









一、Storm中运行的组件
我们知道,Storm的强大之处就是可以很容易地在集群中横向拓展它的计算能力,它会把整个运算过程分割成多个独立的tasks在集群中进行并行计算。在Storm中,一个task就是运行在集群中的一个Spout或Bolt实例。
![]()

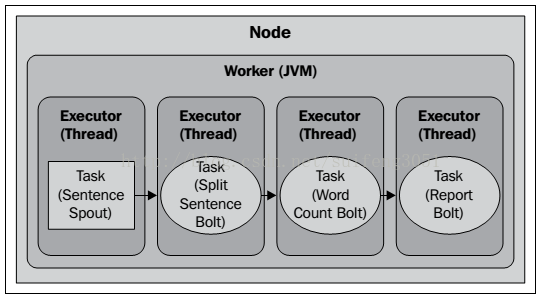
为了方便理解Storm如何并行处理我们分给它的任务,这里我先介绍一下在集群中涉及到Topology的四种组件:
- Nodes(machines):集群中的节点,就是这些节点一起工作来执行Topology。
- Workers(JVMs):一个worker就是一个独立的JVM进程。每个节点都可以通过配置运行一个或多个workers,一个Topology可以指定由多少个workers来执行。
- Executors(threads):一个worker JVM中运行的线程。一个worker进程可以执行一个或多个executor线程。一个Executor可以运行多个tasks,Storm默认一个每个executor分配一个task。
- Tasks(bolt/spout实例):Tasks就是spouts和bolts的实例,它具体是被executor线程处理的。
二、Storm中的并行(以WordCountTopology为例)
我们可以通过配置来调整我们work的并行数量,如果我们不进行设置,
Storm默认大部分过程的并行数量为1。假设我们对WordCountTopology不单独进行配置,那么我们的Topology执行情况如下图所示:
我们的一个节点会为我们的Topology分配一个worker,这个worker会为每个Task启动一个Executor线程。
2.1 为Topology增加workers
一种最简单的提高Topology运算能力的途径就是为我们的Topology增加workers。Storm为我们提供了两种途径来增加workers:通过配置文件或通过程序设置。
- 描述:在集群中为topology创建多少个工作进程
- 配置选项: TOPOLOGY_WORKERS
- 在代码中配置:
通过Config对象来配置workers:
Config config = new Config();
config.setNumWorkers(2);
注意:在LocalMode下不管设置几个workers,最终都只有一个worker JVM进程。
2.2 配置executors和tasks
前面我们已经说过,Storm会为每个Topology组件创建一个task,而默认一个executor只处理一个task。task是spouts和bolts的实例,一个executor线程可由处理多个tasks,tasks是真正处理具体数据的一个过程,我们在代码中写的spout和bolt可以看做是由集群中分布的tasks来执行的。Task的数量在整个topology运行期间一般是不变的,但是组件的Executors是有可能发生变化的。这也就意味着:threads<=tasks。
2.2.1 设置executor(thread)数量
通过设置parallelism hint来指定一个组件的executors。
- 描述:每个组件产生多少个Executor
- 配置选项:?
- 在代码中配置:
- TopologyBuilder#setSpout()
- TopologyBuilder#setBolt()
- Note that as of Storm 0.8 the
parallelism_hintparameter now specifies the initial number of executors (not tasks!) for that bolt.
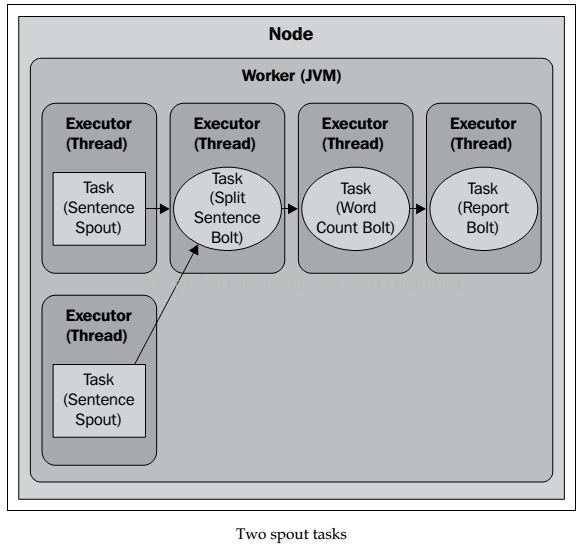
下面我们指定SentenseSpout的并行数量为2,则这个Spout组件会有两个executors,每个executor分配一个task,其Topology的运行情况如下图所示:
builder.setSpout(SENTENCE_SPOUT_ID, spout,
2
);
2.2.2 设置task的数量
通过setNumTasks()方法来指定一个组件的tasks数量。
- 描述:每个组件创建多少个task
- 配置选项: TOPOLOGY_TASKS
- 在代码中配置:
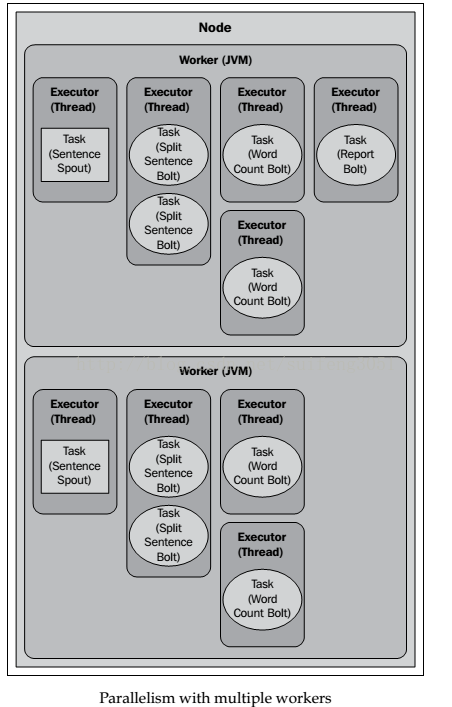
下面我们为
SplitSentenceBolt 设置4个tasks和2个executors,这样的话每个executor线程将被分配执行4/2=2个tasks,然后再为WordCountBolt分配4个task,每个task由一个executor负责执行。其Topology如下图所示:
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
builder.setBolt(COUNT_BOLT_ID, countBolt, 4).fieldsGrouping(SPLIT_BOLT_ID, newFields("word"));
如果一开始分配2个workers,则Topology的运行情况如下图所示:
三、一个topology的例子
下面这幅图展示了一个实际topology的全景,topology由三个组件组成,一个Spout:BlueSpout,两个Bolt:GreenBolt、YellowBolt。
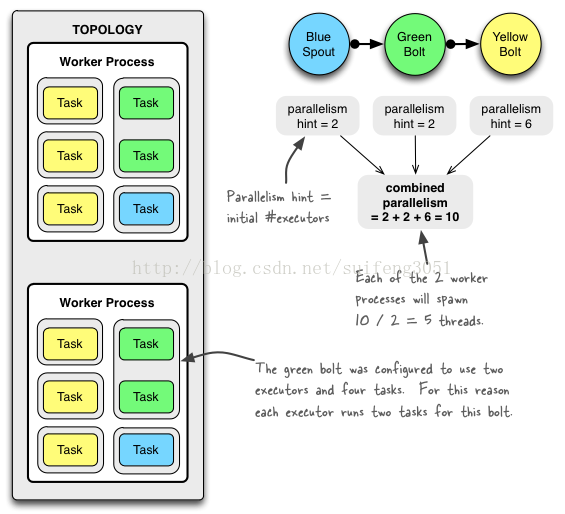
如上图,我们配置了两个worker进程,两个Spout线程,两个GreenBolt线程和六个YellowBolt线程,那么分布到集群中的话,每个工作进程都会有5个executor线程。下面看一下具体代码:
java Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout(“blue-spout”, new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt(“green-bolt”, new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping(“blue-spout”);
topologyBuilder.setBolt(“yellow-bolt”, new YellowBolt(), 6) .shuffleGrouping(“green-bolt”);
StormSubmitter.submitTopology( “mytopology”, conf, topologyBuilder.createTopology() );
当然,Storm中也有一个参数来控制topology的并行数量:
- TOPOLOGY_MAX_TASK_PARALLELISM: 这个参数可以控制一个组件上Executor的最大数量。它通常用来在本地模式测试topology的最大线程数量。当然我们也可以在代码中设置: Config#setMaxTaskParallelism().
四、如何改变一个运行topology中的Parallelism
Storm中一个很好的特性就是可以在topology运行期间动态调制worker进程或Executor线程的数量而不需要重启topology。这种机制被称作rebalancing。
我们有两种方式来均衡一个topology:
- 通过Storm web UI来均衡
- 通过CLI tool storm 来均衡
下面就是一个CLI tool应用的例子:
# Reconfigure the topology “mytopology” to use 5 worker processes, # the spout “blue-spout” to use 3 executors and # the bolt “yellow-bolt” to use 10 executors.
$ storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10














 5293
5293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









