







 本文详细介绍了如何在TensorFlow 0.8中进行分布式部署,包括创建集群、任务分配、设备指定等步骤。通过实例展示了分布式训练的过程,强调了数据并行化、异步和同步训练策略。同时,解释了客户端、集群、作业、任务等核心概念。
本文详细介绍了如何在TensorFlow 0.8中进行分布式部署,包括创建集群、任务分配、设备指定等步骤。通过实例展示了分布式训练的过程,强调了数据并行化、异步和同步训练策略。同时,解释了客户端、集群、作业、任务等核心概念。
tensorflow-0.8 的一大特性为可以部署在分布式的集群上,本文的内容由Tensorflow的分布式部署手册翻译而来,该手册链接为TensorFlow分布式部署手册
分布式TensorFlow
本文介绍了如何搭建一个TensorFlow服务器的集群,并将一个计算图部署在该分布式集群上。以下操作建立在你对 TensorFlow的基础操作已经熟练掌握的基础之上。
Hello world的分布式实例的编写
以下是一个简单的TensorFlow分布式程序的编写实例
# Start a TensorFlow server as a single-process "cluster".
$ python
>>> import tensorflow as tf
>>> c = tf.constant("Hello, distributed TensorFlow!")
>>> server = tf.train.Server.create_local_server()
>>> sess = tf.Session(server.target) # Create a session on the server.
>>> sess.run(c)
'Hello, distributed TensorFlow!'tf.train.Server.create_local_server() 会在本地创建一个单进程集群,该集群中的服务默认为启动状态。
创建集群(cluster)
TensorFlow中的集群(cluster)指的是一系列能够对TensorFlow中的图(graph)进行分布式计算的任务(task)。每个任务是同服务(server)相关联的。TensorFlow中的服务会包含一个用于创建session的主节点和一个用于图运算的工作节点。另外, TensorFlow中的集群可以拆分成一个或多个作业(job), 每个作业可以包含一个或多个任务。下图为作者对集群内关系的理解。
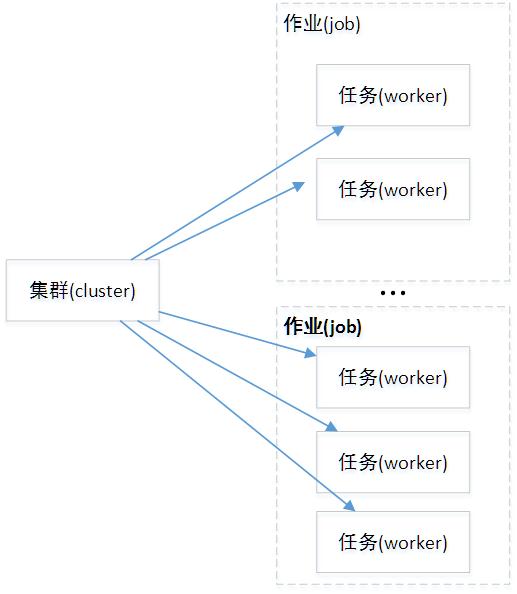
创建集群的必要条件是为每个任务启动一个服务。这些任务可以运行在不同的机器上,但你也可以在同一台机器上启动多个任务(比如说在本地多个不同的GPU上运行)。每个任务会做如下的两步工作:
- 创建一个
tf.train.ClusterSpec用于对集群中的所有任务进行描述,该描述内容对于所有任务应该是相同的。 - 创建一个
tf.train.Server并将tf.train.ClusterSpec中的参数传入构造函数,并将作业的名称和当前任务的编号写入本地任务中。
创建tf.train.ClusterSpec 的具体方法
tf.train.ClusterSpec 的传入参数是作业和任务之间的关系映射,该映射关系中的任务是通过ip地址和端口号表示的。具体映射关系如下表所示:
tf.train.ClusterSpec construction |
Available tasks |
|---|---|
tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
|
/job:local/task:0 local |
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222"
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222"
]})
|
/job:worker/task:0/job:worker/task:1/job:worker/task:2/job:ps/task:0/job:ps/task:1 |
为每一个任务创建tf.train.Server 的实例
每一个tf.train.Server 对象都包含一个本地设备的集合, 一个向其他任务的连接集合,以及一个可以利用以上资源进行分布式计算的“会话目标
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









