一、下载与安装
Elasticsearch 依赖 Java,在安装 ES 之前首先要配好 java,这个默认我们的电 脑已经完成。Elasticsearch要求jdk最低版本为1.7。
首先从 elasticsearch官网下载安装包,我们是 Linux 系统,下载 tar 包比较方便。当前版本为2.3.3,下载地址:Elasticsearch 2.3.3下载
.下载完成之后解压tar文件:
tar -zxvf elasticsearch-2.3.3.tar.gz
二、运行ElasticSearch
启动ElasticSearch命令:
./elasticsearch-2.3.3/bin/elasticsearch
如果一切顺利,会收到类似于如下的信息:
[2016-06-18 15:07:50,106][INFO ][node ] [Maynard Tiboldt] version[2.3.3], pid[7390], build[218bdf1/2016-05-17T15:40:04Z]
[2016-06-18 15:07:50,106][INFO ][node ] [Maynard Tiboldt] initializing ...
[2016-06-18 15:07:50,590][INFO ][plugins ] [Maynard Tiboldt] modules [reindex, lang-expression, lang-groovy], plugins [], sites []
[2016-06-18 15:07:50,609][INFO ][env ] [Maynard Tiboldt] using [1] data paths, mounts [[/ (/dev/disk1)]], net usable_space [85.6gb], net total_space [111.8gb], spins? [unknown], types [hfs]
[2016-06-18 15:07:50,609][INFO ][env ] [Maynard Tiboldt] heap size [990.7mb], compressed ordinary object pointers [true]
[2016-06-18 15:07:50,610][WARN ][env ] [Maynard Tiboldt] max file descriptors [10240] for elasticsearch process likely too low, consider increasing to at least [65536]
[2016-06-18 15:07:52,323][INFO ][node ] [Maynard Tiboldt] initialized
[2016-06-18 15:07:52,323][INFO ][node ] [Maynard Tiboldt] starting ...
[2016-06-18 15:07:52,401][INFO ][transport ] [Maynard Tiboldt] publish_address {127.0.0.1:9300}, bound_addresses {[fe80::1]:9300}, {[::1]:9300}, {127.0.0.1:9300}
[2016-06-18 15:07:52,406][INFO ][discovery ] [Maynard Tiboldt] elasticsearch/OawW12ZERyO3CuQrt7SmFQ
[2016-06-18 15:07:55,445][INFO ][cluster.service ] [Maynard Tiboldt] new_master {Maynard Tiboldt}{OawW12ZERyO3CuQrt7SmFQ}{127.0.0.1}{127.0.0.1:9300}, reason: zen-disco-join(elected_as_master, [0] joins received)
[2016-06-18 15:07:55,456][INFO ][http ] [Maynard Tiboldt] publish_address {127.0.0.1:9200}, bound_addresses {[fe80::1]:9200}, {[::1]:9200}, {127.0.0.1:9200}
[2016-06-18 15:07:55,457][INFO ][node ] [Maynard Tiboldt] started
[2016-06-18 15:07:55,476][INFO ][gateway ] [Maynard Tiboldt] recovered [0] indices into cluster_state
这样就运行起来了一个节点。(可以多开几个终端,运行起来集群名相同的节点都 在一个集群中).
注意一下有 http 标记的那一行,它提供了有关 HTTP 地址(127.0.0.1)和 端口(9200)的信息,通过这个地址和端口我们就可以访问我们的节点了。默认情况下, Elasticsearch 使用 9200 来提供对其 REST API 的访问。
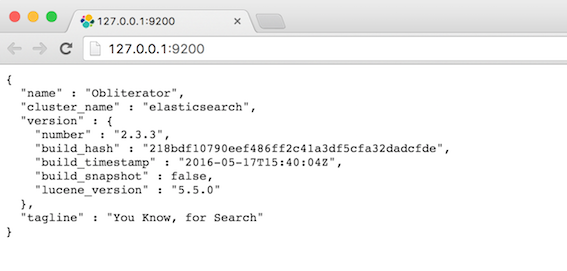
访问http://127.0.0.1:9200/,浏览器会输出如下信息:
{
"name" : "Obliterator",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "2.3.3",
"build_hash" : "218bdf10790eef486ff2c41a3df5cfa32dadcfde",
"build_timestamp" : "2016-05-17T15:40:04Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}
如果想通过服务器ip访问es,打开elasticsearch-2.3.3/config/elasticsearch.yml,找到Network部分:
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
# network.host: 192.168.0.1
#
# Set a custom port for HTTP:
#
# http.port: 9200
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html>
#
把network.host: 192.168.0.1前的注释去掉并修改为network.host: 0.0.0.0
重启es上面返回的信息中 http 部分也会变成真实本机地址,可以通过本机真实ip:9200 访问es。
三、关闭ElasticSearch
需要对ES节点进行重新启动或正常关机的时候,有三种方法可以关闭ES:
- 在控制台中,使用CTRL+C组合键.
- 通过发送TERM信号终止服务器进程.
- 使用REST API
curl -XPOST 'http://localhost:9200/_shutdown'.
四、插件安装
4.1安装head 插件
安装命令:
./elasticsearch-2.3.3/bin/plugin install mobz/elasticsearch-head
安装好后,在浏览器输入地址:http://localhost:9200/_plugin/head/ 即可调用 head 插件 查看集群状态、节点信息、做查询等等。
4.2安装IK分词器
(a).首先使用Git clone命令下载IK分词器源码
git clone https:
也可以直接访问github地址(https://github.com/medcl/elasticsearch-analysis-ik)点击右侧Clone or download按钮,然后Download ZIP直接下载.
(b.)解压下载的elasticsearch-analysis-ik-master.zip.
unzip elasticsearch-analysis-ik-master.zip
(c.)使用maven打包
确保系统已经安装maven,使用mvn -version命令查看是否已经安装maven.如果没有安装,可以根据系统选择安装方法,比如mac OS系统可以使用brew install maven命令完成安装.
进入ik分词器的下载目录,运行命令:
mvn package
打包完成以后可以看到根目录下多出一个target文件夹.
(d.) 配置Ik插件
在elasticsearch-2.3.3/plugins/目录下新建名为ik的文件夹.把elasticsearch-analysis-ik-master/target/releases
/elasticsearch-analysis-ik-1.9.3.zip解压,把解压后的所有文件拷贝到elasticsearch-2.3.3/plugins/ik/目录下.
重新启动es,如果配置正确,不会有异常信息输出。
(e.)ik 分词测试
1.首先创建一个索引用于测试:
curl -XPUT localhost:9200/index
2.为索引index创建mapping:
curl -XPOST http:
{
"fulltext": {
"_all": {
"analyzer": "ik"
},
"properties": {
"content": {
"type" : "string",
"boost" : 8.0,
"term_vector" : "with_positions_offsets",
"analyzer" : "ik",
"include_in_all" : true
}
}
}
}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.测试:
curl 'http://localhost:9200/index/_analyze?analyzer=ik&pretty=true' -d '
{
"text":"中国有13亿人口"
}'
显示结果如下:
{
"tokens" : [ {
"token" : "中国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
}, {
"token" : "国有",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
}, {
"token" : "13",
"start_offset" : 3,
"end_offset" : 5,
"type" : "ARABIC",
"position" : 2
}, {
"token" : "亿",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
}, {
"token" : "人口",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 4
} ]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
五、文档的CRUD
5.1索引、类型、文档、字段
- 索引是ElasticSearch存放数据的地方,可以理解为关系型数据库中的一个数据库。
- 类型用于区分同一个索引下不同的数据类型,相当于关系型数据库中的表
- 文档是ElasticSearch中存储的实体,类比关系型数据库,每个文档相当于数据库表中的一行数据。
- 文档由字段组成,相当于关系数据库中列的属性,不同的是ES的不同文档可以具有不同的字段集合。
对比关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
5.2 创建文档
以博客内容管理为例,索引名为blog,类型为article,新加一个文档:
curl -XPUT http:
{
"id": "1",
"title": "New version of Elasticsearch released!",
"content": "Version 1.0 released today!",
"priority": 10,
"tags": ["announce", "elasticsearch", "release"]
}'
5.3检索文档
http://localhost:9200/blog/article/1?pretty
5.4更新文档
curl -XPOST http:
"script": "ctx._source.content = \"new content\""
}'
5.5删除文档
curl -XDELETE http://localhost:9200/blog/article/1
六、相关概念
6.1节点与集群
ElasticSearch是一个分布式全文搜索引擎,既可以做为一个独立的搜索服务器工作,也可以使用多台服务器同时运行,这样就构成了一个集群(cluster),集群的每一个服务器称为一个节点(node).
6.2分片
当数据量比较大的时候,受RAM、硬盘容量的限制,同时一个节点的计算能力有限。可以将数据切分,每部分是一个单独的lucene索引,成为分片(shard)。每个分片可以被存储在集群的不同节点上。当需要查询由多个分片构成的索引时,ElasticSearch将查询发送到每个相关的分片,之后将查询结果合并。过程对应用透明,无须知道分片的存在。
6.3副本
副本是对原始分片的一个精确拷贝,原始分片成为主分片。对索引的所有操作都直接作用在主分片上,每个主分片可以有零个或多个副分片。主分片丢失,集群可以将一个副分片提升为主的新分片。
转载地址:http://blog.csdn.net/napoay/article/details/51705902






















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









