







 这篇博客详细介绍了如何将给定的正规式转化为等价的非确定有限自动机(NFA)。通过定义`state`和`unit`结构体,博主阐述了算法的核心思路,包括处理括号、或运算、星号运算以及普通字符的情况。同时,提供了源程序及测试结果,展示了一个具体的正规式转换实例。
这篇博客详细介绍了如何将给定的正规式转化为等价的非确定有限自动机(NFA)。通过定义`state`和`unit`结构体,博主阐述了算法的核心思路,包括处理括号、或运算、星号运算以及普通字符的情况。同时,提供了源程序及测试结果,展示了一个具体的正规式转换实例。
词法分析程序题
题目
给定正规式,转化为等价的NFA
算法
结构体介绍
state结构体
struct state//定义状态结构体
{
string input;//输入符号集合
vector<state*> *next;//输出状态集合,与输入符号集合一一对应
};
input[i]和(*next)[i]一一对应,若next.size()为0则表示到了终点
unit结构体
struct unit//正规文法单元,记录当前单元的开始状态地址和结束状态地址,最后不断壮大的单元即为所需的NFA
{
char id;//0表示最小单元,()|*表示辅助字母,1表示曾通过()将状态绑定在一起以便更好区分(ab)*和ab*的处理
state *begin;//开始状态地址
state *end;//结束状态地址
};
该结构体采用正规文法的思想,使用正规文法到正规式转化的逆思想,将正规式不断单元化,最后再合并。
算法介绍
遍历正规式,对正规式每一个输入进行相应处理。
输入’(‘:构造unit单元,id设为’(‘,起始状态和终止状态都为NULL,压入unit栈
输入’|’: 构造unit单元,id设为’|‘,起始状态和终止状态都为NULL,压入unit栈
输入’)’:判断’()’内是否含有’|’,若有,则分’|’右边和左边,右边按出栈顺序依次联结成一个unit单元,左边也按出栈顺序依次联结成一个unit单元,然后构造空串,如下图
图1
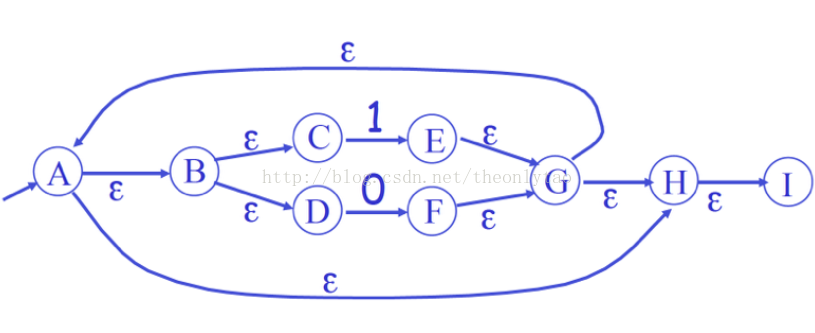
若无’|’,则直接按出栈顺序依次联结’()’内单元
输入’*’:判断栈顶单元标识,若id==’1’,表示该单元内内容通过’()’进行过绑定,直接通过添加空串状态指向begin状态和begin状态指向空串,再次联结成一个新单元
若id==’0’,表示该单元内内容未通过’()’进行过绑定,直接通过添加空串状态指向end状态和end状态指向空串
输入其他字符:默认为输入字符,判断该字符是否为首字符或右边为’(‘或’|’,若是则创建新状态并构建新单元压入栈,否则创建新状态联结进栈顶单元
输入完毕:联结栈内所有单元,输出该单元
源程序
#include
#include
#include"d_stack.h"//栈类头文件
#include
using namespace std;
struct state//定义状态结构体
{
string input;//输入符号集合
vector
*next;//输出状态集合,与输入符号集合一一对应
};
struct unit//正规文法单元,记录当前单元的开始状态地址和结束状态地址,最后不断壮大的单元即为所需的NFA
{
char id;//0表示最小单元,()|*表示辅助字母,1表示曾通过()将状态绑定在一起以便更好区分(ab)*和ab*的处理
state* begin;//开始状态地址
state* end;//结束状态地址
};
class NFA
{
public:
unit* REtoNFA(string RE)//regular expression to NFA
{
miniStack
*s=new miniStack
(); for(int i=0;i
id='(';//标识为'(',压入栈 u1->begin=NULL; u1->end=NULL; s->push(u1); break; } case')': { unit* u1; unit* u2; unit* u3; u1=NULL; u3=NULL; bool exist=false; while(s->top()->id!='(')//联结'|"右边的单元 { if(s->top()->id=='0'&&u1==NULL||s->top()->id=='1'&&u1==NULL)//当u1未初始化时 { u1=s->top(); s->pop(); } else if(s->top()->id!='|')//未遇到'|'前联结所有单元 { unit* tempu1=s->top(); tempu1->end->n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3163
3163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









