







redis通过tcp来对外提供服务,client通过socket连接发起请求,每个请求在命令发出后会阻塞等待redis服务器进行处理,处理完毕后将结果返回给client。
其实和一个http的服务器类似,一问一答,请求一次给一次响应。而这个过程在排除掉redis服务本身做复杂操作时的耗时的话,可以看到最耗时的就是这个网络传输过程。每一个命令都对应了发送、接收两个网络传输,假如一个流程需要0.1秒,那么一秒最多只能处理10个请求,将严重制约redis的性能。
在很多场景下,我们要完成一个业务,可能会对redis做连续的多个操作,譬如库存减一、订单加一、余额扣减等等,这有很多个步骤是需要依次连续执行的。这样的场景,网络传输的耗时将是限制redis处理量的主要瓶颈。那么此时就可以引入pipeline了,pipeline管道就是解决执行大量命令时、会产生大量同学次数而导致延迟的技术。
其实原理很简单,pipeline就是把所有的命令一次发过去,避免频繁的发送、接收带来的网络开销,redis在打包接收到一堆命令后,依次执行,然后把结果再打包返回给客户端。
拿例子来演示一下:
Long time = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
stringRedisTemplate.opsForValue().increment("pipline", 1);
}
System.out.println("耗时:" + (System.currentTimeMillis() - time));
time = System.currentTimeMillis();
stringRedisTemplate.executePipelined(new SessionCallback<Object>() {
@Override
public <K, V> Object execute(RedisOperations<K, V> redisOperations) throws DataAccessException {
for (int i = 0; i < 10000; i++) {
stringRedisTemplate.opsForValue().increment("pipline", 1L);
}
return null;
}
});
System.out.println("耗时:" + (System.currentTimeMillis() - time));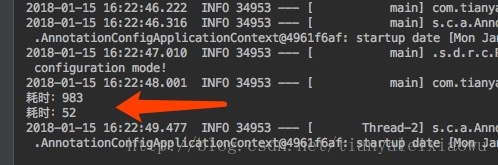
通过多次测试,在本机上耗时差距在10倍以上。
需要注意RedisTemplate执行executePipelined方法是有返回值的,List<Object>,这个list里面就是你在execute方法中执行的所有命令的返回值集合。在execute方法中要return null,否则会抛异常。
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











