






一、简介:
采集、收集数据
二、安装
1. 解压
2. 在conf下复制一份flume-conf.properties.template就可以开始玩flume了
三、概念
source:源数据(你从哪里来)
sink:源数据落地点(要到哪里去)
channel:信道,用于连接source和sink(来时的路)
四、几个应用场景介绍
1. 多级agent串联
(1) 场景:为什么要串联?因为我有两台机器,机器a和机器b,a是hdfs集群中的datanode之一,b属于客户,b不能访问hdfs集群(哎!为了安全忍了),因此flume为b到a传输数据架起桥梁。
(2) 串联结构:
机器b(客户机):
source: 配置源数据(我需要接收mysql和oracle数据库的数据)
sink: avro(向a的相应端口发送数据)
channel:内存与磁盘混合模式
机器a(datanode):
source: avro(接受b发来的数据,注意,端口要与a发来时的端口相同,理由嘛,你懂得)
sink:hdfs(到达hdfs集群的怀抱)
channel:内存(集群里的机器配置好,直接上内存)
(3) 客户机b的配置:
#起名字
agent.channels = ch1
agent.sinks = k1
agent.sources = sql-source
#channels配置:使用内存和磁盘混合
agent.channels.ch1.type = SPILLABLEMEMORY
agent.channels.ch1.byteCapacity = 80000
agent.channels.ch1.checkpointDir = /xxx /flume_check
agent.channels.ch1.dataDirs=/xxx/flume_data
#sources配置:mysql,注意,只要是“你的”都要修改哦
agent.sources.sql-source.channels = ch1
#flume-ng-sql提供的的type
# agent.sources.sql-source.type = org.keedio.flume.source.SQLSource
#我自己扩展的type
agent.sources.sql-source.type = org.keedio.flume.source.SQLSourceExt
agent.sources.sql-source.hibernate.connection.url = jdbc:mysql://你的ip:3306/你的数据库
agent.sources.sql-source.hibernate.connection.user = 你的用户名
agent.sources.sql-source.hibernate.connection.password = 你的密码
agent.sources.sql-source.hibernate.dialect =org.hibernate.dialect.MySQLInnoDBDialect
agent.sources.sql-source.table = 你的表
#这两个参数也是我扩展的,请在使用SQLSourceExt的时候配置,否则不需要这两只
agent.sources.sql-source.header = true
agent.sources.sql-source.headerKey = 你的表
agent.sources.sql-source.batch.size = 5000
agent.sources.sql-source.max.rows = 1000
agent.sources.sql-source.start.from = 你的增量字段的开始值
#这个是自定义sql,如果你不需要那就使用下面那条,直接*
agent.sources.sql-source.custom.query = select ID AS INCREMENTALfrom 你的table WHERE INCREMENTAL > $@$ ORDER BY INCREMENTAL ASC
#agent.sources.sql-source.columns.to.select = *
agent.sources.sql-source.run.query.delay=5000
agent.sources.sql-source.status.file.path = /xxx/flume_file
agent.sources.sql-source.status.file.name = sql-source.status
#官方说生产环境最好配着,我是听话的好孩子
agent.sources.sql-source.hibernate.connection.provider_class =org.hibernate.connection.C3P0ConnectionProvider
agent.sources.sql-source.hibernate.c3p0.min_size=1
agent.sources.sql-source.hibernate.c3p0.max_size=10
#sink:数据要暂时尘埃落定,然后飞向另一端
agent.sinks.k1.channel = ch1
agent.sinks.k1.type = avro
agent.sinks.k1.hostname = a机器的ip(使用a的外网ip,当然基于以上场景只能用外网ip)
agent.sinks.k1.port = 44444(这个你随意,另一端不占用就行)
(4) 注意:
基于以上配置,再多费几句话:
第一: source的type,SQLSource是keedio/flume-ng-sql-source中给的type,如果你没有特殊要求,官方的就好用,但是我想把表名也发给机器a,让a知道来的数据是哪个表的,因此我基于flume-ng-sql-source进行了扩展,扩展后的类型为org.keedio.flume.source.SQLSourceExt,并且增加了header和headerKey,这两个主要是为了将表名带给a用的,如果你只使用SQLSource为type,那么不需要这两个配置。
第二:custom.query自定义sql:字段尽量转义,例如`name`,避免不必要的报错。
第三:/xxx /:这种目录都要授权给flume账户,chown和chgrp。
第四:如果使用cdh管理flume,那么flume_check和flume_data的目录不要创建在root下,否则cdh没有权限无法识别,我创建在了/var/local下
(5) 重要参考
看了很多资料,不能一一列举,挑了最重要的几个:
官方:
flume-sql:
https://github.com/keedio/flume-ng-sql-source
flume-oralce:
http://blog.csdn.net/chongxin1/article/details/77937686
多级agent:
http://blog.csdn.net/panguoyuan/article/details/39963973
flume扩展(非常有参考性):
http://blog.csdn.net/xiao_jun_0820/article/details/38333171
flume架构(虽然我问了他问题他没回复我):
http://blog.csdn.net/lifuxiangcaohui/article/details/51733726
(6) 扩展:
为了将数据表的表名传输给另一端,我使用了较为low的方法,把表名塞到了传输数据的body中,有点污染数据,目前我还没想到更好的馊主意,如果有更好的方法,请马上告诉我!
其中需要注意的,flume-ng-sql是读取每一条记录然后将其放到event的body中,如果大小超过了batchsize,那么超过的内容将放在下一个event中,因此,我的这个方案可能会出现表名被截掉的可能,现阶段我仅仅把batchsize设置的大一些防止这种情况,后续还是要考虑别的方式。
修改源码:
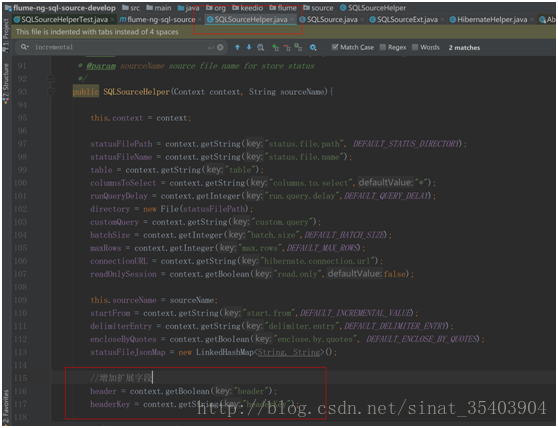
第一:在SQLSourceHelper中添加了两个成员变量,用来接收用户指定的表名或其他信息,供后续拦截器进行拦截,代码如下图所示。
第二:自定义SQLSourceExt,代码基本上采用SQLSource,只修改了下面这个方法
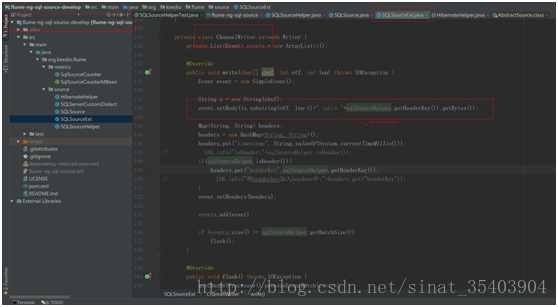
private classChannelWriter extends Writer {
private List<Event> events = newArrayList<>();
@Override
public void write(char[] cbuf, int off,int len) throws IOException {
Event event = new SimpleEvent();
String s = new String(cbuf);
//将.table.表名拼接到内容中
event.setBody((s.substring(off,len-1)+".table."+sqlSourceHelper.getHeaderKey()).getBytes());
Map<String, String> headers;
headers = new HashMap<String,String>();
headers.put("timestamp",String.valueOf(System.currentTimeMillis()));
// LOG.info("isHeader:"+sqlSourceHelper.isHeader());
if(sqlSourceHelper.isHeader()){
headers.put("headerKey",sqlSourceHelper.getHeaderKey());
// LOG.info("将headerkey加入headers中:"+headers.get("headerKey"));
}
event.setHeaders(headers);
events.add(event);
if (events.size() >=sqlSourceHelper.getBatchSize())
flush();
}
@Override
public void flush() throws IOException{
getChannelProcessor().processEventBatch(events);
events.clear();
}
@Override
public void close() throws IOException{
flush();
}
}
(7) 机器a配置(多source,终点到达hdfs):
tier1.sources = r1 r2
tier1.sinks = k1 k2
tier1.channels = c1 c2
#channel配置信息
#type为memory意将数据存储至内存中
tier1.channels.c1.type = memory
tier1.channels.c1.capacity = 1000
tier1.channels.c1.transactionCapacity = 100
#source配置信息
# 绑定source r1的绑定监听主机和端口
tier1.sources.r1.channels = c1
tier1.sources.r1.type = avro
tier1.sources.r1.bind =ip
tier1.sources.r1.port = 44444
tier1.sources.r1.interceptors = i1 i2
tier1.sources.r1.interceptors.i1.type = timestamp
tier1.sources.r1.interceptors.i2.type=regex_extractor
tier1.sources.r1.interceptors.i2.regex = (.*)\\.table\\.(.*)
tier1.sources.r1.interceptors.i2.serializers = s1 s2
tier1.sources.r1.interceptors.i2.serializers.s1.name = one
tier1.sources.r1.interceptors.i2.serializers.s2.name = two
#tier1.sources.r1.interceptors.i2.serializers.s3.name = three
tier1.sinks.k1.channel = c1
tier1.sinks.k1.type = hdfs
tier1.sinks.k1.hdfs.path = hdfs://ip/xxx/input/%y-%m-%d
#文件前缀
tier1.sinks.k1.hdfs.filePrefix=%{two}
tier1.sinks.k1.hdfs.fileType = DataStream
tier1.sinks.k1.hdfs.writeFormat = Text
tier1.sinks.k1.hdfs.rollSize = 131072000
tier1.sinks.k1.hdfs.rollInterval = 0
tier1.sinks.k1.hdfs.rollCount = 0
tier1.sinks.k1.hdfs.callTimeout = 300000
# 持续60分钟没动作分割
tier1.sinks.k1.hdfs.idleTimeout = 3600
tier1.channels.c2.type = memory
tier1.channels.c2.capacity = 1000
tier1.channels.c2.transactionCapacity = 100
# 接受数据表
#source配置信息
# 绑定source r1的绑定监听主机和端口
tier1.sources.r2.channels = c2
tier1.sources.r2.type = avro
tier1.sources.r2.bind = ip
tier1.sources.r2.port = 44445
tier1.sources.r2.interceptors = i1 i2
tier1.sources.r2.interceptors.i1.type = timestamp
tier1.sources.r2.interceptors.i2.type=regex_extractor
tier1.sources.r2.interceptors.i2.regex = (.*)\\.(.*)\\.(.*)
tier1.sources.r2.interceptors.i2.serializers = s1 s2 s3
tier1.sources.r2.interceptors.i2.serializers.s1.name = one
tier1.sources.r2.interceptors.i2.serializers.s2.name = two
tier1.sources.r2.interceptors.i2.serializers.s3.name = three
tier1.sinks.k2.channel = c2
tier1.sinks.k2.type = hdfs
tier1.sinks.k2.hdfs.path = hdfs://ip/xxx/input/%y-%m-%d
tier1.sinks.k2.hdfs.filePrefix=%{three}
tier1.sinks.k2.hdfs.fileType = DataStream
tier1.sinks.k2.hdfs.writeFormat = Text
tier1.sinks.k2.hdfs.rollSize = 131072000
tier1.sinks.k2.hdfs.rollInterval = 0
tier1.sinks.k2.hdfs.rollCount = 0
tier1.sinks.k2.hdfs.callTimeout = 300000
# 持续60分钟没动作分割
tier1.sinks.k2.hdfs.idleTimeout = 3600
下面是附赠的几个小栗子
2. 从oracle抽取数据到avro:
agent.channels= ch1
agent.sinks= k1
agent.sources= sql-source
agent.channels.ch1.type= file
agent.channels.ch1.checkpointDir=/xxx/flume_check
agent.channels.ch1.dataDirs=/xxx/flume_data
#agent.channels.ch1.type= memory
agent.channels.ch1.capacity= 10000
agent.channels.ch1.transactionCapacity= 30
#agent.channels.ch1.byteCapacityBufferPercentage= 20
#agent.channels.ch1.byteCapacity= 1600000
agent.sources.sql-source.channels= ch1
agent.sources.sql-source.type= org.keedio.flume.source.SQLSource
agent.sources.sql-source.hibernate.connection.url= jdbc:oracle:thin:@ip:1521/orcl
agent.sources.sql-source.hibernate.connection.user= 用户名
agent.sources.sql-source.hibernate.connection.password= 密码
agent.sources.sql-source.table= 表名
agent.sources.sql-source.columns.to.select= *
agent.sources.sql-source.incremental.column.name= id
agent.sources.sql-source.incremental.value= 0
agent.sources.sql-source.run.query.delay=10000
agent.sources.sql-source.status.file.path= /xxx/flume_file
agent.sources.sql-source.status.file.name= sql-source.status
agent.sources.sql-source.hibernate.dialect= org.hibernate.dialect.Oracle10gDialect
agent.sources.sql-source.hibernate.connection.driver_class= oracle.jdbc.driver.OracleDriver
agent.sources.sql-source.batch.size= 1000
agent.sources.sql-source.max.rows= 1000
agent.sources.sql-source.hibernate.connection.provider_class= org.hibernate.connection.C3P0ConnectionProvider
agent.sources.sql-source.hibernate.c3p0.min_size=1
agent.sources.sql-source.hibernate.c3p0.max_size=10
agent.sources.sql-source.maxBackoffSleep=10000
agent.sinks.k1.channel= ch1
agent.sinks.k1.type= avro
agent.sinks.k1.hostname= ip
agent.sinks.k1.port = 44445
3. 从mysql到kafka:
agent.channels.ch1.type= memory
agent.sources.sql-source.channels= ch1
agent.channels= ch1
agent.sinks= k1
agent.sources= sql-source
agent.sources.sql-source.type= org.keedio.flume.source.SQLSource
agent.sources.sql-source.connection.url= jdbc:mysql://ip:3306/数据库
agent.sources.sql-source.user= 账号
agent.sources.sql-source.password= 密码
agent.sources.sql-source.table= 表
agent.sources.sql-source.columns.to.select= *
agent.sources.sql-source.incremental.column.name= id
agent.sources.sql-source.incremental.value= -1
agent.sources.sql-source.run.query.delay=5000
agent.sources.sql-source.status.file.path= /xxx/flume_file
agent.sources.sql-source.status.file.name= sql-source.status
agent.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k1.kafka.topic= 主题
agent.sinks.k1.kafka.bootstrap.servers= ip:9092
agent.sinks.k1.kafka.flumeBatchSize= 20
agent.sinks.k1.kafka.producer.acks= 1
agent.sinks.k1.kafka.producer.linger.ms= 1
agent.sinks.k1.kafka.producer.compression.type= snappy
agent.sinks.k1.channel = ch1
4. 从文件到hdfs:
这个例子使用了http://blog.csdn.net/xiao_jun_0820/article/details/38333171博客中实现的拦截器,我按照他的方式重做了一遍,可以自己动手做一个当练手。
agent.channels = ch1
agent.sinks = k1
agent.sources = r1
#channel:内存与磁盘混合模式
agent.channels.ch1.type = SPILLABLEMEMORY
agent.channels.ch1.memoryCapacity = 5000
agent.channels.ch1.byteCapacity = 8000
agent.channels.ch1.checkpointDir = /root/zhx_all/flume_check
agent.channels.ch1.dataDirs=/root/zhx_all/flume_data
#source:dir
agent.sources.r1.channels = ch1
agent.sources.r1.type = spooldir
agent.sources.r1.channels = ch1
agent.sources.r1.spoolDir = /root/zhx_all/test_file
agent.sources.r1.fileHeader = true
agent.sources.r1.basenameHeader = true
#interceptor:时间和正则拦截器,正则用于拦截文件名
agent.sources.r1.interceptors = i1 i2
agent.sources.r1.interceptors.i1.type = timestamp
agent.sources.r1.interceptors.i2.type= xxx.RegexExtractorExtInterceptor$Builder
agent.sources.r1.interceptors.i2.regex=(.*)\\.(.*)
agent.sources.r1.interceptors.i2.extractorHeader=true
agent.sources.r1.interceptors.i2.extractorHeaderKey=basename
agent.sources.r1.interceptors.i2.serializers=s1 s2
agent.sources.r1.interceptors.i2.serializers.s1.name=one
agent.sources.r1.interceptors.i2.serializers.s2.name=two
#sink:到达hdfs
agent.sinks.k1.channel = ch1
agent.sinks.k1.type = hdfs
agent.sinks.k1.hdfs.path = hdfs://xxx/input/%y-%m-%d
agent.sinks.k1.hdfs.filePrefix=%{one}
agent.sinks.k1.hdfs.fileType = DataStream
agent.sinks.k1.hdfs.writeFormat = Text
agent.sinks.k1.hdfs.rollSize = 131072000
agent.sinks.k1.hdfs.rollInterval = 0
agent.sinks.k1.hdfs.rollCount = 0
agent.sinks.k1.hdfs.callTimeout = 300000
# 持续60分钟没动作分割
agent.sinks.k1.hdfs.idleTimeout = 3600
感觉写的有点乱,后续再修修补补吧!期待提出宝贵意见!














 233
233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









