







 本文深入探讨了Spark MLlib中基于GraphX实现的LDA(Latent Dirichlet Allocation)原理,对比了LightLDA、plda、plda+以及Spark LDA在处理大规模语料库的能力和收敛速度。Spark LDA利用GraphX进行分布式训练,通过GraphX的aggregateMessages方法进行消息传递和顶点更新,但在大规模数据下由于shuffle操作导致性能瓶颈。
本文深入探讨了Spark MLlib中基于GraphX实现的LDA(Latent Dirichlet Allocation)原理,对比了LightLDA、plda、plda+以及Spark LDA在处理大规模语料库的能力和收敛速度。Spark LDA利用GraphX进行分布式训练,通过GraphX的aggregateMessages方法进行消息传递和顶点更新,但在大规模数据下由于shuffle操作导致性能瓶颈。
LDA背景
LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火、最有力的模型之一,它能通过多轮迭代把特征向量集合按主题分类。目前,广泛运用在文本主题聚类中。
LDA的开源实现有很多。目前广泛使用、能够分布式并行处理大规模语料库的有微软的LightLDA,谷歌plda、plda+,sparkLDA等等。下面介绍这3种LDA:
LightLDA依赖于微软自己实现的multiverso参数服务器,服务器底层使用mpi或zeromq发送消息。LDA模型(word-topic矩阵)由参数服务器保存,它为文档训练进程提供参数查询、更新服务。
plda、plda+使用mpi消息通信,将mpi进程分为word、doc俩部分。doc进程训练文档,word进程为doc进程提供模型的查询、更新功能。
spark LDA有两种实现:1.基于gibbs sampling原理和使用GraphX实现的版本(即spark文档上所说的EMLDAOptimizer and DistributedLDAModel),2.基于变分推断原理实现的版本(即spark文档上的OnlineLDAOptimizer and LocalLDAModel)。
LightLDA,plda、plda+,spark LDA比较
论能够处理预料库的规模大小,LihgtLDA要远远好于plda和spark LDA
经过测试,在10个服务器(8核40GB)集群规模下:
LihgtLDA能够处理上亿文档、百万词汇的语料库,能够训练上百万主题数。这样的处理能力使得LihgtLDA能够轻松训练绝大多数语料库。微软号称使用几十机器的集群便能训练Bing搜索引擎爬下数据的十分之一。
相对于LihgtLDA ,plda+能够处理规模小的多,上限是:词汇数目*主题数(模型大小) < 5亿。当语料库规模达到上限后,mpi集群会因内存不够而终止,或因为内存数据频繁切换,迭代速度十分缓慢。虽然plda+对语料库的词汇数目和训练的主题数目很敏感,但对文档的规模并不是很敏感,在词汇数目和主题数目较小的情况下,1000万级别的文档也能够轻松解决。
spark LDA的GraphX版处理规模衡量标准是图的顶点数据,即(文档数 + 词汇数目)*主题数目,上限是 文档数*主题数 < 50亿(由于词汇数目相对于文档数目往往较小,近似等于 文档数*主题数)。当超过这个规模后,spark集群进入假死状态。不停有节点出现OOM,直至任务以失败告终。
变分推断实现的spark LDA瓶颈是 词汇数目*主题数目,这个值也就是我们所说的模型大小,上限约1亿。为什么存在这个瓶颈呢?是因为变分推断的实现过程中,模型使用矩阵本地存储,各个分区计算模型的部分值,然后在driver上将矩阵reduce叠加。当模型过大,driver节点的内存就无法承受各个分区发过来的模型。
收敛速度上,LightLDA要远快于plda、plda+和spark LDA。小规模语料库(30万文档,10万词,1000主题)测试,LightLDA : plda+ : spark LDA(graphx) = 1:4:50
为什么各种LDA的能够处理语料库规模的衡量标准不一样呢?这与它们的实现方式有关,不同的LDA有不同的瓶颈,我们这里单讲spark LDA,其他lda后续介绍。
spark LDA
spark机器学习库MLlib实现了2个版本的LDA,这里分别叫做Spark EM LDA和Spark Online LDA。它们使用同样的数据输入,但是内部的实现和依据的原理完全不同。Spark EM LDA使用GraphX实现的,通过对图的边和顶点数据的操作来训练模型。而Spark Online LDA采用抽样的方式,每次抽取一些文档训练模型,通过多次训练,得到最终模型。在参数估计上,Spark EM LDA使用gibbs采样原理估计模型参数,Spark Online LDA使用贝叶斯变分推断原理估计参数。在模型存储上,Spark EM LDA将训练的主题-词模型存储在GraphX图顶点上,属于分布式存储方式。Spark Online使用矩阵来存储主题-词模型,属于本地模型。通过这些差异,可以看出Spark EM LDA和Spark Online LDA的不同之处,同时他们各自也有各自的瓶颈。Spark EM LDA在训练时shuffle量相当大,严重拖慢速度。而Spark Online LDA使用矩阵存储模型,矩阵规模直接限制训练文档集的主题数和词的数目。另外,Spark EM LDA每轮迭代完毕后更新模型,Spark Online LDA每训练完抽样的文本更新模型,因而Spark Online LDA模型更新更及时,收敛速度更快。
Spark EM LDA之GraphX实现原理
Spark EM LDA基于gibbs采样原理估计参数,凡是基于gibbs采样原理推断参数的LDA训练过程大都如下:

LDA中文档里的每个词都属于一个主题,LDA训练过程的大体思路是,一轮迭代中,为每篇文档里的每一个词重新选择主题,选择的依据是gibbs采样公式,详细原理参见Parameter estimation for text analysis这篇文章。

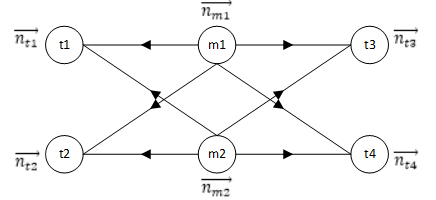
LDA实现算法的核心是,为每篇文档的每个词重新选取主题。这个过程GraphX做了巧妙的实现,它以文档到词作为边,以词频作为边数据,把语料库构造成图,把对语料库中每篇文档的每个词操作转化为在图中每条边上的操作,而对边RDD处理是GraphX中最常见的的处理方法。
GraphX把 nkm 、 nkt 矩阵存储在文档顶点和词顶点上,把词频信息存储在边上。它把整个文档聚类结果矩阵、模型矩阵和语料库词频矩阵都表达在图结构中,把LDA算法处理过程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









