







UNIX的传统 是Everything is a file,键盘、显示器、串口、磁盘等设备在/dev 目录下都有一个特殊的设备文件与之对应,这些设备文件也可以像普通文件(保存在磁盘上的文件)一样打开、读、写和关闭,使用的函数接口是相同的。用户程序调用C标准I/O库函数读写普通文件或设备,而这些库函数要通过系统调用把读写请求传给内核 ,最终由内核驱动磁盘或设备完成I/O操作。C标准库为每个打开的文件分配一个I/O缓冲区以加速读写操作,通过文件的FILE 结构体可以找到这个缓冲区,用户调用读写函数大多数时候都在I/O缓冲区中读写,只有少数时候需要把读写请求传给内核。以fgetc / fputc 为例,当用户程序第一次调用fgetc 读一个字节时,fgetc 函数可能通过系统调用 进入内核读1K字节到I/O缓冲区中,然后返回I/O缓冲区中的第一个字节给用户,把读写位置指 向I/O缓冲区中的第二个字符,以后用户再调fgetc ,就直接从I/O缓冲区中读取,而不需要进内核 了,当用户把这1K字节都读完之后,再次调用fgetc 时,fgetc 函数会再次进入内核读1K字节 到I/O缓冲区中。在这个场景中用户程序、C标准库和内核之间的关系就像在“Memory Hierarchy”中 CPU、Cache和内存之间的关系一样,C标准库之所以会从内核预读一些数据放 在I/O缓冲区中,是希望用户程序随后要用到这些数据,C标准库的I/O缓冲区也在用户空间,直接 从用户空间读取数据比进内核读数据要快得多。另一方面,用户程序调用fputc 通常只是写到I/O缓 冲区中,这样fputc 函数可以很快地返回,如果I/O缓冲区写满了,fputc 就通过系统调用把I/O缓冲 区中的数据传给内核,内核最终把数据写回磁盘或设备。有时候用户程序希望把I/O缓冲区中的数据立刻 传给内核,让内核写回设备或磁盘,这称为Flush操作,对应的库函数是fflush,fclose函数在关闭文件 之前也会做Flush操作。
我们知道main 函数被启动代码这样调用:exit(main(argc, argv));。
main 函数return时启动代码会 调用exit ,exit 函数首先关闭所有尚未关闭的FILE *指针(关闭之前要做Flush操作),然后通 过_exit 系统调用进入内核退出当前进程.
C标准库的I/O缓冲区有三种类型:全缓冲、行缓冲和无缓冲。当用户程序调用库函数做写操作(读操作时I/O缓冲区是如何变化的?)时, 不同类型的缓冲区具有不同特性。
全缓冲
如果缓冲区写满了就写回内核。对于驻留在磁盘上的文件通常是由标准I/O库实施全缓冲的。在一个流上执行第一次I/O操作时,相关标准I/O函数通常调用malloc获得需使用的缓冲区。行缓冲
如果用户程序写的数据中有换行符就把这一行写回内核,或者如果缓冲区写满了就写回内核。标准输入和标准输出对应终端设备时通常是行缓冲的。
无缓冲
用户程序每次调库函数做写操作都要通过系统调用写回内核。标准错误输出通常是无缓冲的,这样用户程序产生的错误信息可以尽快输出到设备。除了写缓冲区满、写入换行符之外,行缓冲还有两种情况会自动做Flush操作。如果
用户程序调用库函数从无缓冲的文件中读取
或者从行缓冲的文件中读取,并且这次读操作会引发系统调用从内核读取数据
如果用户程序不想完全依赖于自动的Flush操作,可以调fflush函数手动做Flush操作。
#include <stdio.h>
int fflush(FILE *stream);
返回值:成功返回0,出错返回EOF并设置errno
fflush函数用于确保数据写回了内核,以免进程异常终止时丢失数据,如fflush(stdout); 作为一个特例,调 用fflush(NULL)可以对所有打开文件的I/O缓冲区做Flush操作。
2. 用户程序的缓冲区
在函数栈上分配的如char buf[10];之类的缓冲区, strcpy(buf, str); str 所指向的字符串有可能超过10个字符而导致写越界,这种写越界可能当时不出错, 而在函数返回时出现段错误,原因是写越界覆盖了保存在栈帧上的返回地址, 函数返回时跳转到非法地址,因而出错。像buf 这种由调用者分配并传给函数读或写的一段内存通 常称为缓冲区(Buffer),缓冲区写越界的错误称为缓冲区溢出(Buffer Overflow)。如果只是出 现段错误那还不算严重,更严重的是缓冲区溢出Bug经常被恶意用户利用,使函数返回时跳转到一 个事先设好的地址,执行事先设好的指令,如果设计得巧妙甚至可以启动一个Shell,然后随心所欲 执行任何命令,可想而知,如果一个用root 权限执行的程序存在这样的Bug,被攻陷了,后果将很 严重。
下图以fgets / fputs 示意了I/O缓冲区的作用,使用fgets / fputs 函数时在用户程序中也需要分配缓冲 区(图中的buf1 和buf2 ),注意区分用户程序的缓冲区和C标准库的I/O缓冲区。

3.内核缓冲区
(1)终端缓冲
终端设备有输入和输出队列缓冲区,如下图所示

注意上述情况是用户进程(shell进程也是)调用read/write等unbuffer I/O函数的情况,当调用printf/scanf(底层实现也是read/write)等C标准I/O库函数时,当用户程序调用scanf读取键盘输入时,开始输入的字符都存到C标准库的I/O缓冲区,直到我们遇到换行符(标准输入和标准输出都是行缓冲的)时,系统调用read将缓冲区的内容读到内核的终端输入队列;当调用printf打印一个字符串时,如果语句中带换行符,则立刻将放在I/O缓冲区的字符串调用write写到内核的输出队列,打印到屏幕上,如果printf语句没带换行符,则由上面的讨论可知,程序退出时会做fflush操作.
(2)虽然write 系统调用位于C标准库I/O缓冲区的底层,被称为Unbuffered I/O函数,但在write 的底层也可以分配一个内核I/O缓冲区,所以write 也不一定是直接写到文件的,也 可能写到内核I/O缓冲区中,可以使用fsync函数同步至磁盘文件,至于究竟写到了文件中还是内核缓冲区中对于进程来说是没有差别 的,如果进程A和进程B打开同一文件,进程A写到内核I/O缓冲区中的数据从进程B也能读到,因为内核空间是进程共享的, 而c标准库的I/O缓冲区则不具有这一特性,因为进程的用户空间是完全独立的.
(3)为了减少读盘次数,内核缓存了目录的树状结构,称为dentry(directory entry(目录下项) cache
(4)FIFO和UNIX Domain Socket这两种IPC机制都是利用文件系统中的特殊文件来标识的。FIFO文件在磁盘上没有数据块,仅用来标识内核中的一条通道,各进程可以打开这个文件进行read / write ,实际上是在读写内核通道(根本原因在于这个file 结构体所指向的read 、write 函数指针和常规文件不一样),这样就实现了进程间通信。UNIX Domain Socket和FIFO的原理类似,也需 要一个特殊的socket文件来标识内核中的通道,文件类型s表示socket,这些文件在磁盘上也没有数据块。UNIX Domain Socket是目前最广泛使用 的IPC机制.如下图:

下面的这个是glibc给出的FILE的定义,它是实现相关的,别的平台定义方式不同.
- struct _IO_FILE {
- int _flags;
- #define _IO_file_flags _flags
- char* _IO_read_ptr;
- char* _IO_read_end;
- char* _IO_read_base;
- char* _IO_write_base;
- char* _IO_write_ptr;
- char* _IO_write_end;
- char* _IO_buf_base;
- char* _IO_buf_end;
- char *_IO_save_base;
- char *_IO_backup_base;
- char *_IO_save_end;
- struct _IO_marker *_markers;
- struct _IO_FILE *_chain;
- int _fileno;
- };
上面的定义中有三组重要的字段:
1.char* _IO_read_ptr; char* _IO_read_end; char* _IO_read_base;
2.char* _IO_write_base; char* _IO_write_ptr; char* _IO_write_end;
3.char* _IO_buf_base; char* _IO_buf_end;
其中
_IO_read_base 指向"读缓冲区"
_IO_read_end 指向"读缓冲区"的末尾
_IO_read_end - _IO_read_base "读缓冲区"的长度
_IO_write_base 指向"写缓冲区"
_IO_write_end 指向"写缓冲区"的末尾
_IO_write_end - _IO_write_base "写缓冲区"的长度
_IO_buf_base 指向"缓冲区"
_IO_buf_end 指向"缓冲区"的末尾
_IO_buf_end - _IO_buf_base "缓冲区"的长度
上面的定义貌似给出了3个缓冲区,实际上上面的_IO_read_base,_IO_write_base, _IO_buf_base都指向了同一个缓冲区.这个缓冲区跟上面程序中的char buf[5];没有任何关系.
他们在第一次buffered I/O操作时由库函数自动申请空间,最后由相应库函数负责释放.(再次声明,这里只是glibc的实现,别的实现可能会不同,后面就不再强调了)
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(void)
{
char buf[5];
FILE *myfile =stdin;
printf("before reading\n");
printf("read buffer base %p\n", myfile->_IO_read_base);
printf("read buffer length %d\n", myfile->_IO_read_end - myfile->_IO_read_base);
printf("write buffer base %p\n", myfile->_IO_write_base);
printf("write buffer length %d\n", myfile->_IO_write_end - myfile->_IO_write_base);
printf("buf buffer base %p\n", myfile->_IO_buf_base);
printf("buf buffer length %d\n", myfile->_IO_buf_end - myfile->_IO_buf_base);
printf("\n");
fgets(buf, 5, myfile);
fputs(buf, myfile); <strong><span style="color:#ff0000;">//这个地方可能有问题,应该改为fputs(buf,stdout);</span></strong>
printf("\n");
printf("after reading\n");
printf("read buffer base %p\n", myfile->_IO_read_base);
printf("read buffer length %d\n", myfile->_IO_read_end - myfile->_IO_read_base);
printf("write buffer base %p\n", myfile->_IO_write_base);
printf("write buffer length %d\n", myfile->_IO_write_end - myfile->_IO_write_base); <strong><span style="color:#ff0000;"> //输出的结果为0(stdin的此值是否始终为0?)</span></strong>
printf("buf buffer base %p\n", myfile->_IO_buf_base);
printf("buf buffer length %d\n", myfile->_IO_buf_end - myfile->_IO_buf_base);
return 0;
} 可以看到,在读操作之前,myfile的缓冲区是没有被分配的,在一次读之后,myfile的缓冲区才被分配.这个缓冲区既不是内核中的缓冲区,也不是用户分配的缓冲区,而是有用户进程空间中的由buffered I/O系统负责维护的缓冲区.(当然,用户可以可以维护该缓冲区,这里不做讨论了)
上面的例子只是说明了buffered I/O缓冲区的存在,下面从全缓冲,行缓冲和无缓冲3个方面看一下buffered I/O是如何工作的.
1.1. 全缓冲
下面是APUE上的原话:
全缓冲"在填满标准I/O缓冲区后才进行实际的I/O操作.对于驻留在磁盘上的文件通常是由标准I/O库实施全缓冲的"书中这里"实际的I/O操作"实际上容易引起误导,这里并不是读写磁盘,而应该是进行read或write的系统调用
下面两个例子会说明这个问题
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(void)
{
char buf[5];
char *cur;
FILE *myfile;
myfile = fopen("bbb.txt", "r");
printf("before reading, myfile->_IO_read_ptr: %d\n", myfile->_IO_read_ptr - myfile->_IO_read_base);
fgets(buf, 5, myfile); //仅仅读4个字符
cur = myfile->_IO_read_base;
while (cur < myfile->_IO_read_end) //实际上读满了这个缓冲区
{
printf("%c",*cur);
cur++;
}
printf("\nafter reading, myfile->_IO_read_ptr: %d\n", myfile->_IO_read_ptr - myfile->_IO_read_base);
return 0;
} 上面提到的bbb.txt文件的内容是由很多行的"123456789"组成
上例中,fgets(buf, 5, myfile); 仅仅读4个字符,但是,缓冲区已被写满,但是_IO_read_ptr却向前移动了5位,下次再次调用读操作时,只要要读的位数不超过myfile->_IO_read_end - myfile->_IO_read_ptr那么就不需要再次调用系统调用read,只要将数据从myfile的缓冲区拷贝到buf即可(从myfile->_IO_read_ptr开始拷贝)
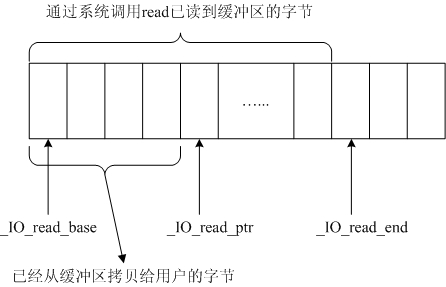
全缓冲读的时候:
_IO_read_base始终指向缓冲区的开始
_IO_read_end始终指向已从内核读入缓冲区的字符的下一个(对全缓冲来说,buffered I/O读每次都试图都将缓冲区读满)
_IO_read_ptr始终指向缓冲区中已被用户读走的字符的下一个
(_IO_read_end < (_IO_buf_base-_IO_buf_end)) && (_IO_read_ptr == _IO_read_end)时则已经到达文件末尾,其中_IO_buf_base-_IO_buf_end是缓冲区的长度
一般大体的工作情景为:
第一次fgets(或其他的)时,标准I/O会调用read将缓冲区充满,下一次fgets不调用read而是直接从该缓冲区中拷贝数据,直到缓冲区的中剩余的数据不够时,再次调用read.在这个过程中,_IO_read_ptr就是用来记录缓冲区中哪些数据是已读的,哪些数据是未读的
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(void)
{
char buf[2048]={0};
int i;
FILE *myfile;
myfile = fopen("aaa.txt", "r+");
i= 0;
while (i<2048)
{
fwrite(buf+i, 1, 512, myfile);
i +=512;
//注释掉这句则可以写入aaa.txt
myfile->_IO_write_ptr = myfile->_IO_write_base;
printf("%p write buffer base\n", myfile->_IO_write_base);
printf("%p buf buffer base \n", myfile->_IO_buf_base);
printf("%p read buffer base \n", myfile->_IO_read_base);
printf("%p write buffer ptr \n", myfile->_IO_write_ptr);
printf("\n");
}
return 0;
} 上面这个是关于全缓冲写的例子.
全缓冲时,只有当标准I/O自动flush(比如当缓冲区已满时)或者手工调用fflush时,标准I/O才会调用一次write系统调用.例子中,fwrite(buf+i, 1, 512, myfile);这一句只是将buf+i接下来的512个字节写入缓冲区,由于缓冲区未满,标准I/O并未调用write.此时,myfile->_IO_write_ptr = myfile->_IO_write_base;会导致标准I/O认为没有数据写入缓冲区,所以永远不会调用write,这样aaa.txt文件得不到写入.注释掉myfile->_IO_write_ptr = myfile->_IO_write_base;前后,看看效果.
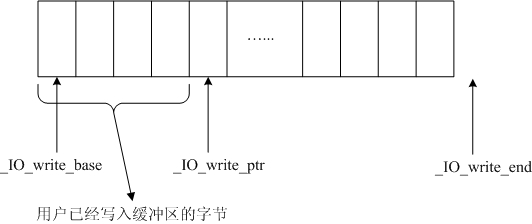
全缓冲写的时候:
_IO_write_base始终指向缓冲区的开始
_IO_write_end全缓冲的时候,始终指向缓冲区的最后一个字符的下一个
(对全缓冲来说,buffered I/O写总是试图在缓冲区写满之后,再系统调用write)
_IO_write_ptr始终指向缓冲区中已被用户写入的字符的下一个
flush的时候,将_IO_write_base和_IO_write_ptr之间的字符通过系统调用write写入内核
1.2. 行缓冲
下面是APUE上的原话:
行缓冲"当输入输出中遇到换行符时,标准I/O库执行I/O操作. "书中这里"执行O操作"也容易引起误导,这里不是读写磁盘,而应该是进行read或write的系统调用
下面两个例子会说明这个问题
第一个例子可以用来说明下面这篇帖子的问题
http://bbs.chinaunix.net/viewthread.php?tid=954547
#include <stdlib.h>
#include <stdio.h>
int main(void)
{
char buf[5];
char buf2[10];
fgets(buf, 5, stdin); //第一次输入时,超过5个字符
puts(stdin->_IO_read_ptr);//本句说明整行会被一次全部读入缓冲区,而非仅仅上面需要的个字符
stdin->_IO_read_ptr = stdin->_IO_read_end; //标准I/O会认为缓冲区已空,再次调用read,注释掉,再看看效果
printf("\n");
puts(buf);
fgets(buf2, 10, stdin);
puts(buf2);
return 0;
} 
行缓冲读的时候,
_IO_read_base始终指向缓冲区的开始
_IO_read_end始终指向已从内核读入缓冲区的字符的下一个
_IO_read_ptr始终指向缓冲区中已被用户读走的字符的下一个
(_IO_read_end < (_IO_buf_base-_IO_buf_end)) && (_IO_read_ptr == _IO_read_end)时则已经到达文件末尾
其中_IO_buf_base-_IO_buf_end是缓冲区的长度(这个地方是不是写反了,应该是:_IO_buf_end-_IO_buf_base)
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
char buf[5]={'1','2', '3', '4', '5'}; //最后一个不要是\n,是\n的话,标准I/O会自动flush的,这是行缓冲跟全缓冲的重要区别
void writeLog(FILE *ftmp)
{
fprintf(ftmp, "%p write buffer base\n", stdout->_IO_write_base);
fprintf(ftmp, "%p buf buffer base \n", stdout->_IO_buf_base);
fprintf(ftmp, "%p read buffer base \n", stdout->_IO_read_base);
fprintf(ftmp, "%p write buffer ptr \n", stdout->_IO_write_ptr);
fprintf(ftmp, "\n");
}
int main(void)
{
int i;
FILE *ftmp;
ftmp = fopen("ccc.txt", "w");
i= 0;
while (i<4)
{
fwrite(buf, 1, 5, stdout);
i++;
*stdout->_IO_write_ptr++ = '\n';//可以单独把这句打开,看看效果
//getchar();//getchar()会导致标准I/O缓冲区立即flush
//打开下面的注释,你就会发现屏幕上什么输出也没有
//stdout->_IO_write_ptr = stdout->_IO_write_base;
writeLog(ftmp); //这个只是为了查看缓冲区指针的变化
}
return 0;
} 这个例子将将FILE结构中指针的变化写入的文件ccc.txt,运行后可以有兴趣的话,可以看看.
上面这个是关于行缓冲写的例子.
stdout->_IO_write_ptr = stdout->_IO_write_base;会使得标准I/O认为缓冲区是空的,从而没有任何输出.可以将上面程序中的注释分别去掉,看看运行结果
行缓冲时,下面3个条件之一会导致缓冲区立即被flush
1. 缓冲区已满
2. 遇到一个换行符;比如将上面例子中buf[4]改为'\n'时
3. 再次要求从内核中得到数据时(从标准I/O缓冲区中取数据时,不会flush的,打开此程序的getchar会发现很有意思的现象);比如上面的程序加上getchar()会导致马上输出
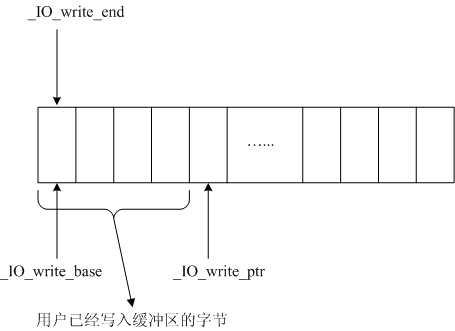
行缓冲写的时候:
_IO_write_base始终指向缓冲区的开始
_IO_write_end始终指向缓冲区的开始
_IO_write_ptr始终指向缓冲区中已被用户写入的字符的下一个
flush的时候,将_IO_write_base和_IO_write_ptr之间的字符通过系统调用write写入内核
1.3. 无缓冲
无缓冲时,标准I/O不对字符进行缓冲存储.典型代表是stderr,这里的无缓冲,并不是指缓冲区大小为0,其实,还是有缓冲的,大小为1
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(void)
{
fputs("stderr", stderr);
printf("%d\n", stderr->_IO_buf_end - stderr->_IO_buf_base);
return 0;
} 对无缓冲的流的每次读写操作都会引起系统调用
1.4 feof的问题
CU上已经有无数的帖子在探讨feof了,这里从缓冲区的角度去考察一下.对于一个空文件,为什么要先读一下,才能用feof判断出该文件到了结尾了呢?
<span style="font-family:Microsoft YaHei;font-size:14px;">#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(void)
{
char buf[5];
char buf2[10];
fgets(buf, sizeof(buf), stdin);//输入要于4个,少于13个字符才能看出效果
puts(buf);
//交替注释下面两行
//stdin->_IO_read_end = stdin->_IO_read_ptr+1;
stdin->_IO_read_end = stdin->_IO_read_ptr + sizeof(buf2)-1;
fgets(buf2, sizeof(buf2), stdin);
puts(buf2);
if (feof(stdin))
printf("input end\n");
return 0;
} </span>运行上面的程序,输入多于4个,少于13个字符,并且以连按两次ctrl+d为结束(不要按回车)从上面的例子,可以看出,每当满足(_IO_read_end < (_IO_buf_base-_IO_buf_end)) && (_IO_read_ptr == _IO_read_end)时,标准I/O则认为已经到达文件末尾,feof(stdin)才会被设置,其中_IO_buf_base-_IO_buf_end是缓冲区的长度.也就是说,标准I/O是通过它的缓冲区来判断流是否要结束了的.这就解释了为什么即使是一个空文件,标准I/O也需要读一次,才能使用feof判断释放为空
1.5. 其他说明
很多新手有一个误解,就是fgets, fputs代表行缓冲,fread, fwrite代表全缓冲 fgetc, fputc代表无缓冲等等.其实不是这样的,是什么样的缓冲跟使用那个函数没有关系,而跟你读写什么类型的文件有关系.上面的例子中多次在全缓冲中使用fgets, fputs,而在行缓冲中使用fread, fwrite。标准I/O缓存区是针对每个流的(FILE *fp),而不是针对I/O函数的
下面的是引至APUE的,实际上ISO C要求:
1.当且仅当标准输入和标准输出并不涉及交互式设备时,他们才是全缓冲的
2.标准错误输出决不是全缓冲的.
很多系统默认使用下列类型的标准:
1.标准错误输出是不带缓冲的.
2.如若是涉及终端设备的其他流,则他们是行缓冲的;否则是全缓冲的.
转自:http://blog.csdn.net/jnu_simba/article/details/8806712
转自:http://www.cnblogs.com/cavehubiao/p/3981482.html














 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









