









一、Storm概述
Storm是一个分布式的、可靠的、零失误的流式数据处理系统。它的工作就是委派各种组件分别独立的处理一些简单任务。在Storm集群中处理输入流的是Spout组件,而Spout又把读取的数据传递给叫Bolt的组件。Bolt组件会对收到的数据元组进行处理,也有可能传递给下一个Bolt。我们可以把Storm集群想象成一个由bolt组件组成的链条集合,数据在这些链条上传输,而bolt作为链条上的节点来对数据进行处理。
Storm和Hadoop集群表面看上去很类似,但是Hadoop上面运行的是MapReduceJobs,而在Storm上运行的是拓扑topology,这两者之间是非常不一样的,关键区别是:MapReduce最终会结束,而一个topology永远会运行(除非你手动kill掉),换句话说,Storm是面向实时数据分析,而Hadoop面向的是离线数据分析。
![]()
![]()

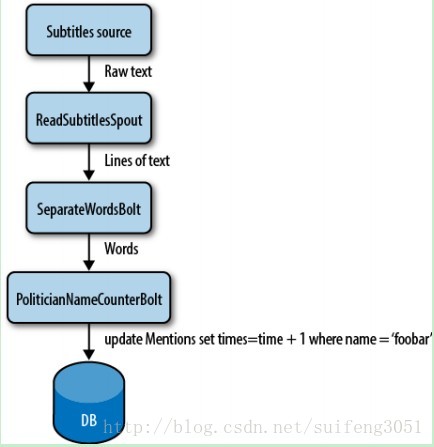
假设有这么一种情形,当你看政论类节目的时候,他们会经常提到一些人名和一些热门话题,如果我们把其中人名和话题的重复次数都记录下来,结果应该是一件很有趣的事情。
因此,想象在Storm环境下,我们可以把辩论者说的话作为输入流,spout组件来读取这些数据,然后把每一句话发送给bolt1组件,bolt1组件负责把这一句话拆分成一个个单词,再把这些单词发送到bolt2组件,bolt2组件负责统计每个单词的数量然后把这些信息存储到数据库中。辩论者在不断的说话,而storm不断的实时刷新数据库中结果,当你想查看这些结果时,你只需查询数据库即可。
现在,你可以想象如果可以把这些spout和bolt均衡分布到整个集群中,并且可以方便地做无限制的扩展,厉害吧?这就是Storm的威力!
图1.1:一个简单的Topology
Storm的一些典型应用场景
1.数据流处理:与其它流处理系统不同,storm不需要中间队列媒介
2.实时计算:可连续不断的进行实时数据处理,把处理的结果实时更新展示到客户端
3.分布式远程过程调用:可充分利用集群中CPU资源,进行CPU密集型计算。
二、Storm组件
集群中有两种类型的节点:主节点和工作节点
-
- master节点:运行Nimbus进程,负责分发代码,安排任务,监控运行状态(主要是节点成功失败状态)。
- worker节点:运行Supervisor进程,负责执行一个Topology的一个子集
图1.2:storm 集群中的组件:
Storm集群中的状态都保存在zookeeper或本地磁盘中,因此Storm中的进程都是无状态的,任何一个节点失败或重启都不会影响整个集群。Storm底层使用zeromq来保证其非凡的特性:
- 并发的socket 类
- 比TCP更快,适用于集群环境和超级计算
- 通过inproc、IPC、TCP和多路广播传输消息
- 异步IO
- Connect N-to-N via fanout,pubsub,pipeline,requst-reply
- 使用push/pull模式
三、Storm特性
- 编程简单:主要依赖于spout和bolt来实现
- 支持多种编程语言:基于JVM的语言都可以支持,任何一个其它语言只要实现了一个中间类也可支持
- 容错性高:运行宕机、重启等
- 可拓展:可以任意增删节点到集群
- 可靠性高:所有消息都被保证至少消费一次,也就是说,Storm中消息不会丢失
- 快速:快就不必多少了
- 事务支持
初步了解Storm之后,下一节会通过写一个简单的Demo运行一下来让大家真实体会一下Storm。














 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









