







最近在研究Hadoop,发现网上的一些关于Hadoop的资料都是以前的1.X版本的,包括MapReduce的工作原理,都是以前的一些过时了的东西,所以自己重新整理了一些新2.X版本的MapReduce的工作原理
下面我画了一张图,便于理解MapReduce得整个工作原理
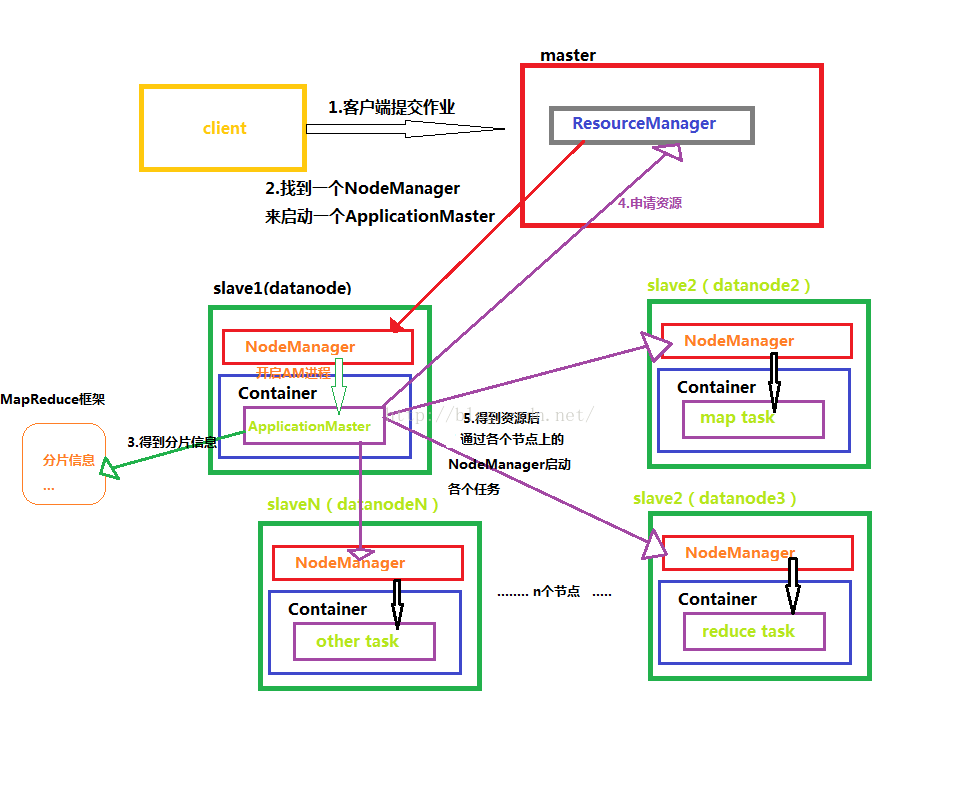
下面对上面出现的一些名词进行介绍
ResourceManager:是YARN资源控制框架的中心模块,负责集群中所有的资源的统一管理和分配。它接收来自NM(NodeManager)的汇报,建立AM,并将资源派送给AM(ApplicationMaster)。
NodeManager:简称NM,NodeManager是ResourceManager在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager提供这些资源使用报告。
ApplicationMaster:以下简称AM。YARN中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动container,并告诉container做什么事情。
Container:资源容器。YARN中所有的应用都是在container之上运行的。AM也是在container上运行的,不过AM的container是RM申请的。
3. Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以是任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
(1) 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
(2) 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
整个MapReduce的过程大致分为 Map-->Shuffle(排序)-->Combine(组合)-->Reduce
下面通过一个单词计数案例来理解各个过程
1)将文件拆分成splits(片),并将每个split按行分割形成<key,value>对,如图所示。这一步由MapRedu
下面我画了一张图,便于理解MapReduce得整个工作原理
下面对上面出现的一些名词进行介绍
ResourceManager:是YARN资源控制框架的中心模块,负责集群中所有的资源的统一管理和分配。它接收来自NM(NodeManager)的汇报,建立AM,并将资源派送给AM(ApplicationMaster)。
NodeManager:简称NM,NodeManager是ResourceManager在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager提供这些资源使用报告。
ApplicationMaster:以下简称AM。YARN中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动container,并告诉container做什么事情。
Container:资源容器。YARN中所有的应用都是在container之上运行的。AM也是在container上运行的,不过AM的container是RM申请的。
1. Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。
2. Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster;3. Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以是任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,一个应用程序所需的Container分为两大类,如下:
(1) 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
(2) 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
整个MapReduce的过程大致分为 Map-->Shuffle(排序)-->Combine(组合)-->Reduce
下面通过一个单词计数案例来理解各个过程
1)将文件拆分成splits(片),并将每个split按行分割形成<key,value>对,如图所示。这一步由MapRedu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7318
7318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









