







好久没有更新博客了,这段时间一直在忙图像处理的项目,最近空了下来,也是时候整合C++的相关内容,静心感受下编程语言的魅力,和大家共同探讨学习。我将以头文件的形式展开学习,且只讲述相关接口的应用,至于内部具体的实现,鉴于本人水平有限,不敢献丑。经过考虑,决定先从和数据结构相关的头文件开始,因为这些头文件里的内容在OJ里经常要用到。今天要学习的是string头文件,这里的string是C++里的string,而C里的string在C++里仍然保留,头文件名为cstring,这里不做展开。在此说明:以下的代码都是在VS 2015编译环境下运行。
Some Details
basic_string
实际上,string头文件里并不只有string这个类型,这个头文件里最主要的是一个叫basic_string的类模板,这个类模板的声明如下:
template < class charT,
class traits = char_traits<charT>,
class Alloc = allocator<charT>
> class basic_string;上面的类模板构造有点复杂,我们没有必要深究,只需要知道我们可以在basic_string这个类中自定义三种类型作为member type就行了。其中的charT (character type)是最重要的模板参数,它直接说明了字符串中的元素类型,另外两个类型均采用默认参数(以charT为参数构建的类)即可。
为什么要提basic_string这玩意儿呢,因为string类型正是basic_string的special type,在实际操作中,最常使用的是char类型(字符型),故只需将上面的charT转换为char便是string类型了。string类型的构造如下:
typedef basic_string<char> string; //元素为8bits字符类型类似的,在c++内置类型中,还有wstring、u16string和u32string(后两个是在c++11标准下),我们可以根据实际需要选取字符串类型,它们的构造如下:
typedef basic_string<wchar_t> wstring; //16位或32位
typedef basic_string<char16_t> u16string; //16位
typedef basic_string<char32_t> u32string; //32位String versus Character Array
之前看到过一篇文章,讲到了string和char*,我在此做个总结。
- string内存由系统进行管理,自动实现内存的申请和释放;而char* 则需要自己管理。如果你要使用的内存较大,则string系统自动申请的内存可能不够使用。因此,在使用内存大小知道的情况下,建议使用char* ,而当使用内存具体大小未知,但内存不大时可以使用string。
string相比char* 有一个优点,c++标准库对string类进行了封装,里面的各种成员函数处理字符串相当方便,这也是我常用string的一个原因。
至于string和char类型的vector有什么区别,我倒还没有深究过,大概是成员函数不同吧,知道的小伙伴可以在下面留言下。
Elaboration
Member Functions
string::string
string(); //(1)默认构造函数,构造一个空字符串,字符串长度为0
string(const string& str); //(2)拷贝构造函数
string(const string& str, size_t pos, size_t len = npos);
//(3)复制str一部分,pos是起始位置,len是复制的字符串长度(默认值是到字符串底部)这里要注意str的第一个字符pos=0
string(const char* s); //(4)复制C模式下s指针指向的字符数组(字符串)
string(const char* s, size_t n); //(5)复制前n个字符数组元素
string(size_t n,char c); //(6)复制n个连续的字符c
template <class InputIterator>
string(InputIterator first, InputIterator last);
//(7)利用iterator复制字符序列,范围为[first,last),注意最后一个不包括
string(initializer_list<char> il); //(8)将初始化列表il转换为string
string(string&& str) noexcept; //(9)右值引用str,并且不抛出异常信息。关于右值引用和move语义这块内容,是C++11的新特性,我当时琢磨了很久也还是云里雾里,估计是自己悟性不够高,我觉得有两篇文章写得还不错,贴在这里。另外,不知右值和临时变量有何不同,知道的小伙伴也可以在下面留言。
https://www.ibm.com/developerworks/cn/aix/library/1307_lisl_c11/
https://my.oschina.net/letiantian/blog/470921
Demonstration: //为简略,今后代码将省略cout,自己操作时应加上
#include<iostream>
#include<string> //调用string头文件
#include<initializer_list> //(8)中要用到
using namespace std;
string test(const string& x) //(9)的测试函数,产生右值
{
return x;
}
int main()
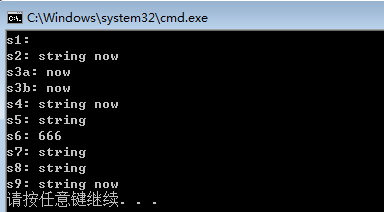
{
string s4("string now"); //(4)
string s1; //(1)
string s2(s4); //(2)
string s3a(s4, 7, 3); //(3)设置长度
string s3b(s4, 7); //(3)默认长度,也就是到底部
string s5("string now", 6); //(5)
string s6(3, '6'); //(6)
string s7(s4.begin(), s4.begin() + 6);
//(7)begin函数后面会提到,可以生成iterator
initializer_list<char> s0 = {'s', 't', 'r', 'i', 'n', 'g'};
//生成initializer_list
string s8(s0); //(8)
string s9(test(s4)); //(9)
}
//自行将注释中的序号与上面的序号对照进行学习结果如下,看看是不是和你们想象中的一样呢。
string::operator=
string& operator= (const string& str); //(1)赋值string类型变量
string& operator= (const char* s); //(2)赋值c风格字符串
string& operator= (char c); //(3)赋值一个字符,字符串长度为1
string& operator= (initializer_list<char> il); //(4)赋值初始化列表il
string& operator= (string&& str) noexcept; //(5)利用右值引用赋值Demonstration:
#include<iostream>
#include<string> //调用string头文件
#include<initializer_list> //(4)中要用到
using namespace std;
string test(const string& x) //(5)的测试函数,产生右值
{
return x;
}
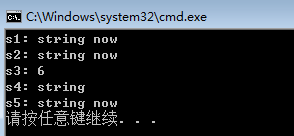
int main()
{
string s1, s2, s3, s4, s5;
//为把operator=和构造函数分开,使用默认构造函数
s2 = "string now"; //(2)
s1 = s2; //(1)
s3 = '6'; //(3)
initializer_list<char> s0 = {'s', 't', 'r', 'i', 'n', 'g'};
s4 = s0; //(4)
s5 = test(s2); //(5)
}
Some More Details
string类型对象是以’\0’结尾的嘛?
估计很多人跟我一样都想过这个问题,因为在C语言中,系统默认字符串都是以’\0’截尾的。我们不妨今天来编个小程序验证一下。
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s0 = "string now"; //初始化s0
if (s0[10] == '\0')
cout << "Yes." << endl; //如果末尾是'\0',则输出Yes.
else cout << "No." << endl; //如果末尾不是'\0',则输出No.
return 0;
}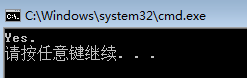
在这里,我们得到了一个令人满意的答案,说明C++风格的string仍然是以’\0’结尾的,通常情况下,末尾的’\0’我们可以忽略不计。
编码类型对string的影响
提到这个问题,是因为我注意到了这么一句话,我在这里引用一下。
Note that this class handles bytes independently of the encoding used: If used to handle sequences of multi-byte or variable-length characters (such as UTF-8), all members of this class (such as length or size), as well as its iterators, will still operate in terms of bytes (not actual encoded characters).
这句话的意思概括起来就是说,不管你使用哪种类型的编码,string类型的操作都将按一个字节的方式来处理。我们不禁想到了中文,因为中文是在GB2312中编码的,而且一个中文字符占用两个字节,这样会引起什么问题呢?我们也来测试一下。
#include<iostream>
#include<string>
using namespace std;
int main()
{
string s0 = "测试"; //用中文初始化s0
cout << s0 << endl << endl; //查看能否输出中文
for (int i = 0; i < 2; ++i) //输出前2个字节,看看是否会输出测试两个字
cout << s0[i] << endl;
return 0;
}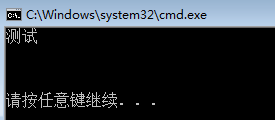
刚开始,我们将整个字符串输出,看看是否会显示“测试”这两个字,结果是这两个字显示了,说明c++是可以识别GB2312编码的。而当我们尝试将字符串按单个字节输出的时候,就发现了问题,因为输出台输出的是空白,这就说明string类型并不能直接辨别这个是什么编码,它只能按单个字节进行读取,这就会导致该字节没有默认的ASCII编码可以对应,因此也就不会有内容输出了。
string的内容实在有点多,为了保持页面的精简,方便浏览,我将把下半部分内容放到下篇博文中。如有错误,欢迎指正!















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









