




 TCP协议的面向流特性可能导致粘包问题,使得接收方难以区分消息边界。解决方案包括定长包、包尾加换行符、包头携带包体长度和自定义应用层协议。本文介绍了四种方法的优缺点,并提供了一种结构体解包的示例。
TCP协议的面向流特性可能导致粘包问题,使得接收方难以区分消息边界。解决方案包括定长包、包尾加换行符、包头携带包体长度和自定义应用层协议。本文介绍了四种方法的优缺点,并提供了一种结构体解包的示例。
我们在前面曾经说过,发送端可以是一K一K地发送数据,而接收端的应用程序可以两K两K地提走数据,当然也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据,也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。怎样定义消息呢?可以认为对方一次性write/send的数据为一个消息,需要明白的是当对方send一条信息的时候,无论底层怎样分段分片,TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区,所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
一、粘包问题可以用下图来表示:
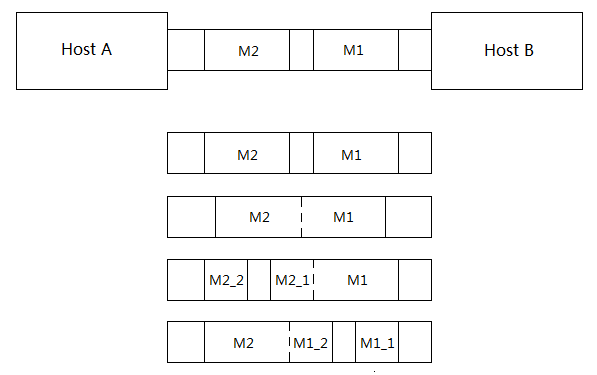
假设主机A send了两条消息M1和M2 各10k 给主机B,由于主机B一次提取的字节数是不确定的,接收方提取数据的情况可能是:
• 一次性提取20k 数据• 分两次提取,第一次5k,第二次15k
• 分两次提取,第一次15k,第二次5k
• 分两次提取,第一次10k,第二次10k
• 分三次提取,第一次6k,第二次8k,第三次6k
• 其他任何可能
二、粘包问题的解决方案
本质上是要在应用层维护消息与消息的边界(下文的“包”可以认为是“消息”)
1、定长包
2、包尾加\r\n(ftp)
3、包头加上包体长度
4、更复杂的应用层协议
对于条目2,缺点是如果消息本身含有\r\n字符,则也分不清消息的边界。
对于条目1,即我们需要发送和接收定长包。因为TCP协议是面向流的,read和write调用的返回值往往小于参数指定的字节数。对于read调用(套接字标志为阻塞),如果接收缓冲区中有20字节,请求读100个字节,就会返回20。对于write调用,如果请求写100个字节,而发送缓冲区中只有20个字节的空闲位置,那么write会阻塞,直到把100个字节全部交给发送缓冲区才返回。为避免这些情况干扰主程序的逻辑,确保读写我们所请求的字节数,我们实现了两个包装函数readn和writen,如下所示。
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









