




 本文介绍了Spark的基本概念,包括Spark的内存计算优势、安装与运行示例。重点讲解了创建RDD的两种方式:引用外部数据集和并行化驱动程序中的集合,并通过代码示例展示了在Java 1.7和1.8中创建RDD的差异。此外,还提到了RDD的操作和共享变量的概念。
本文介绍了Spark的基本概念,包括Spark的内存计算优势、安装与运行示例。重点讲解了创建RDD的两种方式:引用外部数据集和并行化驱动程序中的集合,并通过代码示例展示了在Java 1.7和1.8中创建RDD的差异。此外,还提到了RDD的操作和共享变量的概念。
首先看看思维导图,我的spark是1.6.1版本,jdk是1.7版本
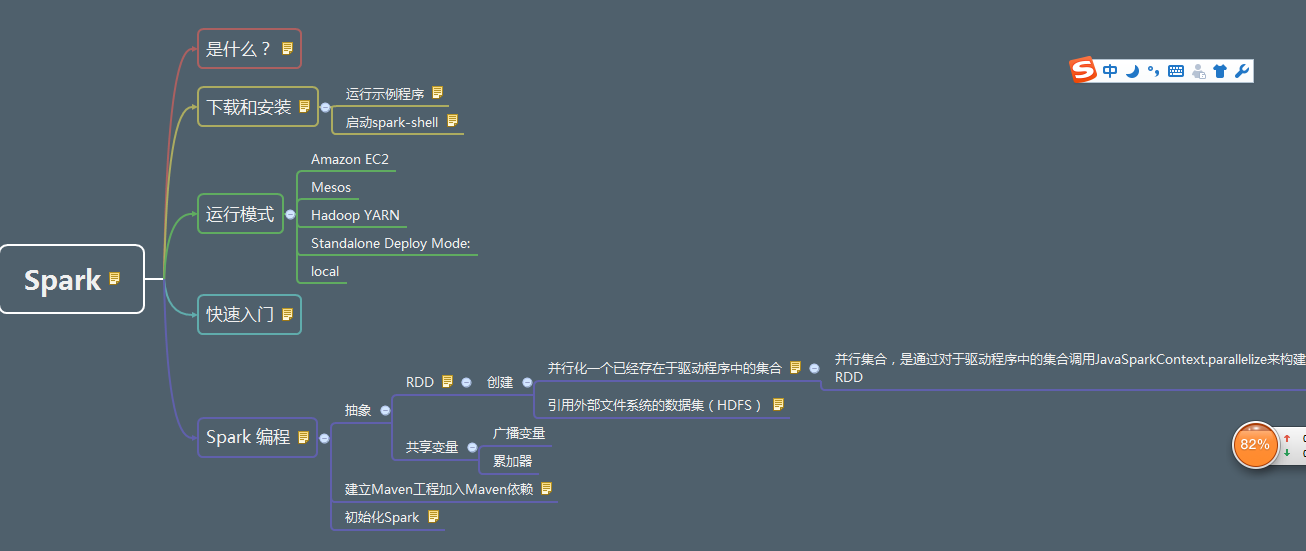
spark是什么?
Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark 部署在大量廉价硬件之上,形成集群。
下载和安装
可以看我之前发表的博客
Spark安装
安装成功后运行示例程序
在spark安装目录下examples/src/main目录中。 运行的一个Java或Scala示例程序,使用bin/run-example <class> [params]
./bin/run-example SparkPi 10启动spark-shell时的参数
./bin/spark-shell –master local[2]
参数master 表名主机master在分布式集群中的URL
local【2】 表示在本地通过开启2个线程运行
运行模式
四种:
1.Mesos
2.Hadoop YARN
3.spark
4.local
一般我们用的是local和spark模式
首先建立maven工程加入整个项目所用到的包的maven依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>sparkday01</groupId>
<artifactId>sparkday01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>sparkday01</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactI 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2207
2207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









