







大数据分析与机器学习简介
本章将首先介绍下大数据分析的原理与应用领域、机器学习的基本概念以及Python在数据科学中的作用,然后我们会讲解如何安装Python及使用相关的代码编辑器,最后我们会提及如何快速掌握Python的基础知识。
源代码
https://shimo.im/docs/y6cCpQWqXCWvvyy8/ 《Python源代码及相关福利(机器学习)》
1.1 大数据分析与机器学习概述
说到大数据分析与机器学习(Machine Learning),有的读者可能会感觉比较陌生,然而说到AlphaGo这一击败了世界顶级围棋选手的智能机器人,想必大家都有些耳闻。AlphaGo背后的原理就是大数据分析,通过机器不停的训练与学习,在海量的数据积累后,AlphaGo逐渐掌握了大量的围棋技巧,并凭借高速的计算能力击败了顶级围棋选手。机器学习便是模拟或实现人类的学习行为,以探寻大数据背后的规律,机器学习某种程度上可以说是人工智能的核心。
1.1.1 大数据分析与机器学习的应用领域
除了在围棋领域,大数据分析在很多别的领域也有很大的应用空间。信息时代,我们每天接触的就是海量的数据,通过人力在这海量的数据中寻找规律有很大的局限性,而通过机器学习的手段来进行大数据分析则可以高效、快速地对数据进行分析并提炼规律。
我们通过下面一张表格来简单介绍下大数据分析与机器学习在8大领域的应用,其中大部分案例我们将在之后的章节中进行实例讲解。
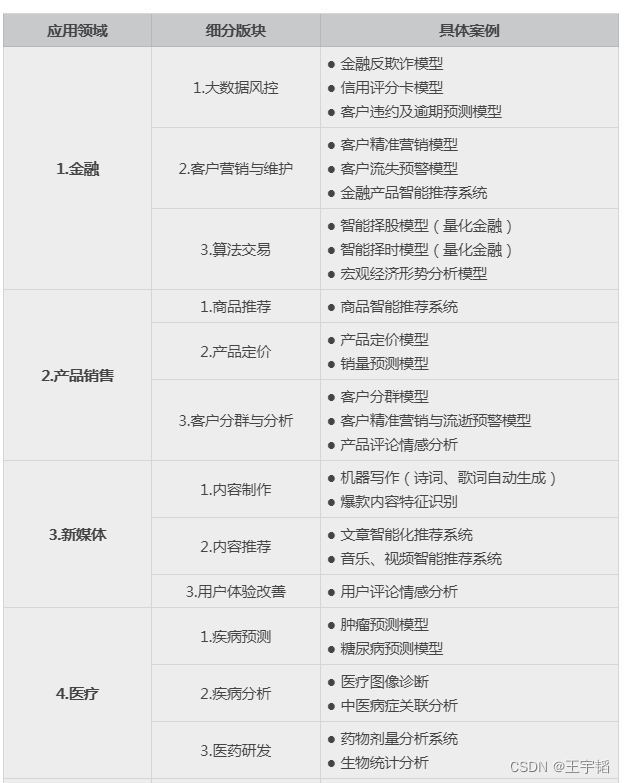
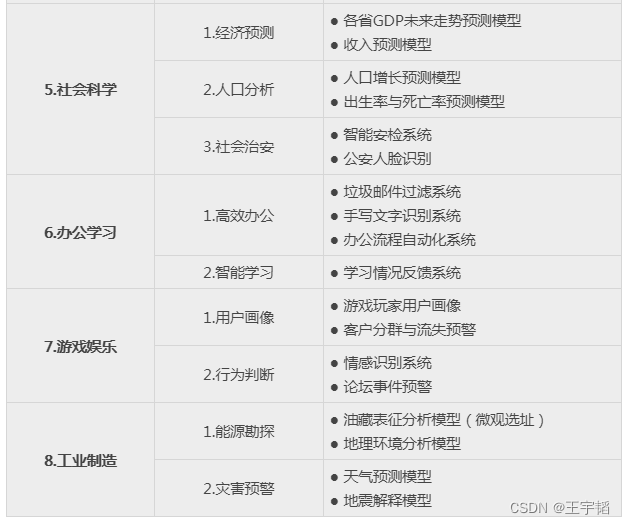
上面的案例只是作为一个展示,在实际应用中,大数据分析与机器学习还有很多应用场景。虽然不同行业的应用场景不同,但是其原理都是想通的,等学习完之后的章节,相信大家会对这些案例有个更加清晰的认知。
1.1.2 机器学习的基本概念
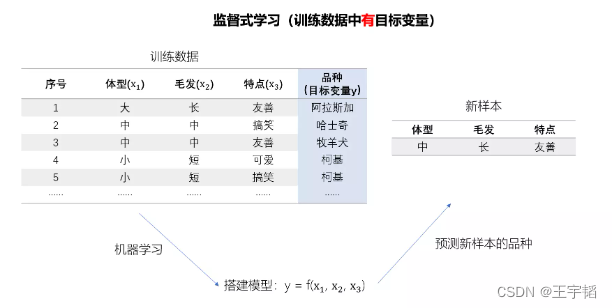
机器学习是大数据分析强有力的工具。机器学习主要分为两大类:监督式学习与非监督式学习,两者的区别就在于训练数据中是否有目标变量,或者称为预测变量。
我们用两张图来解释下两者的区别,其中监督式学习如下图所示,其训练数据中有三个特征变量(体型、毛发、特点)以及一个目标变量(品种),该机器学习的目的就是根据训练数据搭建模型来预测狗的品种。
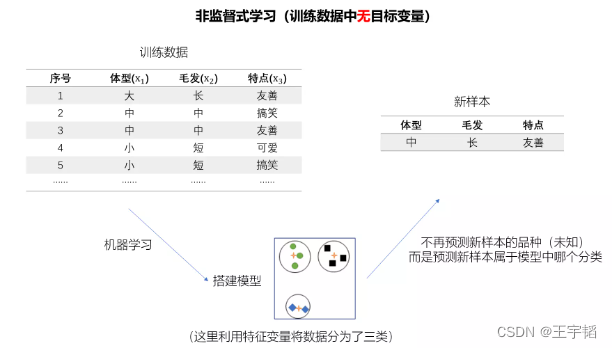
非监督式学习如下图所示,其和监督式学习的主要区别在于:它的训练数据中只有特征变量,而没有目标变量(品种),所以它在进行机器学习的目的不是去预测品种了,以第十三章的聚类模型为例,它可以根据这些特征将训练数据中的狗进行归类,如A类狗、B类狗、C类狗,那么对于一个新样本便可以根据它的特征来判别它属于哪一个分类。
再细分来说,监督式学习主要分为回归分析(Regression)与分类问题(Classification):

而非监督式学习主要分为数据聚类与分群(Clustering)与数据降维(Dimension Reduction):

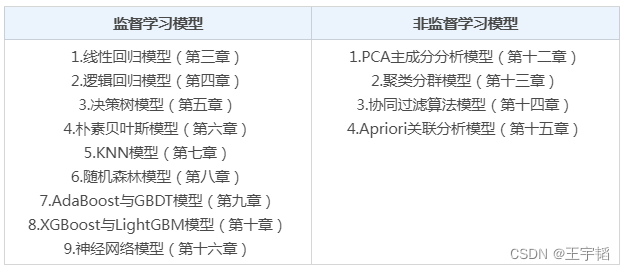
从机器学习模型的角度分类,可以将其分成如下的表格中的不同算法模型,这些不同的模型我们都将在之后的章节进行详细的讲解,并且每一章都会通过上一小节提到的具体实战案例巩固模型的学习,让大家知道模型的原理及其实战应用。
1.1.3 Python在数据科学中的作用
用来做数据分析的工具有很多,如经典的Matlab与R语言,以及目前非常火的Python。Python之所以能够在如今成为大数据分析的主要工具,一个主要的原因就是在Python有很多别人已经写好的数据分析以及机器学习的工具包(学术上叫作“库”),如numpy库、pandas库、Scikit-learn库(简称sklearn库)等工具包,这些库里封装了很多别人已经写好的算法模型,我们只需要直接拿过来调用即可。正是这些工具包方便了大家对数据进行分析而不需要去把精力放在数学表达式的编程构
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 7420
7420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









