







DOM和SAX
W3C制定了一套书写XML分析器的标准接口规范--DOM。
除此之外,XML_DEV邮件列表中的成员根据应用的需求也自发地定义了一套对XML文档进行操作的接口规范--SAX。这两种接口规范各有侧重,互有长短,应用都比较广泛。
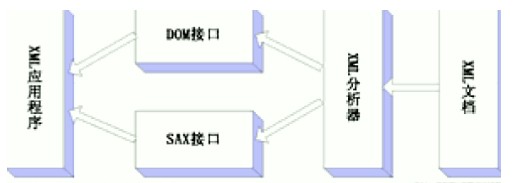
下面,我们给出DOM和SAX在应用程序开发过程中所处地位的示意图。从图中可以看出,应用程序不是直接对XML文档进行操作的,而是首先由XML分析器对XML文档进行分析,然后,应用程序通过XML分析器所提供的DOM接口或SAX接口对分析结果进行操作,从而间接地实现了对XML文档的访问。
DOM
DOM的全称是Document Object Model,也即文档对象模型。在应用程序中,基于DOM的XML分析器将一个XML文档转换成一个对象模型的集合(通常称DOM树),应用程序正是通过对这个对象模型的操作,来实现对XML文档数据的操作。通过DOM接口,应用程序可以在任何时候访问XML文档中的任何一部分数据,因此,这种利用DOM接口的机制也被称作随机访问机制。
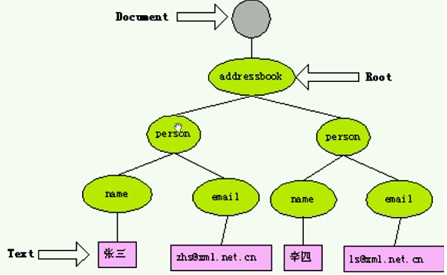
DOM接口提供了一种通过分层对象模型来访问XML文档信息的方式,这些分层对象模型依据XML的文档结构形成了一棵节点树。无论XML文档中所描述的是什么类型的信息,即便是制表数据、项目列表或一个文档,利用DOM所生成的模型都是节点树的形式。也就是说,DOM强制使用树模型来访问XML文档中的信息。由于XML本质上就是一种分层结构,所以这种描述方法是相当有效的。
DOM树所提供的随机访问方式给应用程序的开发带来了很大的灵活性,它可以任意的控制整个XML文档中的内容。然而由于DOM分析器把整个XML文档转化成DOM树放在内存中,因此,当文档比较大或者结构比较复杂时,对内存的需求就比较高。而且,对于结构复杂的树的遍历也是一项耗时的操作。所以,DOM分析器对机器性能的要求比较高,实现效率不十分理想。不过,由于DOM分析器所采用的树结构的思想与XML文档的结构相吻合,同时鉴于随访访问所带来的方便,因此,DOM分析器还是有很广泛的使用价值的。
DOM的四个基本接口
文档对象模型利用对象来把文档模型化,这些模型不仅描述了文档的机构,还定义了模型中对象的行为。换句话说,在上面给出的例子里,图中的节点不是数据结构,而是对象,对象中包含方法和属性。在DOM中,对象模型要实现:
Ø 用来表示。操作文档的接口
Ø 接口的行为和属性
Ø 接口之间的关系以及互操作
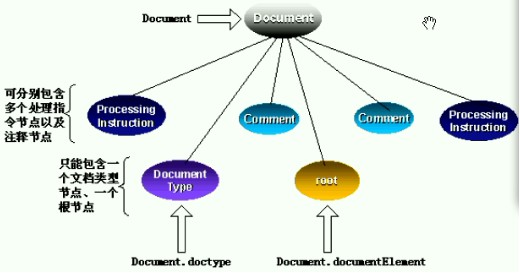
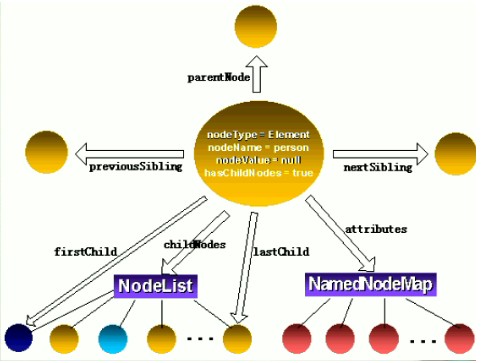
在DOM接口规范中,有四个基本的额接口:Document,Node,NodeList以及NamedNodeMap。这这四个基本接口中,Document接口是对文档进行操作的入口,它是从Node接口继承过来的。Node接口是其它大多数接口的父类,像Document,Element,Attribute,Text,Comment等接口都是从Node接口继承过来的。NodeList接口是一个节点的集合,通过该接口,可以建立节点和节点之间的一一映射关系,从而利用节点名可以直接访问特定的节点。
- Document接口
Document接口代表了整个XML/HTML文档,因此,它是整棵文档树的根,提供了对文档中的数据进行访问和操作的入口。
由于元素。文本节点、注释、处理指令等都不能脱离文档的上下文关系而独立存在,所以在Document接口提供了创建其它节点对象的方法,通过该方法创建的节点对象都有一个owenerDocument属性,用来表明当前节点是由谁所创建的以及节点同Document之间的联系。
在Dom树中,Document接口同其它接口之间的关系如下图所示:
- Node接口
Node接口在整个DOM树中具有举足轻重的地位,DOM接口中有很大一部分接口是从Node接口继承过来的,例如,Element.Attr、等接口,都是从Node继承过来的,在DOM树中,Node接口代表了树中的一个节点。一个典型的Node接口如下图所示:
SAX
SAX的全称是Simple API for XML,也即XML简单应用程序接口。与DOM不同,SAX提供的访问模式是一种顺序模式,这是一种快速读写XML数据的方式。
当使用SAX分析器对XML文档进行分析时,会触发一系列事件,并激活相应的事件处理函数,应用程序通过这些事件处理函数实现对XML文档的访问,因而SAX接口也被称作事件驱动接口。
SAX分析器在对XML文档进行分析时,触发了一系列事件,由于事件触发本身是有时序性的,因此,SAX提供的是一种顺序访问机制,对于已经分析的部分,不能再倒回去重新处理。SAX之所以被叫做“简单”应用程序接口,是因为SAX分析器只做了些简单的工作,大部分工作还要由应用程序自己去做。也就是说,SAX分析器在实现时,它只是顺序的检查XML文档中的字节流,判断当字节是XML语法中哪一部分、是否符合XML语法,然后再触发相应的事件,而事件处理函数本身则要由应用程序自己来实现,同DOM分析器相比,SAX分析器缺乏灵活性,对于那些只需要访问XML文档中的数据而不对文档进行更改的应用程序来说,SAX分析器更为合适。
使用DOM解析XML时,首先将xml文档加载到内存当中,然后可以通过随机的方式访问内存中的DOM树;SAX是基于事件而且是顺序执行的,一旦经过了某个元素,我们就没有办法再去访问它了,因此它占据内存要比DOM小,对于大型的xml文档来说,通常会使用SAX而不是DOM进行解析。














 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









