







 本文详细介绍了机器学习中的提升(Boosting)技术,包括提升的基本概念、梯度提升算法的推导以及XGBoost和Adaboost的原理。文章深入浅出地解释了提升算法如何通过结合多个弱学习器构建强学习器,并以XGBoost为例,探讨了二阶导数在优化过程中的作用。同时,文中还提供了Adaboost算法的推导和案例分析,帮助读者理解提升方法的工作机制。
本文详细介绍了机器学习中的提升(Boosting)技术,包括提升的基本概念、梯度提升算法的推导以及XGBoost和Adaboost的原理。文章深入浅出地解释了提升算法如何通过结合多个弱学习器构建强学习器,并以XGBoost为例,探讨了二阶导数在优化过程中的作用。同时,文中还提供了Adaboost算法的推导和案例分析,帮助读者理解提升方法的工作机制。
王小草【机器学习】笔记–提升
标签(空格分隔): 王小草机器学习笔记
集成学习
集成学习(ensemble learning)是通过构建多个学习器来完成学习任务的。
按照集成中学习器是否是同种类型,可分为:
同质(homogeneous)的集成:集成中只包含同种类型的个体学习器,例如决策树集成全是决策树,神经网络集成全是神经网络。同质集成中的个体学习器称为“基学习器(base leaner)”,学习算法称为“基学习算法(base learning algorithm)”。
异质(heterogenous)的集成:集成中包含不同类型的个体学习器,如同时包含决策树与神经网络。异质集成中的个体学习器称为“组件学习器(component learner)”或“个体学习器”。
按照集成的方式不同,可以分为:
Boosting:将弱学习器提升为强学习器的算法。个体学习器存在强依赖关系,必须串行生成的序列化方法。the model is dependent on the previous model
Bagging: 是并行式即成学习方法著名代表,名字来自于Bootstrap AGGregatING的缩写。个体学习器不存在强依赖关系,可以同时生成的并行化方法,the models are independent for each other。
集成学习可以获得比单一学习器显著优越的泛化性能,尤其是在弱学习器上,因此很多理论研究都针对弱学习器,尽管如此,在实际中,出于为了使用尽量少的个体学习器或其它原因,在较强的学习器上使用集成的方法,也不失为优选。
本笔记主要是针对boosting相关的知识整理。
1 提升(boosting)的概念
提升是机器学习技术,可以用于回归和分类问题。它先从初始训练集训练出一个基学习器;然后根据这个基学习器的表现对训练样本对分布进行调整,使得之前基学习期错的训练样本在之后受到更多关注;接着,基于调整后的样本分布再训练下一个基学习期,如此重复,直到基学习器数目达到设定的阈值;最后,将所有基学习器进行加权求和。(周志华《机器学习》)
也就是说,每次迭代,都会改变训练
即它每一步产生一个弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型生成都是依据损失函数的梯度方向,则称之为梯度提升(Gradient Boosting).
梯度提升算法首先给定一个目标函数,它的定义域是所有可行的弱函数集合(基函数);提升算法通过迭代的选择一个负梯度方向上的基函数来逐渐逼近局部极小值。这种在函数域的梯度提升观点对机器学习的很多领域有深刻影响。
提升的理论意义:如果一个问题存在弱分类器,则可以通过提升的办法得到强分类器。
额。。这串概念是什么鬼,看完如果还不知所云提升是啥玩意儿。先不要急,心乱如麻先看下去。
2.梯度提升算法与推导
2.1 提升算法大致思路
现在用公式来解释一下GB算法的大致思路。
(1)给定输入向量x和输出向量y组成的若干训练样本:
(x1,y1), (x2, y2),(x3, y3)…(xn, yn)
(2)目标是要找出一个近似函数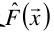 ,使得损失函数L(y, F(x))的损失最小。
,使得损失函数L(y, F(x))的损失最小。
其中损失函数L(y, F(x))的形式有多种,在回归中比较典型为:

y是样本的实际值,F(x)是通过模型F预测出来的预测值,两者的差距就形成了损失。
分类问题中,用对是“对数损失函数”
也就是说,通过损失最小的目标函数,最终会求的一个最优的函数 ,
,

好了,现在已经很明确,我们的目标是去求最优的F(X)函数,它做出的预测与实际的值的差距是最小的,也就是预测是最准的,这当然是我们求之不得的啦。那么怎么去求这个F(X)呢?
它是一个强预测模型,上面的概念里最后一句回答了,弱预测模型可以通过提升的方式变成强预测模型。
(3)所以的所以,我们假定F(x)是一组基函数(弱预测函数)f(xi)的加权和。

γ是每个基函数的权重。
于是问题变成了求取基函数,以及它们对应的权值γ。
其实,与线性回归的y=wx+b的形式很相似,线性回归中我们的目标是求的损失最小时各个特征的权重w,使得预测值y与真实值最接近;同理,GB中是为了得到损失最小时的权重γ(i),与对应的基函数f(i),使得损失最小,即F(x)的预测值与真实值最接近。把线性回归中的x,y换成函数f,F理解即可。
(4)总结
这是要建立的模型:
这是求得模型参数建立得目标函数(损失函数):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









