






一、问题的产生
通过RegionLoad可以获得一系列有关Region负载的详细信息,但是因为需要通过regionName与HRegionInfo中的regionName匹配,从而合并相关信息(保存的时候没有保存字节数组的regionName,太长了并且不直观,同时还需要clusterName信息,以保证其唯一性),所以也正因为如此,才带来了标题中的问题。
由于每次抓取的Region数量在一两万左右,所以在开始获取RegionLoad中的数据时,并没有太关注regionName是否乱码(只有少部分regionName乱码,其中大多是由phoenix引起的,并且在数据库中乱码的数据有可能会被截断),后来需要获取HRegionInfo中的数据时,尝试使用regionName进行一一对应匹配,却很多都无法匹配上。
二、原因分析
RegionLoad提供了getNameAsString()方法获取regionName,同时HRegionInfo也提供了getRegionNameAsString()方法获取regionName,从方法名上看两个方法似乎没有差异,但是查看源码就会发现两个方法其实是不一样的,RegionLoad.getNameAsString()源码如下:
public String getNameAsString() {
return Bytes.toString(getName());
}HRegionInfo.getRegionNameAsString()源码如下:
public String getRegionNameAsString() {
if (hasEncodedName(this.regionName)) {
// new format region names already have their encoded name.
return Bytes.toStringBinary(this.regionName);
}
// old format. regionNameStr doesn't have the region name.
//
//
return Bytes.toStringBinary(this.regionName) + "." + this.getEncodedName();
}regionName在RegionLoad与HRegionInfo对象中都是以byte[]方式存储的,在调用**NameAsString()方法时,通过org.apache.hadoop.hbase.util.Bytes类中的方法进行转换,但是RegionLoad.getNameAsString()是通过Bytes.toString(…),而HRegionInfo.getRegionNameAsString()是通过Bytes.toStringBinary(…),两个方法的源码如下:
public static String toString(final byte [] b) {
if (b == null) {
return null;
}
return toString(b, 0, b.length);
}
public static String toString(final byte [] b, int off, int len) {
if (b == null) {
return null;
}
if (len == 0) {
return "";
}
return new String(b, off, len, UTF8_CHARSET); // UTF8_CHARSET = "UTF-8"
}public static String toStringBinary(final byte [] b) {
if (b == null)
return "null";
return toStringBinary(b, 0, b.length);
}
public static String toStringBinary(final byte [] b, int off, int len) {
StringBuilder result = new StringBuilder();
// Just in case we are passed a 'len' that is > buffer length...
if (off >= b.length) return result.toString();
if (off + len > b.length) len = b.length - off;
for (int i = off; i < off + len ; ++i ) {
int ch = b[i] & 0xFF;
if ( (ch >= '0' && ch <= '9')
|| (ch >= 'A' && ch <= 'Z')
|| (ch >= 'a' && ch <= 'z')
|| " `~!@#$%^&*()-_=+[]{}|;:'\",.<>/?".indexOf(ch) >= 0 ) {
result.append((char)ch);
} else {
result.append(String.format("\\x%02X", ch));
}
}
return result.toString();
}其中,Bytes.toString(…)只是单纯的将字节数组按照UTF-8编码的方式进行转换,这就导致很多一些不存在于UTF-8编码中的特殊字符是无法显示的,或显示成了莫名其妙的符号,而这些无法显示的或莫名奇妙的符号在数据库中却很可能是无法保存的(SQL SERVER中,‘\x00’代表的字符会被认为是截断,其后的数据都无法保存,粘贴在SQL窗口都不行),而Bytes.toStringBinary(…)中,则将那些无法乱七八糟的字符以\x%02X(%02X会被替换成2位字符组成的字符串,类似但会超出16进制的表示范围)显示,所以我们能看到像下面的这种名称:
SYSTEM.SEQUENCE,$\x00\x00\x00,1462415795146.fdbe7e16cba9380494f07a61ac465879.像’$’这种能正常显示的也就显示了,而‘\x00’则代表了一种特殊的可能无法显示的字符(这里是NULL),具体的对应关系可参见下表:
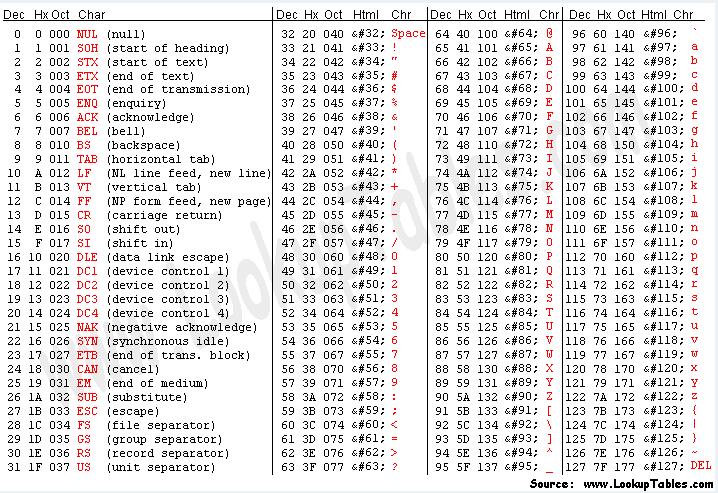
(图片来源:http://www.asciitable.com/)
其中,\x%02X中的%02X对应Hx列。
三、解决方案
那么至此,问题也就好解决了,只要在使用RegionLoad获取regionName时使用如下方法:
String regionName = Bytes.toStringBinary(regionLoad.getName());此时,再对比通过RegionLoad与HRegionInfo对象获取的regionName时,便能一一对应了,并且不会乱码了。
以上。















 2868
2868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









