







文章目录
构造词法分析器(从正规式到词法分析器)的一般方法和步骤:
→
正
规
式
→
N
F
A
→
确
定
化
D
F
A
→
最
小
化
D
F
A
→
分
析
器
\xrightarrow{}{正规式}\xrightarrow{}{NFA}\xrightarrow{确定化}{DFA}\xrightarrow{最小化}{DFA}\xrightarrow{}{分析器}
正规式NFA确定化DFA最小化DFA分析器
- 设计正规式:
用正规式描述模式; - 构造一个NFA:
为每个正规式构造一个NFA,它识别正规式所表示的正规集; - 确定化:
将构造的NFA转换成等价的DFA - 最小化:
优化DFA,使其状态数最少 - 从优化后的DFA构造词法分析器。
一、构造NFA(算法2.2 Thompson 算法)
- 输入:字母表
∑上的正规式r - 输出:接受
L(r)的NFAN - 方法:将正规式分解成小部分,再组合

例2.11 用Thompson算法构造正规式
r=(a|b)*abb的NFA N(r)


注意:或运算一般是2、3再4、5,连完再换行
二、确定化(从NFA到DFA)
1.两个表达式
(1)smove(S, a)
定义:
- 从状态集S出发,标记为a的下一状态全体(即状态集)。
- 与move(s, a)的唯一区别:用状态集取代状态。
例子:
状态集A={0,1,2,4,7},A中可以经过字符a的是状态2和7,分别可以到达状态3和8,则smove(A,a)={3,8}。
(2)算法2.4 ε-闭包(T)
定义:从状态集T出发,不经任何字符达到的状态全体(即状态集)。
满足条件:
(1) T中所有状态属于ε-闭包(T);
(2) 任何smove(ε-闭包(T),ε)属于ε-闭包(T);
(3) 再无其他状态属于ε-闭包(T)。
计算方法:
(1)加入状态集T中所有状态
(2)将smove(目前的ε-闭包(T),ε)中得到的新的状态加入ε-闭包(T)
(3)不断重复(2)直到再无其他状态属于ε-闭包(T)
function ε-闭包(T) is
begin
for T中每个状态t
loop 加入t到U; push(t);
end loop;
while 栈不空
loop pop(t);
for 每个u=move(t, ε)
loop if u不在U中 then 加入u到U; push(u); end if;
end loop;
end loop;
return U;
endε-闭包;
例子:求ε-闭包({s2})
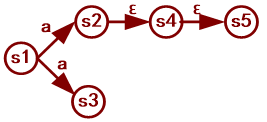
加入{s2}:ε-闭包({s2})={s2}
smove({s2},ε)={s4},则ε-闭包({s2})={s2,s4}
smove({s2,s4},ε)={s4,s5},则ε-闭包({s2})={s2,s4,s5}
2.算法2.3 (并行)模拟NFA
引子
并行的意思是采用状态集和smove()
算法
- 输入:
NFA N={S,∑,move,s0,F},x(eof), s0, F - 输出:若N接受x,回答“yes”,否则“no”
- 方法:用下边的过程对x进行识别。S是一个状态的集合
伪代码:就是不断的按下一个字符走到头,看看最终的结果和F是否有交集(可能有别的非F状态)。
S := ε-闭包({s0}); -- 所有可能初态的集合
ch := nextchar;
while ch ≠ eof loop
S:=ε-闭包(smove(S,ch)); -- 所有下一状态的集合
ch := nextchar;
end loop;
if S∩F≠Φ then return “yes”; else return “no”;
end if; ■
例2.13:在NFA上识别输入序列abb和abab
识别abb:
计算初态集:
ε
−
闭
包
(
0
)
=
0
,
1
,
2
,
4
,
7
ε-闭包({0}) ={0,1,2,4,7}
ε−闭包(0)=0,1,2,4,7, A
A出发经a到达:
ε
−
闭
包
(
s
m
o
v
e
(
A
,
a
)
)
=
3
,
8
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(A,a))={\textcolor{gold}{3,8},1,2,4,6,7}
ε−闭包(smove(A,a))=3,8,1,2,4,6,7, B
B出发经b到达:
ε
−
闭
包
(
s
m
o
v
e
(
B
,
b
)
)
=
5
,
9
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(B,b))={\textcolor{gold}{5,9},1,2,4,6,7}
ε−闭包(smove(B,b))=5,9,1,2,4,6,7, C
C出发经b到达:
ε
−
闭
包
(
s
m
o
v
e
(
C
,
b
)
)
=
5
,
10
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(C,b))={\textcolor{gold}{5,10},1,2,4,6,7}
ε−闭包(smove(C,b))=5,10,1,2,4,6,7,D
识别的路径为:A a B b C b D
结束且D∩{10}={10},接受。
识别abab:
初态集:ε-闭包(s0)={0,1,2,4,7} A
A出发经a到达:
ε
−
闭
包
(
s
m
o
v
e
(
A
,
a
)
)
=
3
,
8
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(A,a))={\textcolor{gold}{3,8},1,2,4,6,7}
ε−闭包(smove(A,a))=3,8,1,2,4,6,7, B
B出发经b到达:
ε
−
闭
包
(
s
m
o
v
e
(
B
,
b
)
)
=
5
,
9
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(B,b))={\textcolor{gold}{5,9},1,2,4,6,7}
ε−闭包(smove(B,b))=5,9,1,2,4,6,7, C
C出发经a到达:
ε
−
闭
包
(
s
m
o
v
e
(
C
,
a
)
)
=
3
,
8
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(C,a))={\textcolor{gold}{3,8},1,2,4,6,7}
ε−闭包(smove(C,a))=3,8,1,2,4,6,7, B
B出发经b到达:
ε
−
闭
包
(
s
m
o
v
e
(
B
,
b
)
)
=
5
,
9
,
6
,
7
,
1
,
2
,
4
ε-闭包(smove(B,b))={\textcolor{gold}{5,9},6,7,1,2,4}
ε−闭包(smove(B,b))=5,9,6,7,1,2,4, C
识别路径为:A a B b C a B b C
因为C∩{10}=Φ,所以不接受
3.算法2.5 “子集法”构造DFA
- 输入:NFA N
- 输出:等价的DFA D。初态含有NFA初态,终态集是含有NFA终态的状态集合
- 方法:
将ε-闭包({s0})得到的状态集,让其smove()每个字符,得到的不同的状态集再让其smove()每个字符,重复直到所有的状态集都smove()每个字符。
两个数据结构:Dstates(状态),Dtran(状态转移)
初始化:ε-闭包({s0})是Dstates仅有的状态,且尚未标记;
while Dstates有尚未标记的状态T
loop 标记T;
for 每一个字符a -- T中向外转移边的标记
loop
U := ε-闭包(smove(T,a));
if U非空
then Dtran[T,a] := U;
if U不在Dstates中
then U作为尚未标记的状态加入Dstates;
end if;
end if;
end loop;
end loop; ■
例2.15 用算法2.5构造(a|b)*abb的DFA
(A*表示新的状态集第一次创建,A表示这是已出现的状态集A)
ε
−
闭
包
(
0
)
=
0
,
1
,
2
,
4
,
7
ε-闭包({0})={0,1,2,4,7}
ε−闭包(0)=0,1,2,4,7 A*
ε
−
闭
包
(
s
m
o
v
e
(
A
,
a
)
)
=
3
,
8
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(A, a))={\textcolor{gold}{3,8},1,2,4,6,7}
ε−闭包(smove(A,a))=3,8,1,2,4,6,7 B*
ε
−
闭
包
(
s
m
o
v
e
(
A
,
b
)
)
=
5
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(A, b))={\textcolor{gold}{5},1,2,4,6,7}
ε−闭包(smove(A,b))=5,1,2,4,6,7 C*
ε
−
闭
包
(
s
m
o
v
e
(
B
,
a
)
)
=
3
,
8
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(B, a))={\textcolor{gold}{3,8},1,2,4,6,7}
ε−闭包(smove(B,a))=3,8,1,2,4,6,7 B
ε
−
闭
包
(
s
m
o
v
e
(
B
,
b
)
)
=
5
,
9
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(B, b))={\textcolor{gold}{5,9},1,2,4,6,7}
ε−闭包(smove(B,b))=5,9,1,2,4,6,7 D*
ε
−
闭
包
(
s
m
o
v
e
(
C
,
a
)
)
=
3
,
8
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(C, a))={\textcolor{gold}{3,8},1,2,4,6,7}
ε−闭包(smove(C,a))=3,8,1,2,4,6,7 B
ε
−
闭
包
(
s
m
o
v
e
(
C
,
b
)
)
=
5
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(C, b))={\textcolor{gold}{5},1,2,4,6,7}
ε−闭包(smove(C,b))=5,1,2,4,6,7 C
ε
−
闭
包
(
s
m
o
v
e
(
D
,
a
)
)
=
3
,
8
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(D, a))={\textcolor{gold}{3,8},1,2,4,6,7}
ε−闭包(smove(D,a))=3,8,1,2,4,6,7 B
ε
−
闭
包
(
s
m
o
v
e
(
D
,
b
)
)
=
5
,
10
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(D, b))={\textcolor{gold}{5,10},1,2,4,6,7}
ε−闭包(smove(D,b))=5,10,1,2,4,6,7 E*
ε
−
闭
包
(
s
m
o
v
e
(
E
,
a
)
)
=
3
,
8
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(E, a))={\textcolor{gold}{3,8},1,2,4,6,7}
ε−闭包(smove(E,a))=3,8,1,2,4,6,7 B
ε
−
闭
包
(
s
m
o
v
e
(
E
,
b
)
)
=
5
,
1
,
2
,
4
,
6
,
7
ε-闭包(smove(E, b))={\textcolor{gold}{5},1,2,4,6,7}
ε−闭包(smove(E,b))=5,1,2,4,6,7 C
识别abb和abab:
A a B b D b E,接受
A a B b D a B b D,不接受
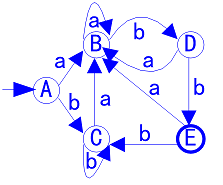
4.算法2.3和算法2.5关系
- 共同点:确定化,即ε-闭包(smove(S, a))
- 区别:一条路径的确定化与全部路径的确定化
三、最小化DFA
1.可区分与不可区分
概念
定义2.7
对于任何两个状态t和s,若从一状态出发接受输入字符串ω,而从另一状态出发不接受ω,或者从t出发和从s出发到达不同的接受状态,则称ω对状态t和s是可区分的。
设想任何输入序列ω对s和t均是不可区分的,则说明从s出发和从t出发,分析任何输入序列ω均得到相同结果。
划分Π:Π1={ABCD,E},其内元素是组G
组G:ABCD是一个组,E是一个组
组的分裂
- 不分裂:不可区分的组内状态,还写在一起
- 分裂:可区分的组内状态,分开
意思
-
可区分:证明是不同的道路,不可合并
-
不可区分:是重复的道路,因此,s和t可以合并成一个状态。
最小化DFA就是将不可区分的状态合并。
例子:
m(A,a)=B, m(A,b)=C
m(B,a)=B, m(B,b)=D
m(C,a)=B, m(C,b)=C
其中A和C就是不可区分的(得到的下一状态都一样),A和B、B和C就是可区分的(得到的下一状态有不一样)。
组{ABC}→{AC,B}
2.算法2.6 最小化DFA的状态数
- 输入:
DFA D={S,∑,move,s0,F} - 输出:等价的
D'={S',∑,move',s0',F'}(D’状态数最少) - 方法:
1.初始划分:Π={非终态,终态}
2.利用可区分的概念,反复分裂划分中的组Gi,直到不可再分裂;
3.由最终划分构造D’,关键是选代表和修改状态转移;
4.消除可能的死状态和不可达状态。
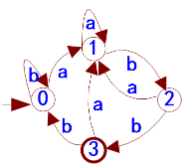
例2.17 用算法2.6化简DFA
m(A,a)=B, m(A,b)=C
m(B,a)=B, m(B,b)=D
m(C,a)=B, m(C,b)=C
m(D,a)=B, m(D,b)=E
m(E,a)=B, m(E,b)=C
初始化划分Π1={ABCD,E}
非终态部分中只有状态A和C是不可区分的,则{ABCD}→{AC,B,D}
终态部分中只用状态E,
所以Πfinal={AC,B,D,E}
根据Πfinal构造D’:
① 选代表,用A代表AC组(把C用A代替)
② 修改状态转移:
m(A,a)=B, m(A,b)=A
m(B,a)=B, m(B,b)=D
m(D,a)=B, m(D,b)=E
m(E,a)=B, m(E,b)=A
用0、1、2、3
代替A、B、D、E
四、由DFA构造词法分析器
1.表驱动型的词法分析器
在表驱动的词法分析器中,DFA是被动的,需要一个驱动器来模拟DFA的行为,以实现对输入序列的分析。

2.直接编码的词法分析器
直接编码的词法分析器,将DFA和DFA识别输入序列的过程合并在一起,直接用程序代码模拟DFA识别输入序列的过程。
状态和状态转移与语句的对应关系
① 初态→程序的开始;
② 终态→程序的结束(不同终态return不同记号);
③ 状态转移→分情况或者条件语句(case/if);
④ 环→循环语句(loop);
⑤ return满足最长匹配原则。
例:识别(a|b)*abb的程序框架
void main(){ char buf[]="abba#", *ptr=buf;
while (*ptr!='#' ){
l0: while (*ptr=='b') ptr++; // state 0
switch(*ptr)
{
case 'a': ptr++;
l1: while (*ptr=='a') ptr++; // state 1
switch (*ptr)
{
case 'b': ptr++;
switch (*ptr) // state 2
{
case 'a': ptr++; goto l1;
case 'b': ptr++;
switch (*ptr) // state3
{
case 'a': ptr++; goto l1;
case 'b': ptr++; goto l0;
case '#': cout<<"yes"; return;
default: goto le; }
default: goto le;
}
default: goto le;
}
default: goto le;
}
}
le: cout << "no" << endl;
} // 看实例运行
3.两类分析器的比较
















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









