







🦄个人主页:修修修也
🎏所属专栏:数据结构
⚙️操作环境:Visual Studio 2022
(注:为方便演示本篇使用的x86系统,因此指针的大小为4个字节)

目录
相信大家在初学链表时一定被下面这些函数的二级指针搞得晕头转向的,疑惑包括但不限于:
- 什么是二级指针?
- 为什么链表要用到二级指针?
- 为什么同样是链表的函数,有的要用二级指针而有的只要用一级指针?
- 为什么同样是链表,有的链表中使用了二级指针?而有的链表却只需要使用一级指针?

要搞清上面这些问题,我们就要先搞清楚二级指针在链表中的作用到底是什么,接下来我将带大家一起探究二级指针的"前世今生".
📌形参的改变不影响实参!
1.调用函数更改整型时传值调用与传址调用的区别
🎏传值调用
如下代码,我们在主函数创建了一个变量a,并给其赋值为5.然后我们通过传值调用函数test1,在函数内部将a的值改为10.并在过程中打印出a的值:
void test1(int a)
{
a = 10;
printf("调用函数时a=%d\n", a);
}
int main()
{
int a = 5;
printf("没有调用函数前a=%d\n", a);
test1(a);
printf("调用函数后a=%d\n", a);
return 0;
}在编译器中查看运行结果:
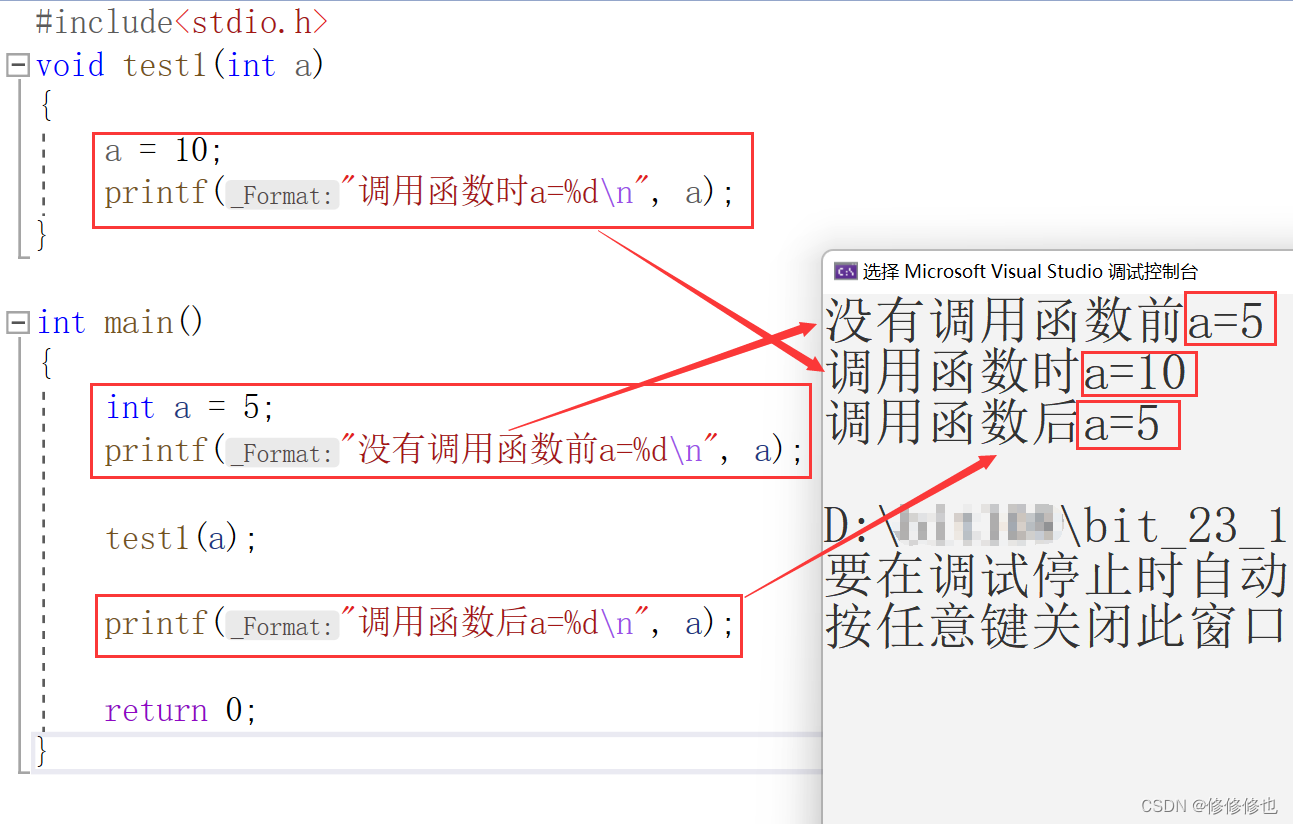
可以看到,传值调用虽然在函数调用时将a的值改为了10,但是一旦出了函数之后a的值是完全没有改变的.
因此:形参的改变不影响实参!
形参的改变不影响实参!
形参的改变不影响实参!
🎏传址调用
如下代码,我们在主函数创建了一个变量a,并给其赋值为5.还创建了一个整型指针pa记录下了变量a的地址.然后我们通过传址调用函数test2,在函数内部使用指针将a的值改为10.并在过程中打印出a的值:
void test2(int *pa)
{
*pa = 10;
printf("调用函数时a=%d\n", *pa);
}
int main()
{
int a = 5;
int* pa = &a;
printf("没有调用函数前a=%d\n", a);
test2(pa);
printf("调用函数后a=%d\n", a);
return 0;
}在编译器中查看运行结果:
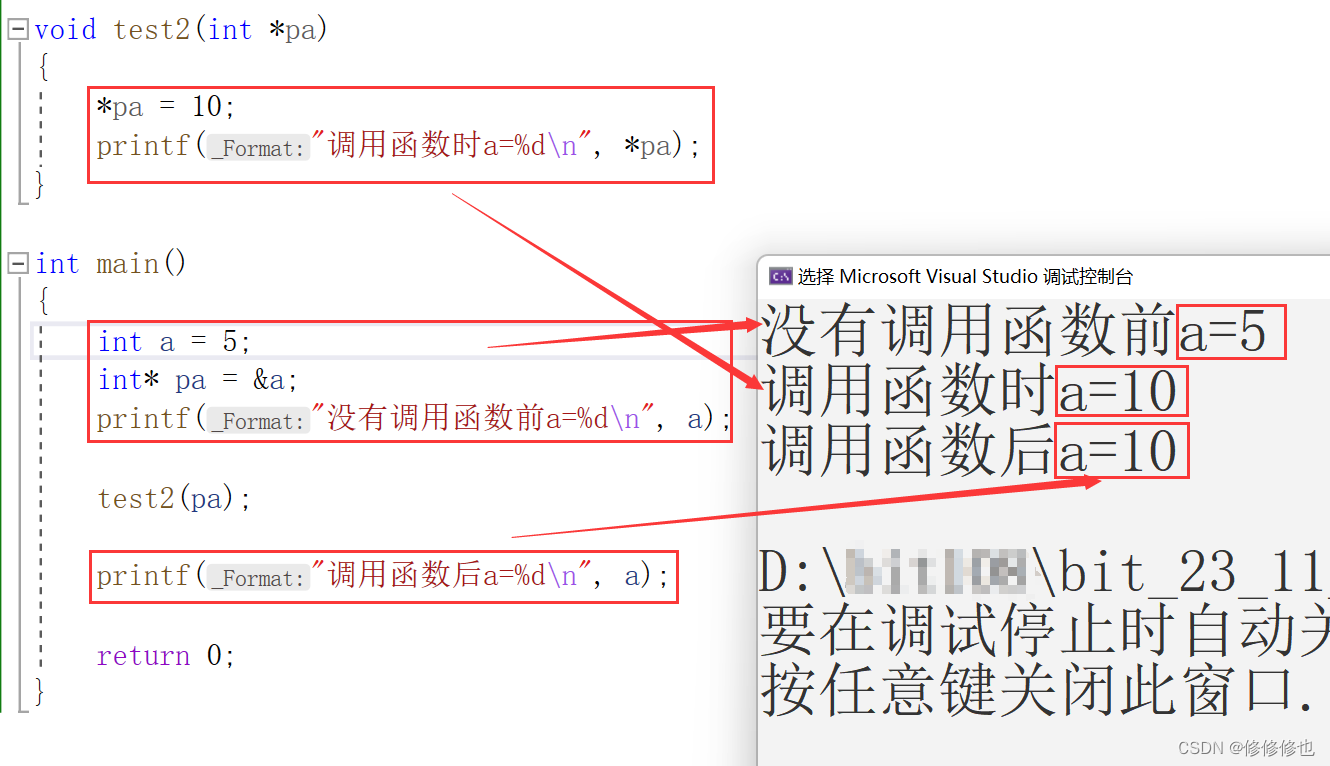
可以看到,传址调用的函数在内部修改a的值,出了函数依然是有效的.
这有些像快递送货上门时,如果按照人名派送快递,可能在这个小区有3个人都叫"张伟",这时派送给哪个"张伟"都有可能派送错,但是如果按照他下单时填写的地址派送快递,那就绝对不会出错,名字可能出错,但地址一定是唯一的.
传值调用和传址调用不同的核心原理:函数会对形参和中间变量重新分配空间
2.调用函数更改指针的指向时传值调用和传址调用的区别
那么是否我们要改变形参时都传指针就一劳永逸了呢?再来看个例子:
🎏传值调用
如下代码,我们在主函数创建了两个变量a和b,并给其赋值为5和10.还创建了两个整型指针pa和pb分别记录下了变量a和b的地址.然后我们通过传值调用函数test3,在函数内部将pb的值赋给pa.并在过程中打印出pa和pb的值:
void test3(int* pa,int* pb)
{
pa = pb;
printf("调用函数时:\n");
printf("pa指针中存储的内容:%p\n", pa);
printf("pb指针中存储的内容:%p\n", pb);
printf("\n");
}
int main()
{
int a = 5;
int b = 10;
int* pa = &a;
int* pb = &b;
printf("调用函数前:\n");
printf("pa指针中存储的内容:%p\n", pa);
printf("pb指针中存储的内容:%p\n", pb);
printf("\n");
test3(pa,pb);
printf("调用函数后:\n");
printf("pa指针中存储的内容:%p\n", pa);
printf("pb指针中存储的内容:%p\n", pb);
printf("\n");
return 0;
}在编译器中查看运行结果:
(注:为方便演示使用的x86系统,因此指针的大小为4个字节)
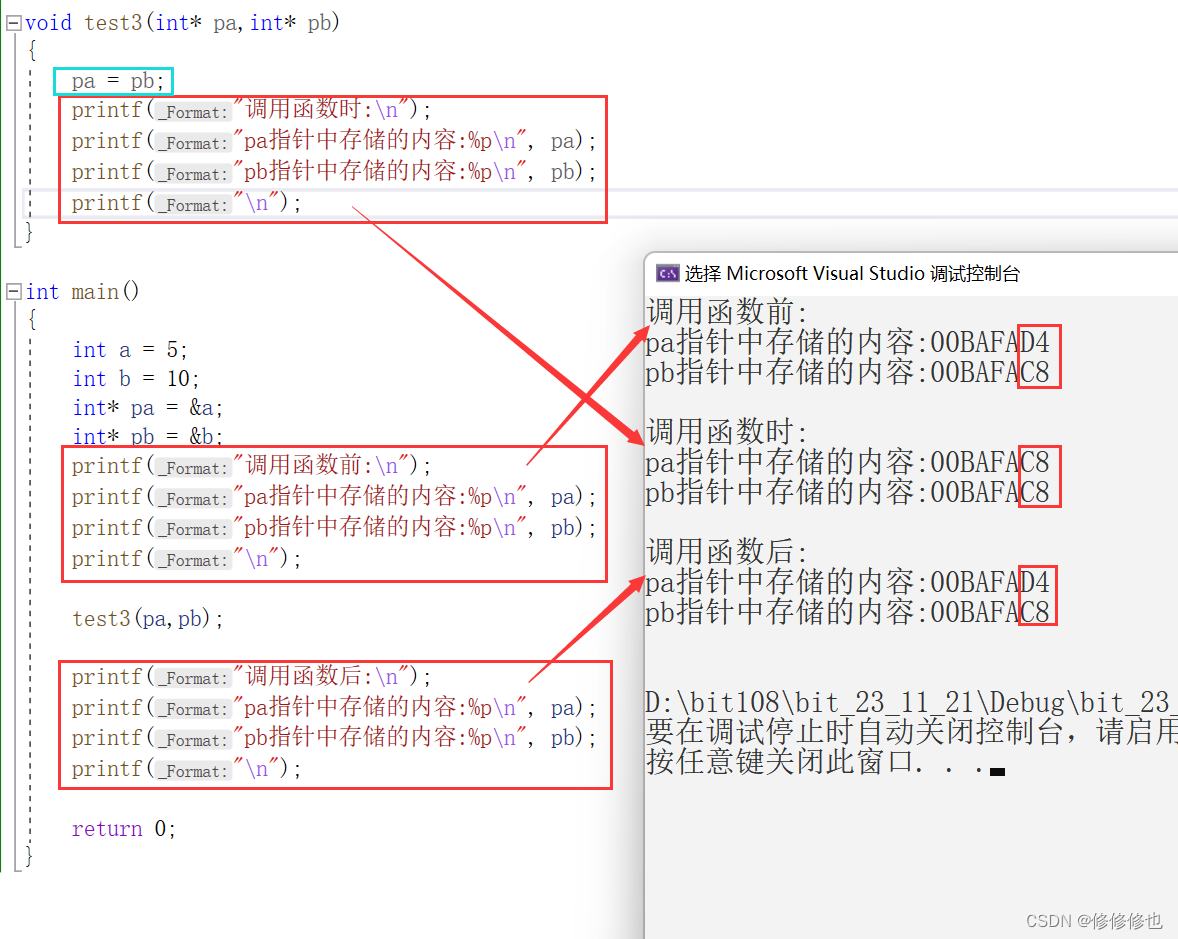
可以看到,传值调用虽然在函数调用时将pa的指向改为了pb,但是一旦出了函数之后pa的指向是完全没有改变的.
因此:在改变指针变量时形参的改变同样不影响实参!
🎏传址调用
既然改指针的时候给函数传指针本身没有用,那么要传什么呢?没错,要传"指针的指针",即二级指针.
如下代码,我们在主函数创建了两个变量a和b,并给其赋值为5和10.还创建了两个整型指针pa和pb分别记录下了变量a和b的地址.又创建了一个二级整型指针ppa用来记录指针pa的地址,然后我们通过传址调用函数test4,在函数内部将pb的值赋给解引用的ppa.并在过程中打印出pa和pb的值:
void test4(int** ppa, int* pb)
{
*ppa = pb;
printf("调用函数时:\n");
printf("pa指针中存储的内容:%p\n", *ppa);
printf("pb指针中存储的内容:%p\n", pb);
printf("\n");
}
int main()
{
int a = 5;
int b = 10;
int* pa = &a;
int* pb = &b;
int** ppa = &pa;
printf("调用函数前:\n");
printf("pa指针中存储的内容:%p\n", pa);
printf("pb指针中存储的内容:%p\n", pb);
printf("\n");
test4(ppa, pb);
printf("调用函数后:\n");
printf("pa指针中存储的内容:%p\n", pa);
printf("pb指针中存储的内容:%p\n", pb);
printf("\n");
return 0;
}在编译器中查看运行结果:
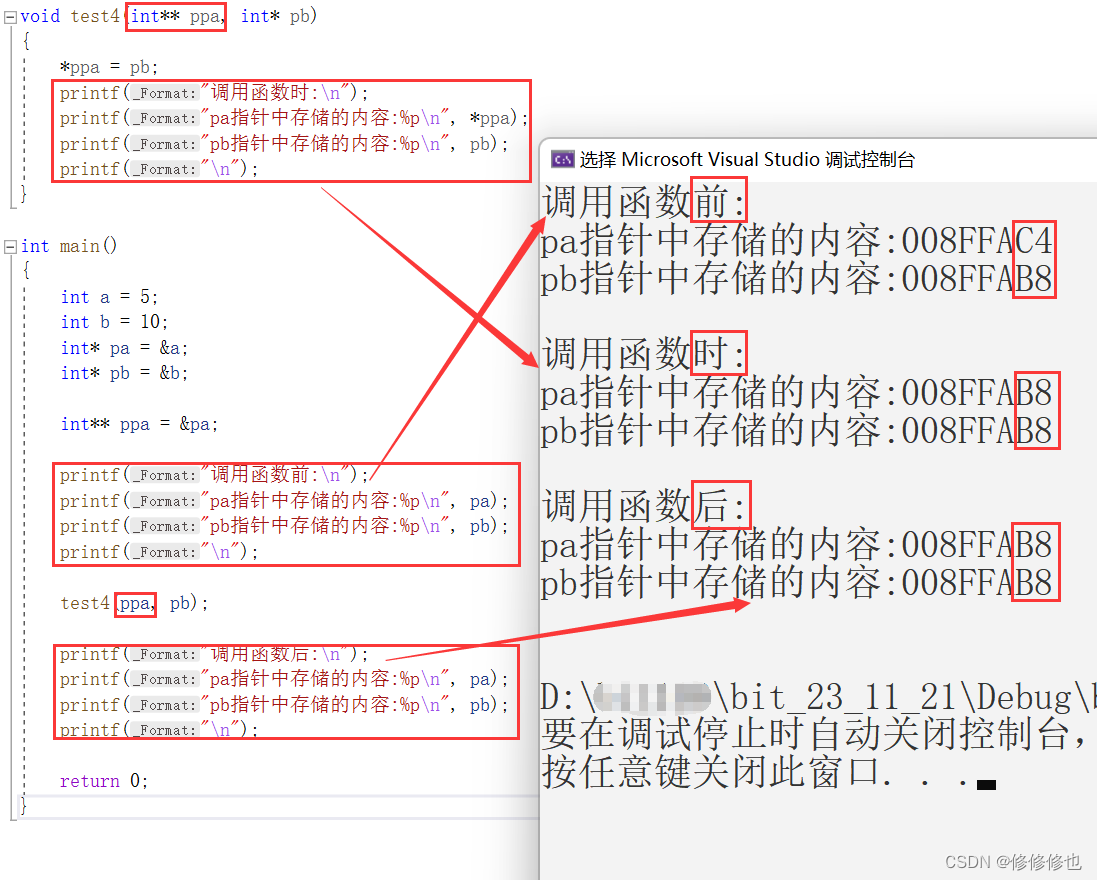
可以看到,传址调用的函数在内部修改指针pa的值,出了函数依然是有效的.
因此当我们想要在函数内修改指针的指向时,我们应该给函数传入二级指针.
3.调用函数更改数组和结构体成员
🎏更改数组成员
如下代码,我们在主函数创建了一个5个成员的数组arr,并给其初始化为0.然后我们通过调用函数test5,在函数内部将arr的成员赋为0,1,2,3,4.并在过程中打印出arr数组的成员值:
void test5(int arr[])
{
//修改arr数组成员的值
for (int i = 0; i < 5; i++)
{
arr[i] = i;
}
printf("调用函数时arr数组的成员:\n");
for (int i = 0; i < 5; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int arr[5] = { 0 };
printf("调用函数前arr数组的成员:\n");
for (int i = 0; i < 5; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
test5(arr);
printf("调用函数后arr数组的成员:\n");
for (int i = 0; i < 5; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}在编译器中查看运行结果: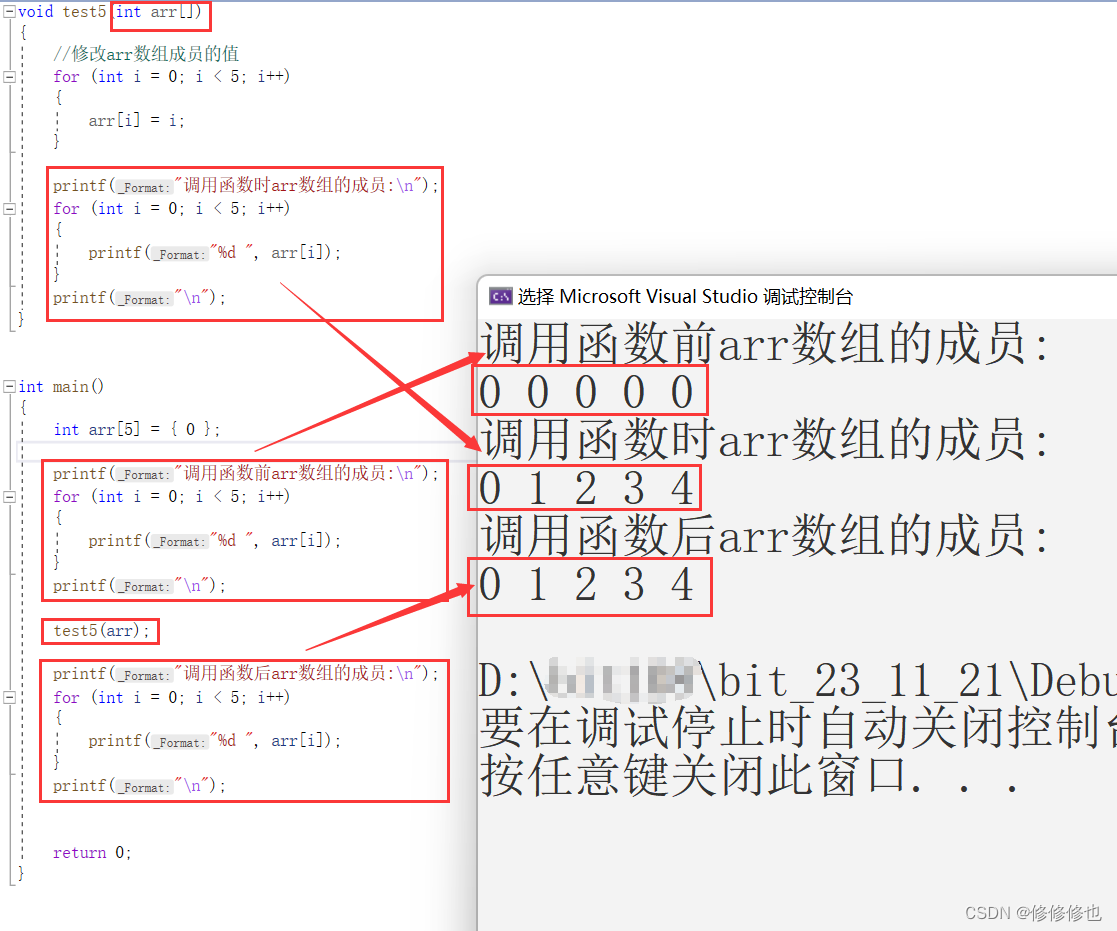
可以看到,test5函数成功修改了arr数组的成员值,但我们好像并没有传给函数arr数组的地址,为什么修改成功了呢?
这是因为在C语言中,数组名就是数组首元素的地址,因此我们看似给test5函数传入的是arr的名字,但实际上test5函数接收到的却是arr数组的地址,因此该函数同样可以写为:
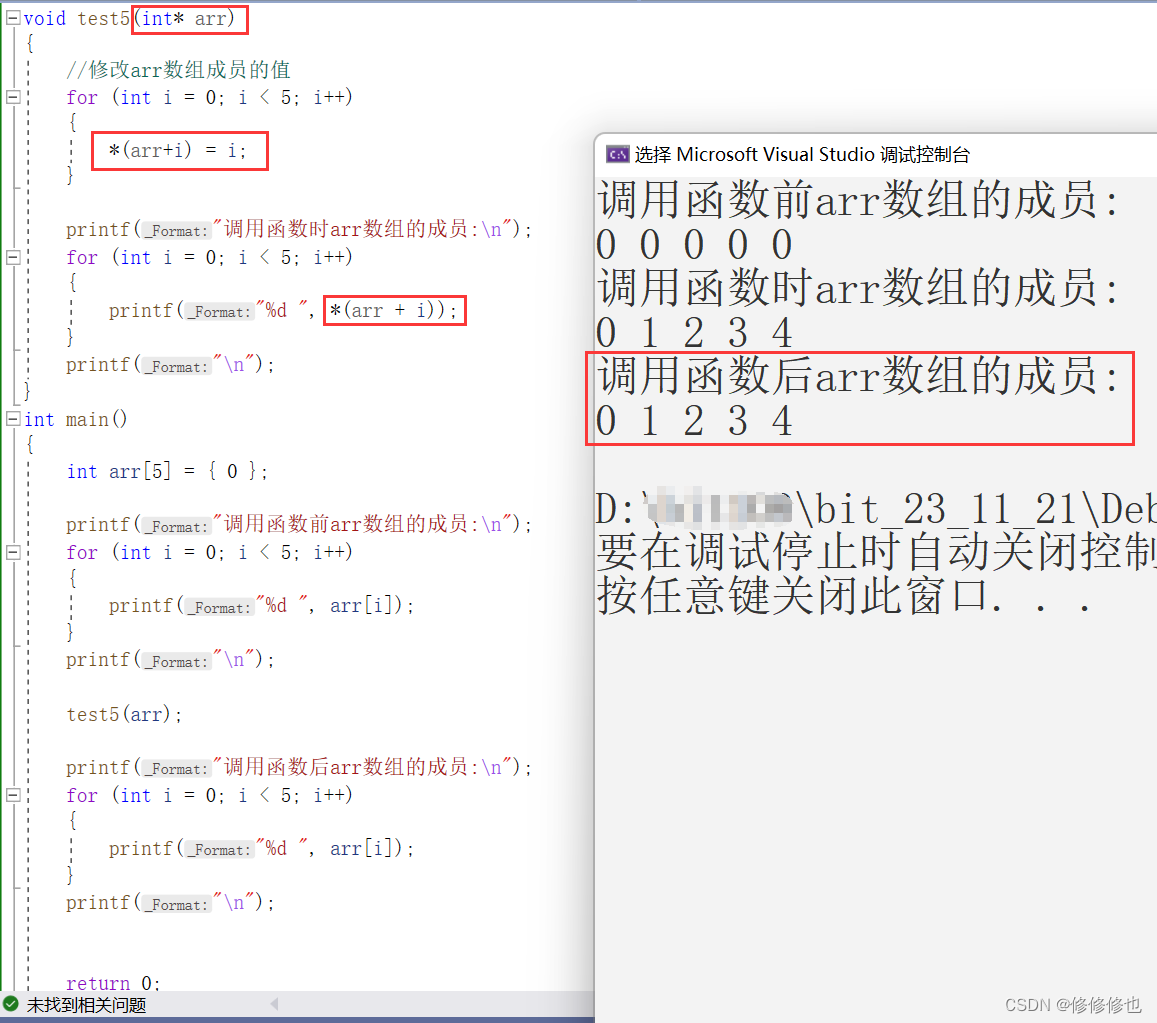
void test5(int* arr)
{
//修改arr数组成员的值
for (int i = 0; i < 5; i++)
{
*(arr+i) = i;
}
printf("调用函数时arr数组的成员:\n");
for (int i = 0; i < 5; i++)
{
printf("%d ", *(arr + i));
}
printf("\n");
}测试运行结果和上面没有任何差别:
🎏更改结构体成员
如下代码,我们在主函数中创建了一个结构体变量stu,并给其赋值"张三",20,1006.
然后我们通过传址调用函数test6,在函数内部将stu的成员赋为"李四",30,1024.并在过程中打印出stu结构体的成员值:
typedef struct Student
{
char name[5];
int age;
int idea;
}Stu;
void test6(Stu* stu)
{
strcpy(stu->name, "李四");
stu->age = 30;
stu->idea = 1024;
printf("调用函数时stu结构体的成员:\n");
printf("%s ", stu->name);
printf("%d ", stu->age);
printf("%d ", stu->idea);
printf("\n");
}
int main()
{
Stu stu = { "张三",20,1006 };
printf("调用函数前stu结构体的成员:\n");
printf("%s ", stu.name);
printf("%d ", stu.age);
printf("%d ", stu.idea);
printf("\n");
test6(&stu);
printf("调用函数后stu结构体的成员:\n");
printf("%s ", stu.name);
printf("%d ", stu.age);
printf("%d ", stu.idea);
printf("\n");
return 0;
}在编译器中查看运行结果:
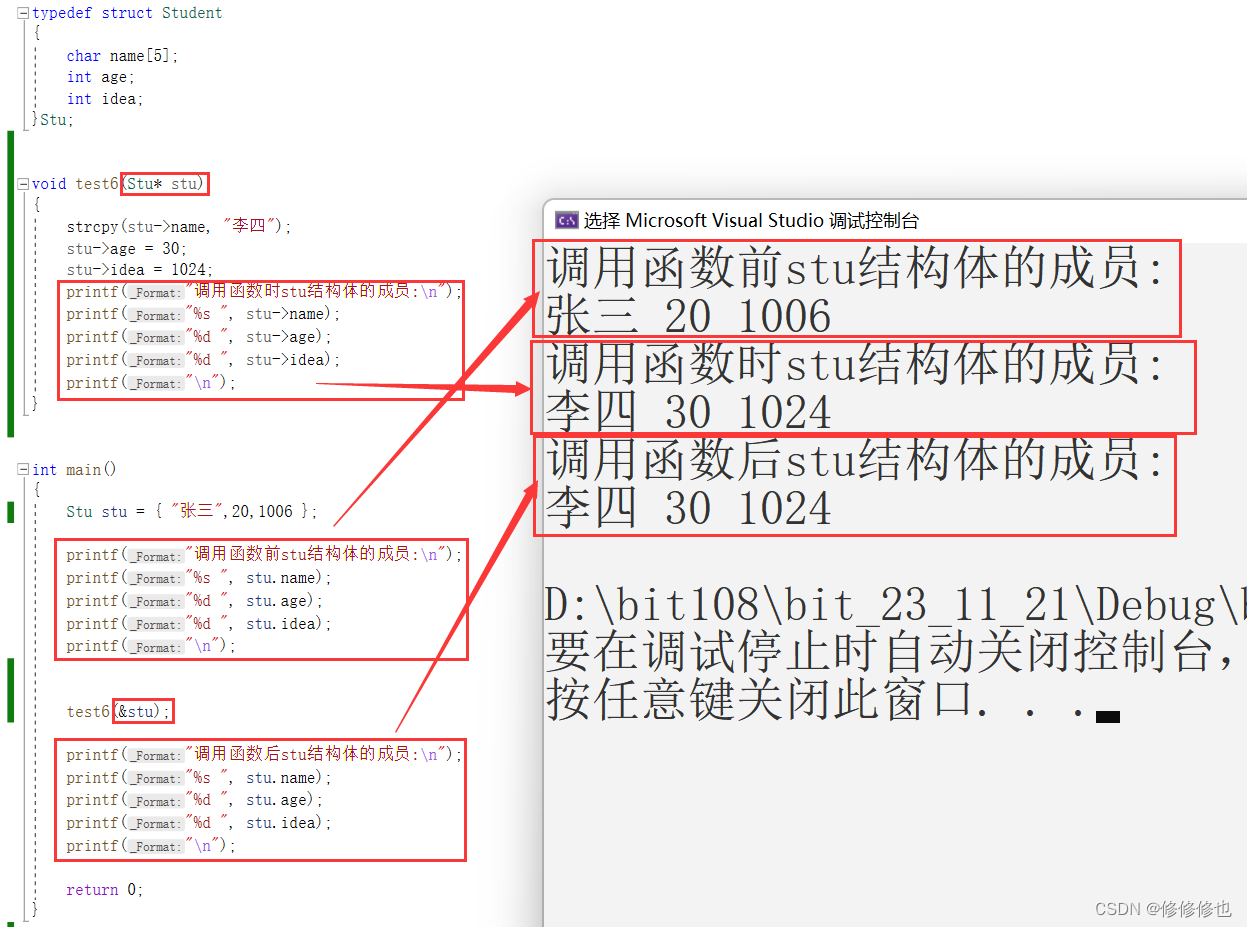
可以看到,要更改结构体的值,需要给函数传入结构体的指针才可以完成修改.
📌二级指针的作用
1.链表的头指针结构
我们在单链表程序的最开始曾经写过这样一句代码:

这句代码的作用是创建了一个链表的头指针,其逻辑图示如下:
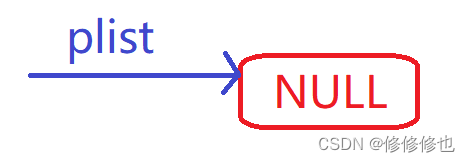
其在计算机的栈上的物理结构(以下简称物理结构)图示如下:

2.空链表时的链表尾插
尾插操作我们已经在之前单链表详解中详细介绍过了,
因此这里只演示其逻辑图示:(紫色线条代表操作)
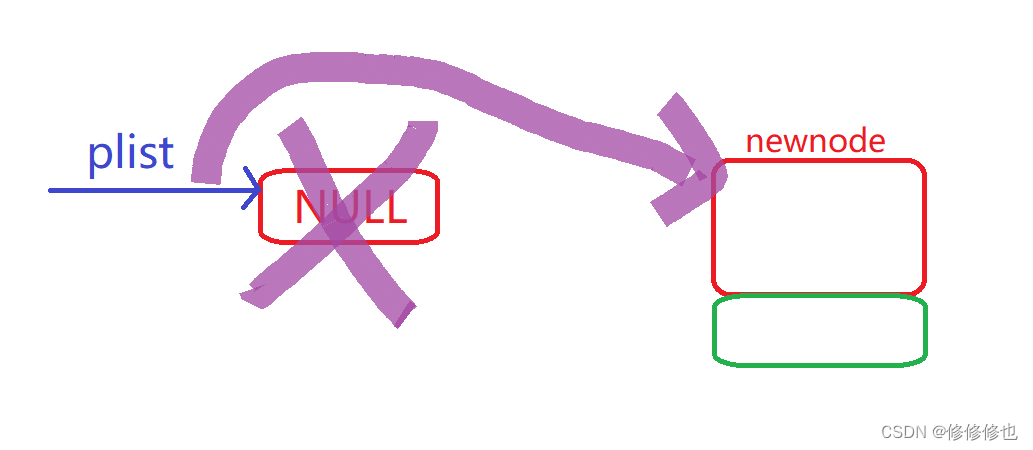
物理图示:(紫色线条代表操作)
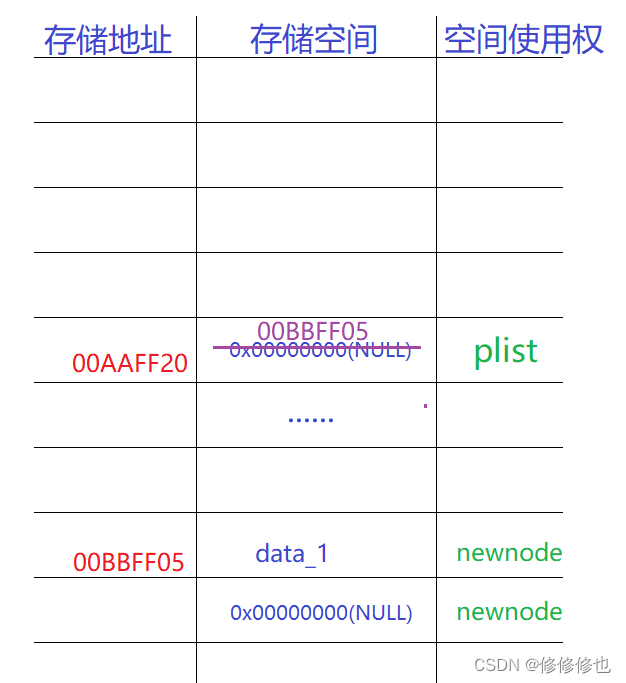
可以看到,在空链表时的链表尾插操作中,我们更改了头指针plist的指向,因此在函数中要使用到二级指针.
3.非空链表时的尾插逻辑
逻辑图示:(紫色线条代表操作)

物理图示:(紫色线条代表操作)
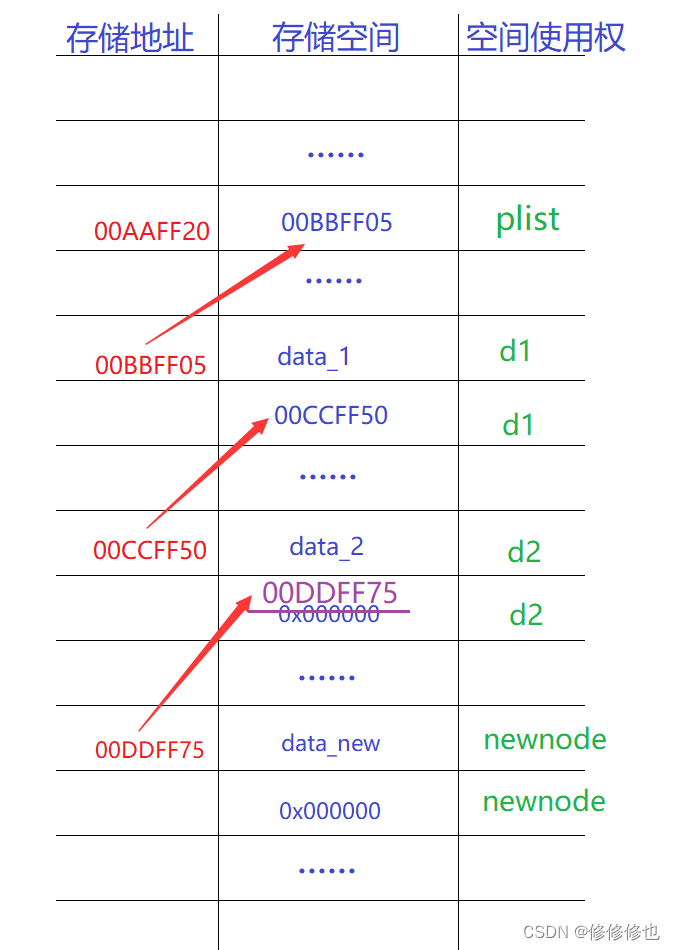
可以看到,在非空链表时的尾插中我们更改的是d2结点结构体的指针域的存储内容,因此这时我们操作只需要d2结构体的地址,即一级指针.
综上可得:
链表中传入二级指针的原因是我们会遇到需要更改头指针plist的指向的情况.
如果我们仅是在不改变头指针plist的指向的情况下对链表进行操作(如非空链表的尾删,尾插,对非首结点(FirstNode)的结点的插入/删除操作等),则不需要用到二级指针.
📌不使用二级指针操作链表的两种方法
那么我们在写链表程序时就必须要使用二级指针吗?答案是否定的,下面给大家提供了两种不使用二级指针就可以完成链表所有操作的方法,大家可以结合自身情况选择合适的方法完成链表程序.
1.使用带头结点的链表
原理:如果我们为单链表设置一个哨兵位的头结点,那么plist的指向就固定了.即:
带头结点空链表示意图:
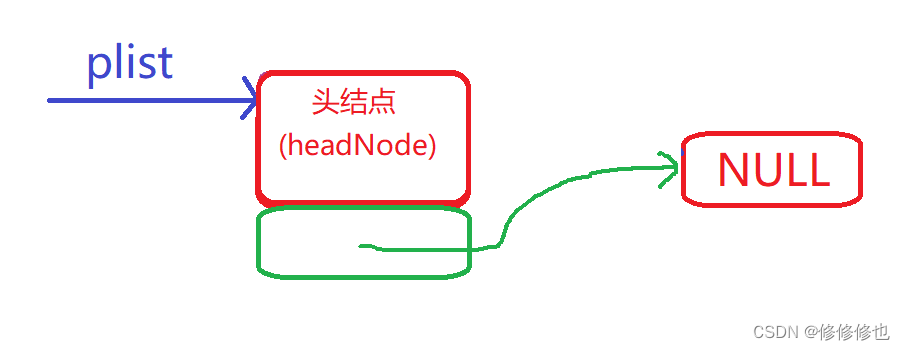
这时我们想改变链表的首结点(firstNode),如头删,头插等操作就只需要改变头结点的指针域即可.而plist只需要固定存储头结点(headNode)的地址,既然函数不需要改变plist的指向,也就不需要用到二级指针了.
带头结点空链表头插逻辑示意图:(紫色线条为操作)
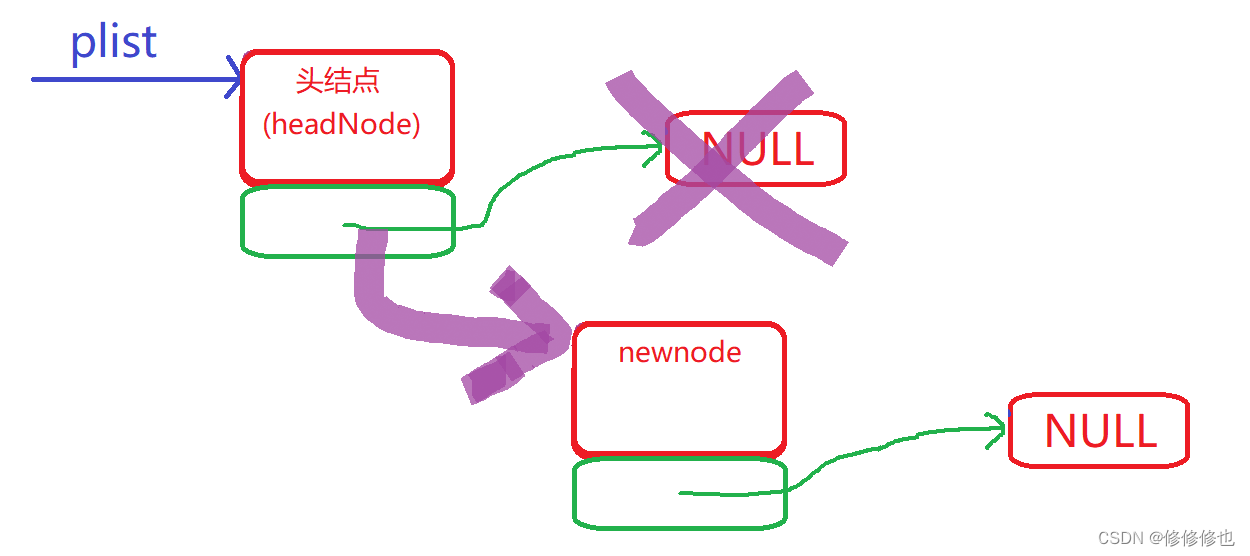
带头结点空链表头插逻辑物理示意图:(紫色线条为操作)
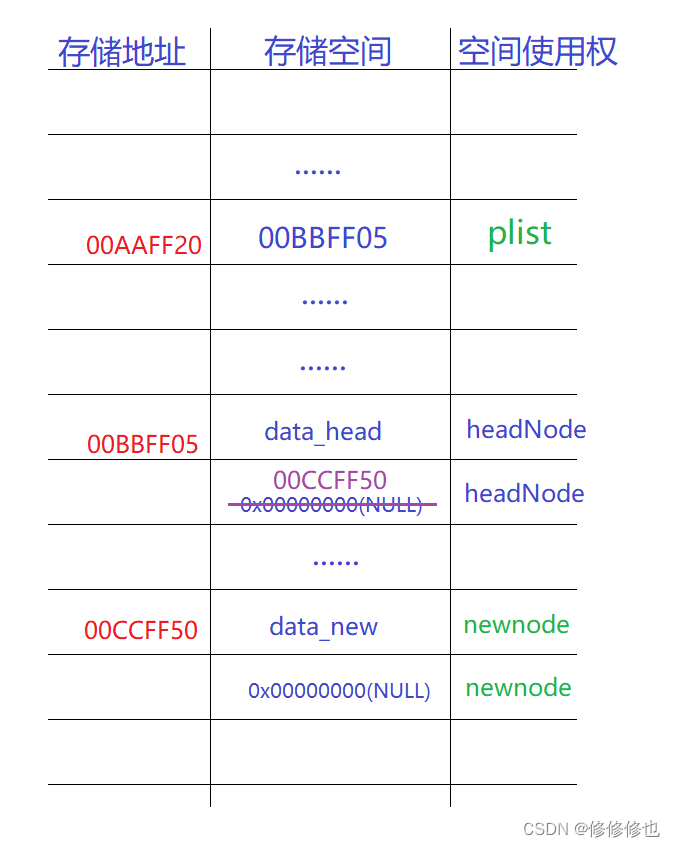
可以看到,在带头结点空链表的头插操作中,plist的值没有被改变,我们通过改变头结点指针域的值实现了链表的头插,因此使用带头结点的链表就可以不使用二级指针操作链表.
2.在外部更改头指针的指向
原理:既然我们在函数内部给plist赋值不会影响到函数外的plist的指向,那么我们直接将更改指向这步操作放在函数外即可.其实类似的操作我们在获取新结点函数中就已经应用过了:
如单链表中的BuySLTNode()函数:
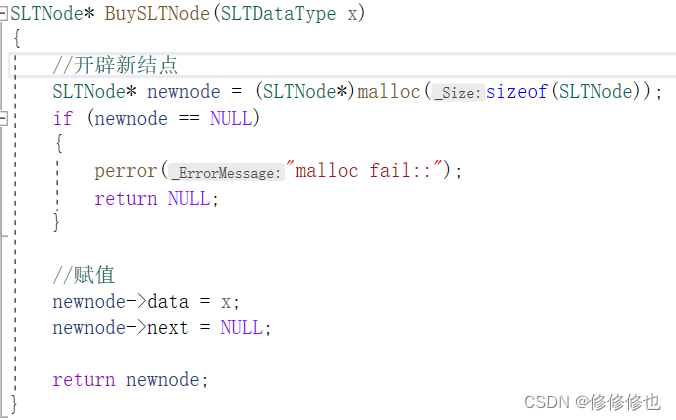
为了防止newnode指针记录的动态开辟的空间的地址出了函数就被销毁,我们将新结点的地址通过返回值返回到函数外并用一个指针接收,这样虽然出了空间newnode被销毁,但我们已经在函数外部使用指针记录了下函数返回的它的地址,因此出了函数还可以正常使用这块空间.
同理,函数中更改了头指针的指向后,我们将新的头指针的地址记录下来并返回给主函数,然后在主函数中重新使用plist指针接收这个头即可更新头指针的指向:
该思路代码示例如下(仅展示头插部分主函数与头插函数逻辑) :
//单链表头插
SLTNode* SLTPushFront(SLTNode* phead, int x)
{
//创建新结点
SLTNode* newnode = BuySLTNode(x);//BuySLTNode函数的实现参照上文
//先将newnode的next指向首结点
newnode->next = phead;
//再将phead指向newnode
phead = newnode;
//返回新头phead
return phead;
}
int main()
{
SLTNode* plist=NULL;
printf("请输入要头插的数据:>");
int pushfront_data = 0;
scanf("%d", &pushfront_data);
plist=SLTPushFront(plist, pushfront_data);
//把SLTPushFront函数返回的新头的地址赋给plist,这样plist就重新指向新头了
return 0;
}经过测试,这种方法同样可以不使用二级指针就能够完成链表的一系列相关操作,但缺点是只要调用了有可能改变plist的函数,都必须在外面使用plist接收返回值以便更新新的头结点.有时一旦忘了就会导致程序出错,比较麻烦且容易出错.
结语
希望这篇链表中二级指针的应用能对大家有所帮助,欢迎大佬们留言或私信与我交流.
学海漫浩浩,我亦苦作舟!关注我,大家一起学习,一起进步!
相关文章推荐

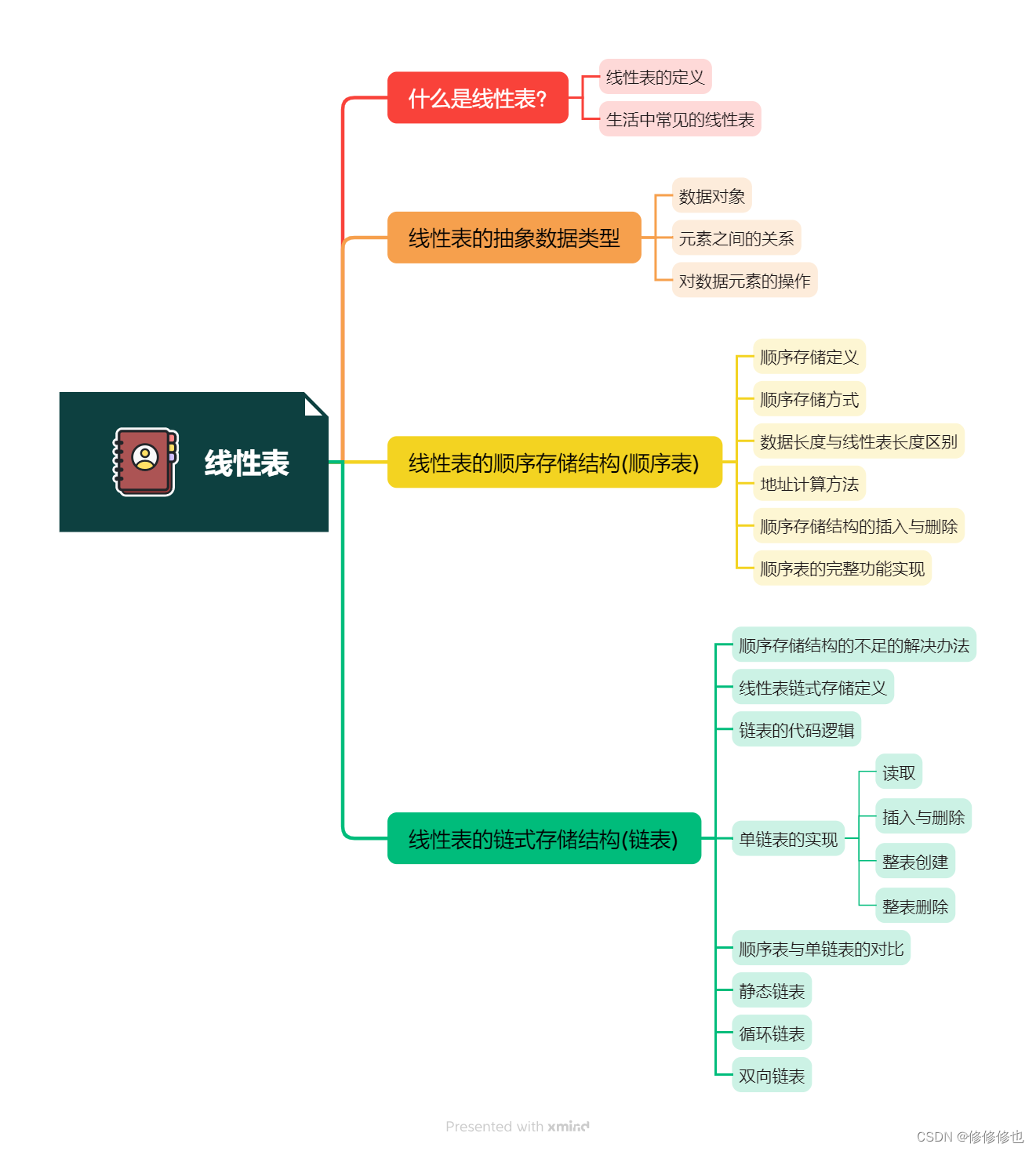
数据结构线性篇思维导图:
















 2482
2482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











