






最近在开发项目的时候, 发现应对与多张表格的查询,使用sql语句的拼接来实现多张表格的拼接查询,更加的方便与有意思. 同时基于hibernate的数据关联性的设计 也是一个非常重要的部分.在这里暂时还不是特别的熟悉,也不是很会使用.
现在开始进行SQL拼装语句的学习.
1,首先 SQL语言 有四个作用, 数据查询,数据定义,数据操纵, 数据控制.
2,每个作用分别对应一个特点.SQl有 嵌入式的 和 交互式(直接敲命令行). 下图表示的是sql语言的几个基本操作.
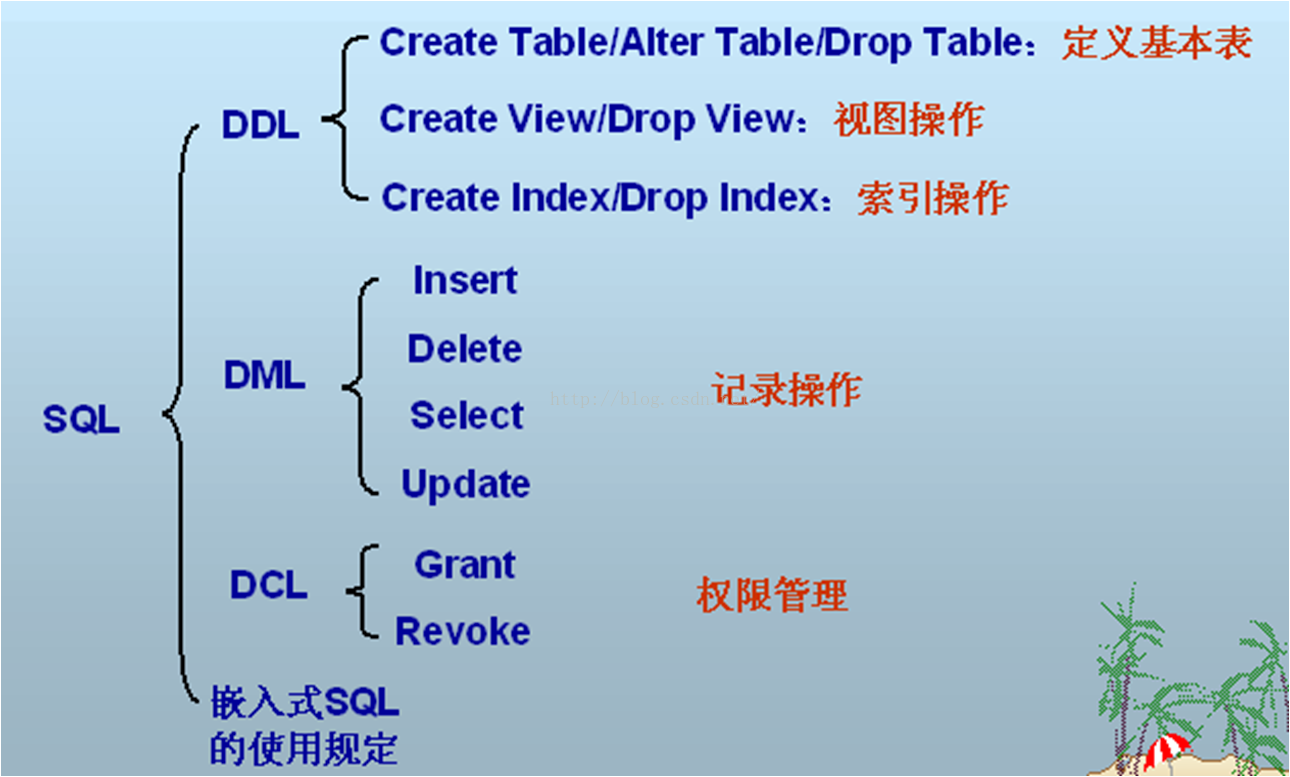
3,基本表和视图的概念
FOREIGN KEY约束
[CONSTRAINT <约束名>] FOREIGN KEY REFERENCES<主表名> (<列名>[{<列名>}])
6,
1. 按照索引记录的存放位置可分为聚集索引与非聚集索引
2. 唯一索引的概念
3. 复合索引的概念
这些都是索引的概念,索引最主要的用途就是 在进行数据库的查询时,加快查询速度. 在非索引的列上,进行查询是非常恐怖的一件事情.
CREATE CLUSTER INDEX TI ON T(TN)
但是索引对于更新较多的表 是一种负担.
索引数目无限制,但索引越多,更新数据的速度越慢。对于仅用
于查询的表可多建索引,对于数据更新频繁的表则应少建索引
7, 对于数据表的查询, select语句的使用. 查询语句的嵌套非常重要. 是实现五张表格联合查询的核心.
现在意识到了 数据库设计的必要性, 尤其是在处理各个数据的关联性的时候. 怎样设计数据库,是完全分拆成三范式,还是不分拆,有一些联合. 应对不同特点的数据表格, 更新频繁类型的, 查询频繁类型的. 不怎么更新,但是有可能更新的. 对于历史数据的 记录. 这些问题都应该是数据库设计里面应该体现出来的东西.
首先进行sql语句查询的学习.
select 语句的 嵌套查询.
SELECT〈列名〉[{,〈列名〉}]
FROM〈表名或视图名〉[{,〈表名或视图名〉}]
[WHERE〈检索条件〉]
[GROUP BY <列名1>[HAVING <条件表达式>]]
[ORDER BY <列名2>[ASC|DESC]];
另一种格式
SELECT [ALL|DISTINCT][TOPN [PERCENT][WITH TIES]]
列名1 [AS 别名1]
[, 列名2 [ AS别名2]…]
[INTO 新表名]
FROM 表名 1[[AS]表1别名]
[INNER|RIGHT|FULL|OUTER][OUTER]JOIN
表名2 [[AS]表2别名]
ON 条件
SQL语句执行的过程.
例3.23查询选修了课程的学生号。
SELECTDISTINCT SNOFROM SC
例3.24查询全体学生的姓名、学号和年龄。
SELECT SNAME NAME, SNO, AGEFROM S
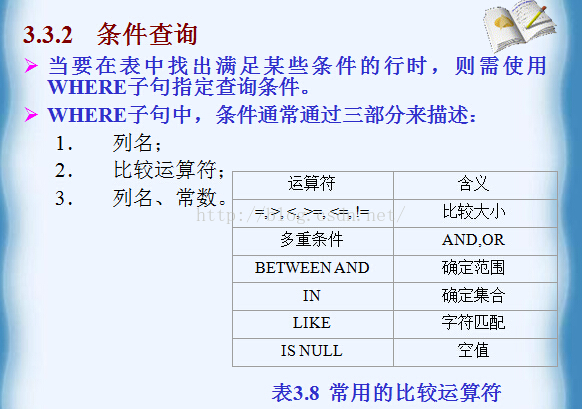
例3.34查询没有考试成绩的学生的学号和相应的课程号。
SELECT SNO, CNO
FROM SC
WHERE SCORE ISNULL

例3.35求学号为S1学生的总分和平均分。
SELECT SUM(SCORE) AS TotalScore, AVG(SCORE) ASAveScore
FROM SC
WHERE (SNO = 'S1')
例3.42查询各位教师的教师号及其任课的门数。
SELECT TNO,COUNT(*) ASC_NUM
FROM TC
GROUP BY TNO
3.3.5查询的排序
ORDER BY SNO,SCORE DESC 有两个列并行的时候,就依次按照 列来进行并行.
1.(FROM)取出整个SC
2.(WHERE)筛选SCORE>=60的元组
3.(GROUP BY)将选出的元组按SNO分组
4.(HAVING)筛选选课三门以上的分组
5.(SELECT)以剩下的组中提取学号和总成绩
6.(ORDER BY)将选取结果排序
这个执行的过程,非常的清晰明白. 基本可以按照这个来理解 sql语句的执行状态. 后面的涉及多表查询的部分,应该也是按照这个方法来执行的.
下面开始进行多表的查询.
10 多表查询
数据表连接及连接查询
具体分为以下几种:
等值连接与非等值连接
SELECT T.TNO ,TN,CNO
FROM T,TC
WHERE(T.TNO = TC. TNO) AND (TN=‘刘伟’)
[<表名1>.] <列名1> <比较运算符>[<表名2>.] <列名2>
SELECT R2.TNO,R2.TN,R1.CNO
FROM (注意:只有在 from中 的as 可以在 sql语句中使用, 其余地方写的只是表现在结果中)
(SELECT TNO,CNO FROM TC) AS R1
INNER JOIN
(SELECT TNO ,TN FROM T
WHERE TN='刘伟') AS R2
ON R1.TNO=R2.TNO
from Table A
inner join Table B on A.B的主键 = B.主键
inner join Table C on B.C的主键 = C.主键
group C.字段一
自身连接
例3.49查询所有比刘伟工资高的教师姓名、性别、工资和刘伟的工资。
SELECT X.TN,X.SAL AS SAL_a,Y.SAL ASSAL_b
FROM T AS X ,T AS Y
检索所有学生姓名,年龄和选课名称。
SELECT SN,AGE,CN
FROM S,C,SC
WHERE S.SNO=SC.SNO ANDSC.CNO=C.CNO
SELECTR3.SNO,R3.SN,R3.AGE,R4.CN
FROM
(SELECT SNO,SN,AGE FROM S) AS R3
INNER JOIN
(SELECT R2.SNO,R1.CN
FROM
(SELECT CNO,CN FROM C)AS R1
INNER JOIN
(SELECT SNO,CNO FROM SC)AS R2
ON R1.CNO=R2.CNO) AS R4
ON R3.SNO=R4.SNO
外连接
外连接
例3.51查询所有学生的学号、姓名、选课名称及成绩。(没有选课的同学的选课信息显示为空)则应写成如下的SQL语句。
SELECT S.SNO,SN,CN,SCORE
FROM S
LEFT OUTER JOIN SC
ON S.SNO=SC.SNO
LEFT OUTER JOIN C
ON C.CNO=SC.CNO
则查询结果只包括所有的学生,没有选课的吴丽同学的选课信息显示为空。
13 嵌套查询
返回一个值的子查询
例3.52查询与刘伟教师职称相同的教师号、姓名。
SELECT TNO,TN
FROM T
WHERE PROF=(SELECT PROF
FROM T
WHERE TN='刘伟')
返回一组值的子查询
1. 使用ANY
例3.53查询讲授课程号为C5的教师姓名。
SELECT TN
FROM T
WHERE TNO=ANY
(SELECT TNO
FROM TC
WHERE CNO='C5')
使用IN
SELECT TN
FROM T
WHERE TNO IN
(SELECT TNO
FROM TC
WHERE CNO='C5')
使用ALL
例3.56查询其他系中比计算机系所有教师工资都高的教师的姓名和工资。
SELECT TN,SAL
FROM T
WHERE SAL>ALL
(SELECT SAL
FROM T
WHERE DEPT='计算机')
AND DEPT!= ‘计算机’
SELECT TN,SAL
FROM T
WHERE SAL>
(SELECT MAX(SAL )
FROM T
WHERE DEPT='计算机')
AND DEPT!= ‘计算机’
查询不讲授课程号为C5的教师姓名。
SELECT DISTINCT TN
FROM T
WHERE 'C5' !=ALL
(SELECT CNO
FROM TC
WHERE TNO=T.TNO)
1. 利于数据保密,对不同的用户定义不同的视图,使用户只能看到与自己有关的数据。
例如,对教师表创建了计算机系视图,本系教师只能使用此视图,而无法访问其他系教师的数据。
2. 简化查询操作,为复杂的查询建立一个视图,用户不必键入复杂的查询语句,只需针对此视图做简单的查询即可。如例3.75。
3. 保证数据的逻辑独立性。对于视图的操作,比如查询,只依赖于视图的定义。当构成视图的基本表要修改时,只需修改视图定义中的子查询部分。而基于视图的查询不用改变。这就是第一章介绍过的外模式与模式之间的独立性,即数据的逻辑独立性
15 数据控制
基本上就是 数据库层面的 权限控制. 现在做系统的时候,使用的情况不是很多. 一般都是在代码中进行权限的控制, 比如比较出名的Rbac 组件.














 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









