







问题:ERROR ActorSystemImpl: Uncaught fatal error from thread [sparkDriver-akka.remote.default-remote-dispatcher-8] shutting down ActorSystem [sparkDriver]
15/07/28 13:46:59 ERROR ActorSystemImpl: Uncaught fatal error from thread [sparkDriver-akka.remote.default-remote-dispatcher-8] shutting down ActorSystem [sparkDriver]
java.lang.OutOfMemoryError: Java heap space
at org.spark_project.protobuf.ByteString.toByteArray(ByteString.java:515)
at akka.remote.serialization.MessageContainerSerializer.fromBinary(MessageContainerSerializer.scala:64)
at akka.serialization.Serialization$$anonfun$deserialize$1.apply(Serialization.scala:104)
at scala.util.Try$.apply(Try.scala:161)
at akka.serialization.Serialization.deserialize(Serialization.scala:98)
at akka.remote.MessageSerializer$.deserialize(MessageSerializer.scala:23)
at akka.remote.DefaultMessageDispatcher.payload$lzycompute$1(Endpoint.scala:58)
at akka.remote.DefaultMessageDispatcher.payload$1(Endpoint.scala:58)
at akka.remote.DefaultMessageDispatcher.dispatch(Endpoint.scala:76)
at akka.remote.EndpointReader$$anonfun$receive$2.applyOrElse(Endpoint.scala:937)
at akka.actor.Actor$class.aroundReceive(Actor.scala:465)
at akka.remote.EndpointActor.aroundReceive(Endpoint.scala:415)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:516)
at akka.actor.ActorCell.invoke(ActorCell.scala:487)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:238)
at akka.dispatch.Mailbox.run(Mailbox.scala:220)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:393)
at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
由于集群较小,只有4台机器,在其中master上面提交了任务,结果出现上述异常。即driver 内存不足,因此使用spark-sumbit脚本时,提供–executor-memory –driver-memory选项,来相应的设置内存。
问题:空指针异常
导致这个问题的原因有很多,和spark本身相关的主要有两种情况:
- 嵌套使用了RDD操作,比如在一个RDD map中又对另一个RDD进行了map操作。主要原因在于spark不支持RDD的嵌套操作。
- 在RDD操作中引用了object非原始类型(非int long等简单类型)的成员变量。貌似是由于object的成员变量默认是无法序列化的。解决方法:可以先将成员变量赋值给一个临时变量,然后使用该临时变量即可
调整分区数的重要性
刚开始运行的时候,默认分区数为2,结果在集群上面运行的时间甚至比本地都慢。通过Web UI查看任务状态,如下图:
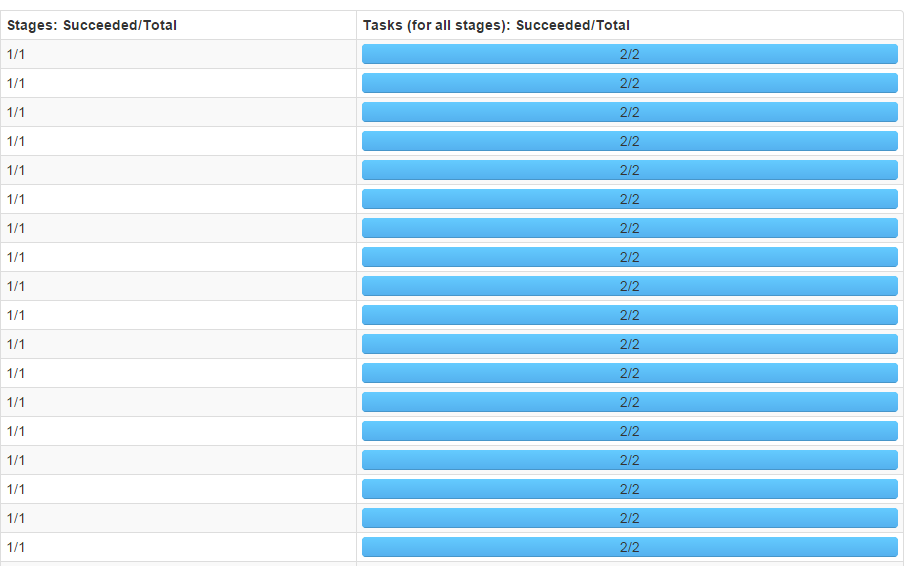
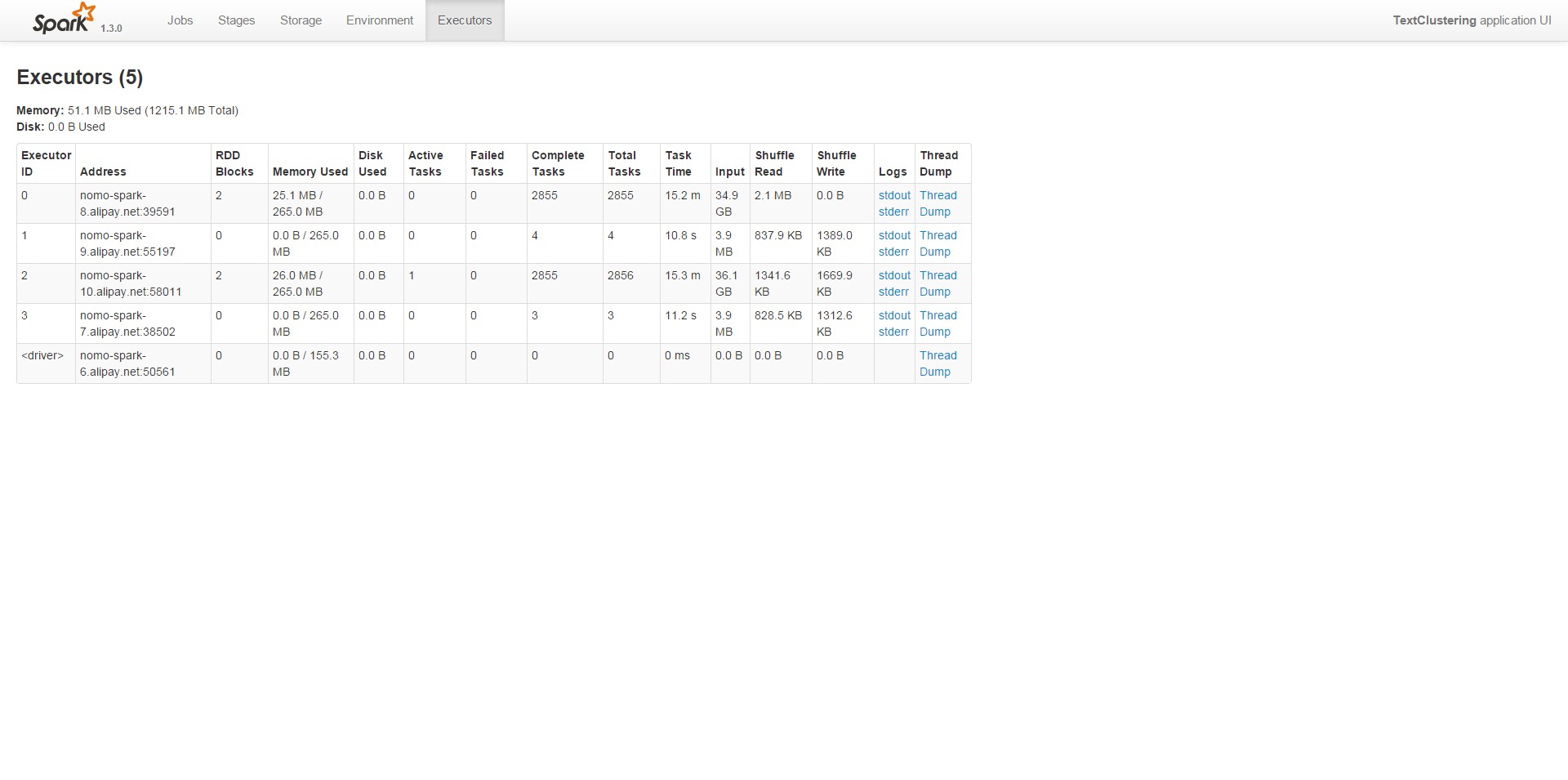
可以看到每个stage只有2个task,4个executor实际上只有两个参与了运算,并行度真是够低的。
调整方式:在用textFile函数读取文件的时候指定分区数,由于集群中有4个executor,而分区数最好是executor数量的整数倍,因此将分区数指定为8,调整后,结果如下所示:
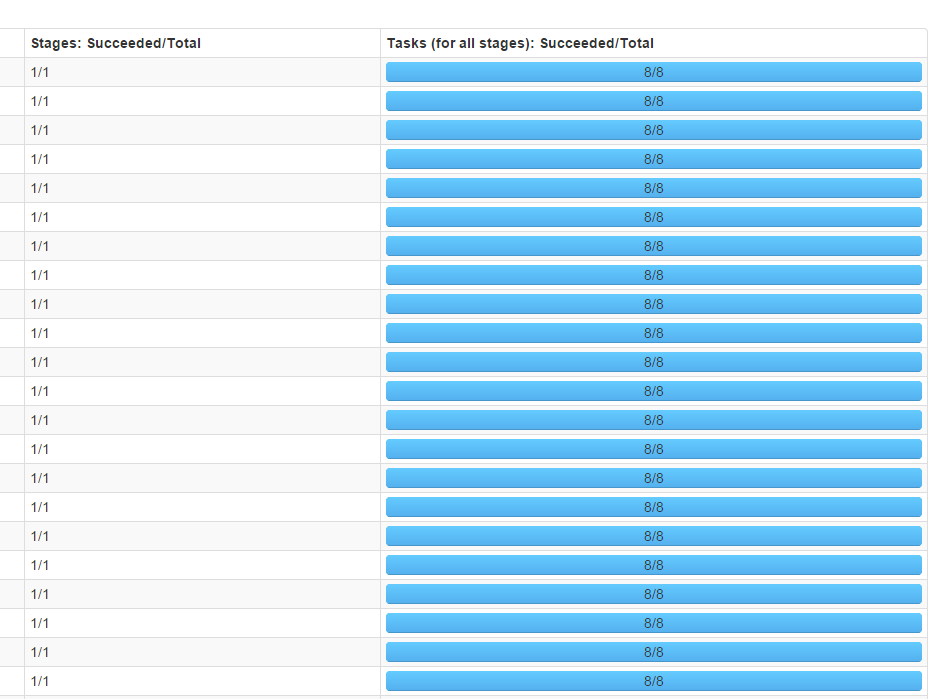
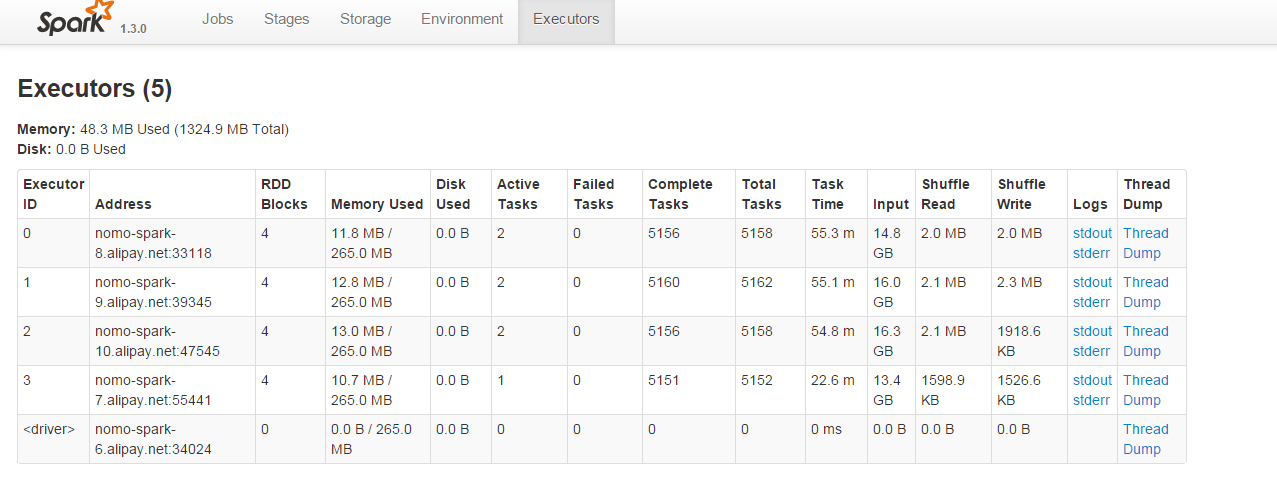
可见4个executor都参与了运算,并行度有了显著提升。















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









