础库主要用于Julia本身,还集成了成熟的,最好的开源C和Fortran库,用于线性代数,随机数生成,信号处理和字符串处理。
此外,Julia开发人员社区正在通过Julia的内置软件包管理器快速提供一些外部软件包。
Jupyter和Julia社区合作的IJulia为Julia提供了强大的基于浏览器的图形笔记本界面。
R是用于统计计算和图形的免费软件环境。 它可以在各种UNIX平台(Windows和MacOS)上编译和运行。
Weka
http://www.cs.waikato.ac.nz/ml/weka/
Weka是数据挖掘任务的机器学习算法的集合。
这些算法可以直接应用于数据集,也可以从您自己的Java代码中调用。
Weka包含用于数据预处理,分类,回归,聚类,关联规则和可视化的工具。
机器学习初步实战
数据分析入门:Weka的使用(只要四步,不会编码也可以做机器学习与数据分析)
- http://www.cs.waikato.ac.nz/ml/weka/downloading.html 下载对应的Weka,并安装,运行。
- 点击Explorer。
- 点击Open file…选择weka安装文件夹下的data文件夹中的iris.arff数据文件。
- 点击Classify->choose,选择bayes下的nativeBayes算法,让后点击start。显示以下结果。



=== Run information ===
Scheme: weka.classifiers.bayes.NaiveBayes
Relation: iris-weka.filters.supervised.attribute.AddClassification-Wweka.classifiers.rules.ZeroR
Instances: 150
Attributes: 5
sepallength
sepalwidth
petallength
petalwidth
class
Test mode: 10-fold cross-validation
=== Classifier model (full training set) ===
Naive Bayes Classifier
Class
Attribute Iris-setosa Iris-versicolor Iris-virginica
(0.33) (0.33) (0.33)
===============================================================
sepallength
mean 4.9913 5.9379 6.5795
std. dev. 0.355 0.5042 0.6353
weight sum 50 50 50
precision 0.1059 0.1059 0.1059
sepalwidth
mean 3.4015 2.7687 2.9629
std. dev. 0.3925 0.3038 0.3088
weight sum 50 50 50
precision 0.1091 0.1091 0.1091
petallength
mean 1.4694 4.2452 5.5516
std. dev. 0.1782 0.4712 0.5529
weight sum 50 50 50
precision 0.1405 0.1405 0.1405
petalwidth
mean 0.2743 1.3097 2.0343
std. dev. 0.1096 0.1915 0.2646
weight sum 50 50 50
precision 0.1143 0.1143 0.1143
Time taken to build model: 0 seconds
=== Stratified cross-validation ===
=== Summary ===
Correctly Classified Instances 144 96 %
Incorrectly Classified Instances 6 4 %
Kappa statistic 0.94
Mean absolute error 0.0342
Root mean squared error 0.155
Relative absolute error 7.6997 %
Root relative squared error 32.8794 %
Total Number of Instances 150
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure MCC ROC Area PRC Area Class
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 Iris-setosa
0.960 0.040 0.923 0.960 0.941 0.911 0.992 0.983 Iris-versicolor
0.920 0.020 0.958 0.920 0.939 0.910 0.992 0.986 Iris-virginica
Weighted Avg. 0.960 0.020 0.960 0.960 0.960 0.940 0.994 0.989
=== Confusion Matrix ===
a b c <-- classified as
50 0 0 | a = Iris-setosa
0 48 2 | b = Iris-versicolor
0 4 46 | c = Iris-virginica
从结果可以看出识别精度是96%。
到目前位置你没有写一行代码,但是却用机器学习的算法实现了一个iris花的分类识别,在这个iris花数据集中有五个特征,分别是sepallength,sepalwidth,petallength,petalwidth和结果花的种类class。
试想一下,如果你是一名HR,你手头有很多客户的数据,但是你推荐人选要一个筛选,一个个对应的岗位去推荐,如果你将客户的信息,比如技术,薪资,期望公司地址等等信息分别开来,带入weka中,就会根据以往的推荐,自动的给你分门别类的自动推荐客户去目标公司,这就是机器学习在实际生活中的用处。
机器学习的“Hello World” MNIST手写字体识别(用SVM支持向量机算法)
复制以下代码并运行。
print(__doc__)
import matplotlib.pyplot as plt
# 载入matplotlib中画图库
from sklearn import datasets, svm, metrics
# 载入sklearn中样本数据集,svm算法,和矩阵处理库
digits = datasets.load_digits()
# 导入datasets样本数据集中 MNIST手写字体识别数据进digits
images_and_labels = list(zip(digits.images, digits.target))
# 导入的数据分类图像和标签两部分,即数字图像和对应的数字标签
for index, (image, label) in enumerate(images_and_labels[:4]):
plt.subplot(2, 4, index + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Training: %i' % label)
# 包括标签和图像在内的一共8组训练图像
n_samples = len(digits.images)
# 获取样本数
data = digits.images.reshape((n_samples, -1))
# 将图像转换成矩阵
classifier = svm.SVC(gamma=0.001)
# 使用SVM算法
classifier.fit(data[:n_samples // 2], digits.target[:n_samples // 2])
# 分类图像
expected = digits.target[n_samples // 2:]
predicted = classifier.predict(data[n_samples // 2:])
# 计算预测值
print("Classification report for classifier %s:\n%s\n"
% (classifier, metrics.classification_report(expected, predicted)))
# 输出分类后的结果信息
print("Confusion matrix:\n%s" % metrics.confusion_matrix(expected, predicted))
# 输出混淆矩阵(confusion_matrix)下面介绍什么是混淆矩阵
images_and_predictions = list(zip(digits.images[n_samples // 2:], predicted))
for index, (image, prediction) in enumerate(images_and_predictions[:4]):
plt.subplot(2, 4, index + 5)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Prediction: %i' % prediction)
# 包括标签和图像在内的一共8组预测图像
plt.show()
# 输出结果图像


混淆矩阵(confusion_matrix)
混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。
| option | Negative | Positive |
|---|---|---|
| Negative | A | B |
| Positive | C | D |
- a 表示伪的预测正确值 即错误的信息被预测为错误的信息 预测正确
- b 表示伪的预测错误值 即错误的信息被预测为正确的信息 预测错误
- c 表示真的预测错误值 即错误的正确被预测为错误的信息 预测正确
- d 表示真的预测正确值 即错误的正确被预测为正确的信息 预测错误
Iris花数据集分析
复制粘贴并运行以下代码
print(__doc__)
import matplotlib.pyplot as plt
# 导入matplotlib画图
from mpl_toolkits.mplot3d import Axes3D
# 导入mpl_toolkits画3D图像
from sklearn import datasets
# 导入sklearn自带的训练集
from sklearn.decomposition import PCA
# 导入特征降维的PCA主成分分析法
iris = datasets.load_iris()
# 导入iris花数据集进iris变量中
X = iris.data[:, :2]
# 导入图像数据给X变量,只使用头两个特征向量
y = iris.target
# 导入图像标签给Y,即图像的结果,如1.2.3...9
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
# 设置下,y的最大值和最小值
plt.figure(2, figsize=(8, 6))
plt.clf()
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
# 设置输出图像为散点图
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
# 设置输出图像的X轴和Y轴的标签
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
fig = plt.figure(1, figsize=(8, 6))
ax = Axes3D(fig, elev=-150, azim=110)
# 设置3D图像
X_reduced = PCA(n_components=3).fit_transform(iris.data)
#用PCA给特征向量降维
ax.scatter(X_reduced[:, 0], X_reduced[:, 1], X_reduced[:, 2], c=y,
cmap=plt.cm.Paired)
# 在3D图像中显示散点信息
ax.set_title("First three PCA directions")
# 设置3D图像标题
ax.set_xlabel("1st eigenvector")
ax.w_xaxis.set_ticklabels([])
ax.set_ylabel("2nd eigenvector")
ax.w_yaxis.set_ticklabels([])
ax.set_zlabel("3rd eigenvector")
ax.w_zaxis.set_ticklabels([])
# 设置3D图像的X,Y,Z轴
plt.show()
# 输出图像

支持向量机(SVM)人脸识别
复制粘贴并运行以下代码
from __future__ import print_function
from time import time
import logging
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import fetch_lfw_people
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import PCA
from sklearn.svm import SVC
# 导入必要的数据集和算法
print(__doc__)
# 在stdout上显示进度日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# 图像数组以找到形状(绘图)
n_samples, h, w = lfw_people.images.shape
# 对于机器学习,我们直接使用2个数据(由于该模型忽略了相对像素位置信息)
X = lfw_people.data
n_features = X.shape[1]
# 预测的标签是该人的身份
y = lfw_people.target
# y为特征脸的标签
target_names = lfw_people.target_names
# 设置标签的名字
n_classes = target_names.shape[0]
print("Total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_classes: %d" % n_classes)
# 分为测试集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)
# 测试集大小为全部数据集的25%
n_components = 150
print("Extracting the top %d eigenfaces from %d faces"
% (n_components, X_train.shape[0]))
t0 = time()
# 记时
pca = PCA(n_components=n_components, svd_solver='randomized',
whiten=True).fit(X_train)
# 设置PCA降维
print("done in %0.3fs" % (time() - t0))
# 输出总耗时
eigenfaces = pca.components_.reshape((n_components, h, w))
# 将图像转换为矩阵向量
print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
X_train_pca = pca.transform(X_train)
# 在测试集上PCA降维
X_test_pca = pca.transform(X_test)
# 在数据集上PCA降维
print("done in %0.3fs" % (time() - t0))
print("Fitting the classifier to the training set")
t0 = time()
param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)
clf = clf.fit(X_train_pca, y_train)
print("done in %0.3fs" % (time() - t0))
print("Best estimator found by grid search:")
print(clf.best_estimator_)
print("Predicting people's names on the test set")
t0 = time()
y_pred = clf.predict(X_test_pca)
print("done in %0.3fs" % (time() - t0))
print(classification_report(y_test, y_pred, target_names=target_names))
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""Helper function to plot a gallery of portraits"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
# 绘制测试结果的一部分
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return 'predicted: %s\ntrue: %s' % (pred_name, true_name)
prediction_titles = [title(y_pred, y_test, target_names, i)
for i in range(y_pred.shape[0])]
plot_gallery(X_test, prediction_titles, h, w)
# 绘制特征脸
eigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
plt.show()



多层感知机识别MNIST手写字体识
1.安装tensorlfow
python.exe -m pip install --upgrade pip
pip install tensorflow2.复制粘贴并运行以下代码,下载数据集要花一段时间
import tensorflow as tf
# 导入tensorflow
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# 这里可以初步理解为k
# 我们设立一个y=kx+b的方程,我们导入数据x,y,有很多个这样二元一次方程被设立
# 根据这个二元一次方程组可以求出k和b的值,然后带入新的数据x,则可以求出结果y
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 同理这里可以初步理解为b
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1,1,1,1], padding='SAME')
# 转换为2d
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
# 设置最大为2x2
sess = tf.InteractiveSession()
# 设置sess
x = tf.placeholder("float", shape=[None, 784])
# 设置X输入数组
x_image = tf.reshape(x, [-1,28,28,1])
W_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 设置激活函数
y_ = tf.placeholder("float", shape=[None, 10])
# 设置结果y
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 设置训练步长
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
# 设置正确预测
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# 设置结果精确度
sess.run(tf.initialize_all_variables())
# 运行
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
feed_dict = {x:batch[0],y_:batch[1],keep_prob:1.0}
train_accuracy = accuracy.eval(feed_dict=feed_dict)
print("step %d, training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x:batch[0],y_:batch[1],keep_prob:0.5})
#不断训练模型,根新参数
feed_dict={x:mnist.test.images, y_: mnist.test.labels,keep_prob:1.0}
print("test accuracy %g" % accuracy.eval(feed_dict=feed_dict))
# 输出结果
参考文献
- http://baike.baidu.com/link?url=Ge-4F7gXOGxDHi51DPz7_b56QweyViL9cLFKbpMs9QkWgT4LPm8MeHttJ_Ab-TfQ2885p6E6cYW5rQ5Fu8W4lZ_JqohW3HwJeMscz46IVOWbSj36s7ipCzp3E0btFMXB
- http://baike.baidu.com/link?url=lsVLhyRFzq-dyJqNEjNODHhr60KzD57GAmetcpaKlVR1oCr6qS8JfFGFt4C8JvWLLhqxB8oqql6bfxbm1XxkOWOkjvB4EUZRhz6pXL6yit_
- http://www.sohu.com/a/113502402_464065
- https://en.wikipedia.org/wiki/Timeline_of_machine_learning
- https://zhidao.baidu.com/question/1049414661018859259.html
- http://baike.baidu.com/link?url=KZ1GgfnZjSRcRFVsA-kExSnlw6eX0BENgSjkaF-khkQhObjNGF1UCtEcfldeBLzJlIj1vbVrgv2sXtq2GxaO1BA_gBg8qUFiyKB7FqVQhKmZ2JhQHKs38GUT_7GToMv6
- http://www.sohu.com/a/137630674_358836
- http://blog.csdn.net/tuqinag/article/details/54730360
- http://www.netlib.org/utk/people/JackDongarra/WEB-PAGES/cscads-libtune-09/talk24-vuduc.pdf
- https://stackoverflow.com/questions/22903267/what-is-tuning-in-machine-learning
- http://www.cyzone.cn/a/20170422/310196.html
- 《统计自然语言处理》宗成庆
- http://aidiary.hatenablog.com/entry/20140205/1391601418
- http://scikit-learn.org/dev/auto_examples/applications/plot_face_recognition.html#sphx-glr-auto-examples-applications-plot-face-recognition-py
- http://scikit-learn.org/dev/auto_examples/datasets/plot_iris_dataset.html#sphx-glr-auto-examples-datasets-plot-iris-dataset-py
- 《机器学习》周志华
更新列表
2017年6月23日15:50:42
根据张汉东的意见修改如下:
1. 加上机器学习和深度学习的区别
2. 加上weka这个工具的介绍
3. 实战段落修改
4. 什么是机器学习那一段,再放前面来
5. 机器学习的起源和历史,放到概述后面
——————————————————————————————————-
有学习机器学习相关同学可以加群,交流,学习,不定期更新最新的机器学习pdf书籍等资源。
QQ群号: 657119450
















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









