







最近在复习《数据结构与算法》方面的知识,但是绝大多数数据结构的书籍都是以伪代码/类C语言的形式来描述算法的,当然也有少数C语言的版本。但是在C语言的算法描述中,由于C语言没有像C++一样的引用变量,因此出现了所谓的“二级指针”,很多C语言和数据结构的小白们对此不解;再者有的教材中(比如清华版严蔚敏的《数据结构》)用了类C的伪代码来描述数据结构和算法,为了描述的方面,引入了C++的引用变量,但是有的同学在学数据结构的时候还没有学习C++程序设计语言,对引用感到陌生,因此我想在此详细解释一下。
数据结构中的二级指针
指针概述
我们知道,C/C++中的指针变量也是一种变量,因此指针变量本身也是有地址的。不过这种变量比较特殊—只能用来保存一些变量/内存块的地址值,例如:
int *pt;上面定义了一个int型的指针变量pt,该变量pt的内存单元可以用来保存一个int型变量的地址,或者说让pt指向变量a,比如
int a = 2017;
pt = &a;可以用下图1来表示这种关系:

如果需要用一个“变量”来保存指针变量pt的地址&pt,由于pt是一个指针变量,因此必须定义一个二级指针来保存pt的地址,例如:
int **spt = &pt;可以用图2来表示这种关系。在需要用到变量a时,可以用指针来访问a的内存单元中的数据“2017”,即*pt或者**spt,当然绝大多数情况下可以直接使用变量名a来直接访问。通过下面的程序来说明指针变量的存储。
#include <stdio.h>
int main(int argc, const char * argv[]) {
int a = 2017;
int *pt = &a;
int **spt = &pt;
printf("a变量的内存单元的地址为:%p\n", &a);
printf("pt变量的内存单元的地址为:%p\n", &pt);
printf("spt变量的内存单元的地址为:%p\n", &spt);
printf("a变量的内存单元保存的数据为:%d\n", a);
printf("pt指针变量的内存单元保存的数据为:0x%lx\n", pt);
printf("spt指针变量的内存单元保存的数据为:0x%lx\n", spt);
return 0;
}输出为:(编译平台为XCode7.2.1)
a变量的内存单元的地址为:0x7fff5fbff84c
pt变量的内存单元的地址为:0x7fff5fbff840
spt变量的内存单元的地址为:0x7fff5fbff838
a变量的内存单元保存的数据为:2017
pt指针变量的内存单元保存的数据为:0x7fff5fbff84c
spt指针变量的内存单元保存的数据为:0x7fff5fbff840根据上面的输出结果,可以画出图3的内存单元存储示意图。
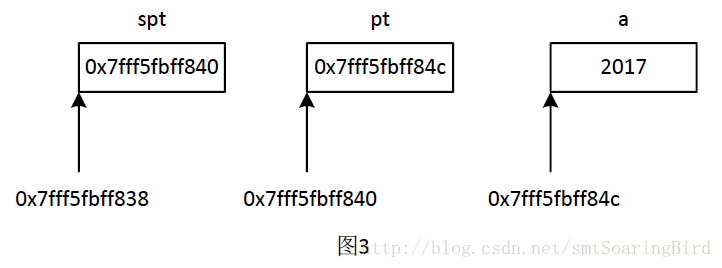
可以看出(指针)变量的内存单元和该内存单元中保存的数据为:
| (指针)变量名 | 该变量的内存单元地址 | 内存单元中保存的数据 |
|---|---|---|
| spt | 0x7fff5fbff838 | 0x7fff5fbff840 |
| pt | 0x7fff5fbff840 | 0x7fff5fbff84c |
| a | 0x7fff5fbff84c | 2017 |
可以看出spt的内存单元中保存的数据0x7fff5fbff840,该数据实质上就是pt变量内存单元的地址;pt的内存单元中保存的数据0x7fff5fbff84c,该数据实质上就是a变量内存单元的地址;也就是通过这种方式形成了图2所示的变量的内存单元之间的逻辑结构!!!
数据结构中的二级指针
在线性表的链式表示中,如果用C语言来实现该算法,不可避免的需要用到二级指针。比如像下面的实现。(详细实现过程可见http://blog.csdn.net/smtsoaringbird/article/details/53999999)
// ----------线性表的单链表存储结构----------
typedef struct LNode {
ElemType data;
struct LNode *next;
}LNode, *LinkList;
// -------------线性表的初始化-------------
Status InitList_L(LinkList *L) {
*L = (LinkList)malloc(sizeof(LNode)); // 生成头结点,并使*L指向它
if (!(*L)) return ERROR; // 存储分配失败
(*L)->next = NULL; // 使头结点的指针域置空
return OK;
}
// -------------线性表的插入-------------
Status ListInsert_L(LinkList *L, int i, ElemType e) {
// 在带头结点的单链线性表L中第i个位置之前插入元素e
int j;
LinkList p, s;
p = *L; // p指向头结点
j = 0;
while (p && j < i - 1) { // 寻找第i-1个结点
p = p->next;
++j;
}
if (!p || j > i - 1) return ERROR; // i小于1或者大于表长+1
s = (LinkList)malloc(sizeof(LNode)); // 生成新结点
s->data = e; // 给新生成的结点赋值
s->next = p->next; // 把新生成的结点s插入到L中
p->next = s;
return OK;
}
// 详细实现过程可见[http://blog.csdn.net/smtsoaringbird/article/details/53999999]在上面的程序块中我们看到了线性表的初始化和插入操作都用到了二级指针的形参LinkList *L(由于LinkList本身被声明为:LNode *型,即LinkList声明的变量本身就是一个一级指针)。为什么需要这么做呢?? 假如我们在main函数中这样写:
// 创建单链表的头指针
LinkList list;
InitList_L(&list);首先我们先声明一个一级指针变量list。程序在调用InitList_L(&list);时,会为形参L 开辟相应的内存单元;然后执行赋值语句L = &list;,也就是让形参L的内存单元保存实参list的地址,即使形参L指向list。此时的内存示意图如图4所示。
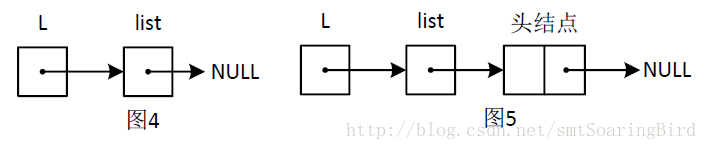
然后进入到InitList函数的函数体中执行
*L = (LinkList)malloc(sizeof(LNode)); // 生成头结点,并使*L指向它由于形参L已经指向了list变量,因此*L就代表list指针变量,所以上述代码相当于创建一个LNode的结点,然后让list指针变量保存该结点的内存地址。如果创建该结点时内存分配成功,那么就将该结点的指针域置空,即下述代码:
(*L)->next = NULL; // 使头结点的指针域置空完成上述语句后的内存示意图如图5所示。该函数调用完毕后,释放在该函数内创建的临时变量L,此时的内存示意图如图6所示。
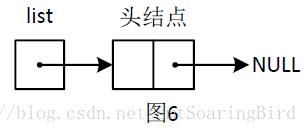
关于其他函数中用到的二级指针作为形参传递的知识可以参考上述的讲解!!
数据结构中的引用
C++中的引用说白了就是给已经定义的变量取一个别名,在使用该变量的时候既可以用该变量本身,也可以使用该变量的引用。不过引用的主要用途是用作函数的形参,把引用变量用作参数,函数将使用原始数据,而不是其副本(普通的参数传递使用的是原始数据的副本)。
创建引用变量
C/C++使用“&”来指示变量的地址,不过C++给“&”符号赋予了另一个含义,将其用来声明引用。例如,如果要把airplane作为aircraft的别名,可以这样做:
int aircraft;
int &airplane = aircraft;在这里的&不是取地址运算符,而是类型标识符的一部分。就像声明cher *指的是指向char的指针一样,int &指的是指向int的引用。上述引用允许将aircraft和airplane互换,他们指向相同的值和内存单元。
#include <iostream>
#include <stdio.h>
typedef struct Point {
int x;
int y;
}Point;
void add(Point &p) {
//p.x += 1;
//p.y += 1;
p.x = p.x + 1;
p.y = p.y + 1;
}
int main() {
Point p1 = {320, 480};
Point &p2 = p1; // p2是p1的引用
printf("p1.x = %d, p1.y = %d\n", p1.x, p1.y);
printf("p2.x = %d, p2.y = %d\n", p2.x, p2.y);
printf("p1's address: %p\n", &p1);
printf("p2's address: %p\n", &p2);
add(p1);
printf("Now, \np1.x = %d, p1.y = %d\n", p1.x, p1.y);
printf("p2.x = %d, p2.y = %d\n", p1.x, p1.y);
return 0;
}上面程序的输出为:(XCode7.2.1编译)
p1.x = 320, p1.y = 480
p2.x = 320, p2.y = 480
p1's address: 0x7fff5fbff850
p2's address: 0x7fff5fbff850
Now,
p1.x = 321, p1.y = 481
p2.x = 321, p2.y = 481从输出结果可以看出,p1和p2的值和地址都是相同的,说明它们确实指向的是同一个内存单元。
将引用用作函数参数
引用经常被用作函数参数,使得函数中的变量名成为调用程序中的变量的别名,这种传递函数的方法称为按引用传递。C++新增的这项特性是对C语言的超越,C语言只能按值传递。按值传递导致被调用函数使用调用程序的值得副本。
我们回到刚才的程序中,该程序中定义了一个void add(Point &p);函数,该函数的形参是一个引用参数,当执行add(p1);时,那么该函数的形参p就成为了实参p1的引用,因此在add函数的函数体内,对p执行什么样的运算,就相当于对p1执行什么样的运算。
比如在线性表的链式存储中,有以下代码块
// ----------线性表的单链表存储结构----------
typedef struct LNode {
ElemType data;
struct LNode *next;
}LNode, *LinkList;
Status InitList_L(LinkList &L);
Status ListInsert_L(LinkList &L, int i, ElemType e);其中的初始化函数InitList_L和插入函数ListInsert_L都有一个引用形参L,当在程序中调用这两个函数时,如下面的程序段所示:
LinkList list;
InitList_L(list);
ListInsert_L(list, 1, 100);形参L就成了实参list的引用,在上面两个函数的函数体内,对形参L的运算/操作,实质上就是对实参list的操作。
总结
总体而言,在进行数据结构和算法的描述中,使用C++的引用参数比完全用C中的二级指针方便很多,对于不懂C++的初学者来说,不需要太大的学习成本就可以掌握引用。不过采用C语言描述的算法对于训练我们更好的理解指针的本质。














 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









