







一、前言
Linux内核链表作为内核最基础最常用的数据结构,那么在咱们用户态的编程下是否可以借鉴?
二、相关知识
1、双向循环链表
如图所示,每个节点分别有前驱(prev)、后继(next)两个指针域,双链表支持两个方向的遍历,循环则指尾节点又可以重新指向到头节点;
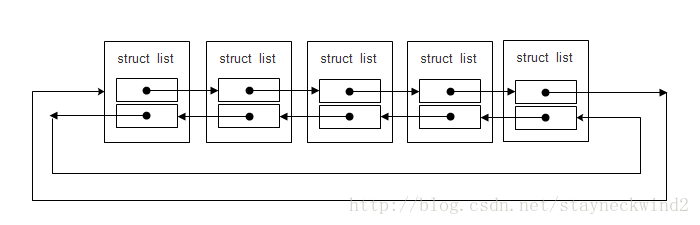
2、内核链表的实现(以3.10.25为例)
2.1 头节点定义(linux-3.10.25/include/linux/list.h)
struct list_head {
struct list_head *next, *prev;
}
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}首先是链表节点的实现与初始化,即头节点为空节点,并把前驱后继指向了自己;
然后仔细看这个头结构,会发现里头并未包含数据域,这里考虑的是要抽象出来与数据类型无关的链表接口;
2.2 节点增加删除
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *node,
struct list_head *prev,
struct list_head *next)
{
next->prev = node;
node->next = next;
node->prev = prev;
prev->next = node;
}
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *node, struct list_head *head)
{
__list_add(node, head, head->next);
}
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *node, struct list_head *head)
{
__list_add(node, head->prev, head);
}
#ifndef LIST_POISON1
#define LIST_POISON1 ((void *)0x00100100 + POISON_POINTER_DELTA)
#endif
#ifndef LIST_POISON2
#define LIST_POISON2 ((void *)0x00200200 + POISON_POINTER_DELTA)
#endif/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
2.3 节点遍历
先看一个简单的版本
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
三、使用内核链表
3.1 说明
上述小节简单介绍了内核链表的接口,还有一个问题没有提到:如何添加我们的数据域?
把 list.h 看做链表的模版的话,所以我们需要对 struct list_head 进行包装,并加入我们的数据域,最后效果如下图所示:
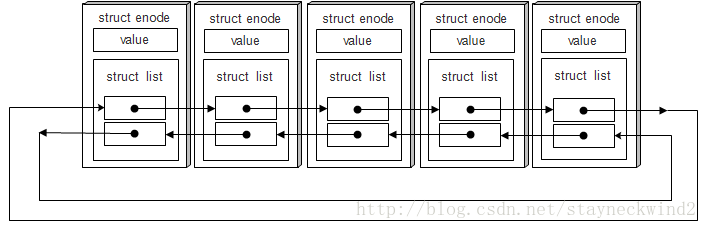
如我们定义一个结构 struct enode,把 struct list 包含进来,那么可以使用 list 成员进行下一个、上一个节点的查找;
struct enode {
int wd;
struct list_head list;
};
但也有一个问题,就是如第二节所示,list接口这块针对的是 struct list 结构的查找,即我们找到了 后继的 list位置,如何找到 enode的位置?
在Linux编译器中,提供了一个方法 container_of,可以通过结构体成员的地址 找到 结构体起始位置,实现如下:
#ifndef offsetof
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
#endif
#ifndef container_of
#define container_of(ptr, type, member) \
( { \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) ); \
} \
)
#endif再通过与结构体成员的地址相减,最终得出结构体的起始地址;

3.2 试验测试
说了这么多,把关键点给扫清楚了,下面可以给出使用方法了;
static int __elist_create(struct enode *phead)
{
if ( !phead ) {
return FAILURE;
}
INIT_LIST_HEAD(&phead->list);
return SUCCESS;
}
static int __elist_push(struct enode *phead, int wd)
{
struct enode *pnode = calloc(1, sizeof(struct enode));
if ( !pnode ) {
return FAILURE;
}
pnode->wd = wd;
list_add_tail(&pnode->list, &phead->list);
return SUCCESS;
}
static int __elist_traverse(struct enode *phead)
{
struct enode *pcurr = NULL;
if ( !phead ) {
return FAILURE;
}
list_for_each_entry(pcurr, &phead->list, list) {
printf("%d\n", pcurr->wd);
}
printf("-----------------------------\n");
return SUCCESS;
}
static int __elist_destroy(struct enode *phead)
{
struct enode *pcurr = NULL;
struct enode *pnext = NULL;
}static int __test_elist()
{
int ret = FAILURE;
struct enode head = {0};
ASSERT(SUCCESS, ret = __elist_create(&head));
ASSERT(SUCCESS, ret = __elist_push(&head, 1));
ASSERT(SUCCESS, ret = __elist_push(&head, 2));
ASSERT(SUCCESS, ret = __elist_push(&head, 3));
ASSERT(SUCCESS, ret = __elist_push(&head, 4));
ASSERT(SUCCESS, ret = __elist_traverse(&head));
ASSERT(SUCCESS, ret = __elist_destroy(&head));
_E1:
return ret;
}
int main(int argc, char *argv[])
{
int ret = FAILURE;
ASSERT(SUCCESS, ret = __test_elist());
_E1:
printf("Result:\t\t\t\t[%s]\n", ret ? "Failure" : "Success");
exit(ret ? EXIT_FAILURE : EXIT_SUCCESS);
}四、总结
本文介绍了如何使用内核的双向链表,为用户态编程提供了方便;
同时 container_of 方法可以把自己定义的接口抽象成与数据类型无关的,接口内部可以专注实现数据结构;
需要注意的是在编译过程中,加入-O1选项才能把 container_of 、inline 这些处理进行优化;
参考文章:
[1] https://www.ibm.com/developerworks/cn/linux/kernel/l-chain
[2] http://www.cnblogs.com/Anker/archive/2013/12/15/3475643.html














 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









