







转载请注明出处:http://blog.csdn.net/ns_code/article/details/20306991
快速排序
如名所示,快速排序是已知的平均时间复杂度均为O(n*logn)的几种排序算法中效率最高的一个,该算法之所以特别快,主要是由于非常精炼和高度优化的内部循环,它在最坏情况下的时间复杂度为O(n*n),但只要稍加努力(正确选择枢轴元素)就可以避免这种情形。
本部分的重点在于对分治思想的理解和代码的书写,不打算过多地讨论枢轴元素的选择,因为这本身就不是一个简单的问题,笔者对此也没有什么研究,更不敢造次。先来看实现思想。
实现思想
快速排序的基本思想如下:
1、从待排序列中任选一个元素作为枢轴;
2、将序列中比枢轴大的元素全部放在枢轴的右边,比枢轴小的元素全部放在其左边;
3、以枢轴为分界线,对其两边的两个子序列重复执行步骤1和2中的操作,直到最后每个子序列中只有一个元素。
一趟快速排序(以排序后从小到大为例)的具体做法如下:
附设两个元素指针low和high,初值分别为该序列的第一个元素的序号和最后一个元素的序号,设枢轴元素的值为val,则首先从high所指位置起向前搜索到第一个值小于val的元素,并将其和val互换位置,而后从low所指位置起向后搜索到第一个值大于val的元素,并将其和val交换位置,如此反复 ,直到low=high为止。
我们上面说交换位置,只是为了便于理解,我们在前面几篇内部排序的博文中一直在强调,应尽量避免比较多的元素交换操作,因此下面的分析和代码的实现中,我们并不是采取交换操作,而是先将枢轴元素保存在val变量中,然后每次遇到需要交换的元素时,先将该元素赋给val所在的位置,而后再将该元素所在位置“挖空”,之后的每一次比较,就用需要交换的元素来填充上次“挖空”的位置,同时将交换过来的元素所在的位置再“挖空”,以等待下次填充。
同样为了便于理解,我们以下面的序列为例来展示快速排序的思想。
下图为无序序列的初始状态,我们选取val为第一个元素4,low和high分别指向4和5:
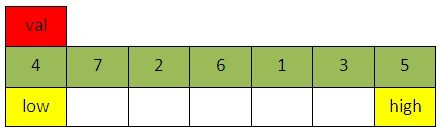
进行1次比较之后(即从high开始遇到比val小的元素):
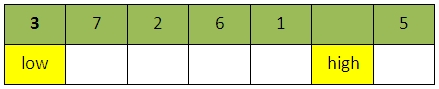
进行2次比较之后(即从low开始遇到比val大的元素):
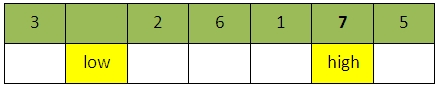
进行3次比较之后(再次从high开始向左搜索):
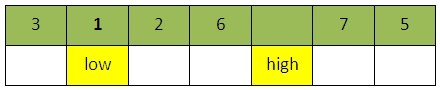
进行4次比较之后(再次从low开始向右搜索):
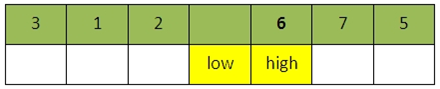
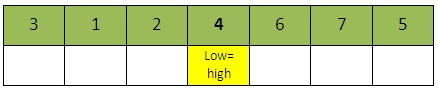
进行5次比较之后(再次从high开始向左搜索),此时向左high向左移动一个位置后,出现low=high,第一趟排序结束,我们将val插入到此时被挖空的位置,也即low或high所指向的位置。因此第一趟排序后的结果如下:
而后,我们分别对3、1、2和6、7、5进行同样操作,最终便可以得到如下有序序列:

其中,加粗的元素为每趟比较时选取的枢轴元素,我们这里每次均选择子序列的第一个元素为枢轴。在这里,4为第一趟排序时选择的枢轴,3和6为第二趟排序时左右子序列分别选择的枢轴,第二趟排序后,数组的后半部分已经有序,前半部分虽然也有序了,但是根据定义,我们需要再选1作为枢轴,来对子序列{1,2}进行第三趟排序,这样最终便得到了该有序序列。
实现代码
很明显,实现快速排序要用到递归,我们根据以上思想,实现的代码如下(包含完整测试代码):
- /*******************************
- 快速排序
- Author:兰亭风雨 Date:2014-02-28
- Email:zyb_maodun@163.com
- ********************************/
- #include<stdio.h>
- #include<stdlib.h>
- void Quick_Sort(int *,int,int);
- int findPoss(int *,int,int);
- int main()
- {
- int num;
- printf("请输入排序的元素的个数:");
- scanf("%d",&num);
- int i;
- int *arr = (int *)malloc(num*sizeof(int));
- printf("请依次输入这%d个元素(必须为整数):",num);
- for(i=0;i<num;i++)
- scanf("%d",arr+i);
- printf("快速排序后的顺序:");
- Quick_Sort(arr,0,num-1);
- for(i=0;i<num;i++)
- printf("%d ",arr[i]);
- printf("\n");
- free(arr);
- arr = 0;
- return 0;
- }
- /*
- 快速排序函数,通过递归实现
- */
- void Quick_Sort(int *a,int low,int high)
- {
- int pos;
- if(low < high)
- {
- pos = findPoss(a,low,high);
- Quick_Sort(a,low,pos-1); //左边子序列排序
- Quick_Sort(a,pos+1,high); //右边子序列排序
- }
- }
- /*
- 该函数返回分割点数值所在的位置,a为待排序数组的首地址,
- low刚开始表示排序范围内的第一个元素的位置,逐渐向右移动,
- high刚开始表示排序范围内的最后一个位置,逐渐向左移动
- */
- int findPoss(int *a,int low,int high)
- {
- int val = a[low];
- while(low < high)
- {
- while(low<high && a[high]>=val)
- high--;
- a[low] = a[high];
- while(low<high && a[low]<=val)
- low++;
- a[high] = a[low];
- }
- //最终low=high
- a[low] = val;
- return low;
- }
算法导论版快速排序
算法导论上的快速排序有点不同,主要是对findposs(Partition)函数的思路不同,它是以最后一个元素为枢轴元素(如果随机选取,将随机选取到的元素与最后一个元素交换位置即可),并且不是从两头往中间进行比较,而是从左一直往右比较,思路从下面的图中很容易看出:


该思路的findposs(Partition)函数实现代码如下(代码中的small相当于上图中的i):
- /*
- 算法导论版快速排序
- */
- int Patrition(int *a,int low ,int high)
- {
- if(a==NULL || low>high)
- return -1;
- int small = low-1;
- int j;
- for(j=low;j<high;j++)
- {
- if(a[j]<a[high])
- {
- small++;
- if(small != j)
- swap(&a[small],&a[j]);
- }
- }
- small++;
- swap(&a[small],&a[high]);
- return small;
- }
下面加入随机选取枢轴元素的代码:
- /*
- 随机选取枢轴元素
- */
- int Random_Partition(int *A,int low,int high)
- {
- //设置随机种子
- srand((unsigned)time(0));
- int index = low + rand()%(high-low+1);
- swap(&A[index],&A[high]);
- return Partition(A,low,high);
- }
小总结
通常,快速排序被认为在所有同数量级(平均时间复杂度均为O(n*logn))的排序方法中,平均性能最好。但是若初始记录已经基本有序,这样每次如果还选择第一个元素作为枢轴元素,则再通过枢轴划分子序列时,便会出现“一边倒”的情况,此时快速排序就完全成了冒泡排序,这便是最坏的情况,时间复杂度为O(n*n)。所以通常枢轴元素的选择一般基于“三者取中”的原则,即比较首元素、末元素、中间元素的值,取三者中中间大小的那个。经验表明,采取这种方法可以大大改善快速排序在最坏情况下的性能。
快速排序需要一个栈来实现递归,很明显,如果序列中的元素是杂乱无章的,而且每次分割后的两个子序列的长度相近,则栈的最大深度为O(logn),而如果出现子序列“一边倒”的情况,则栈的最大深度为O(n)。因此就平均情况来看,快速排序的空间复杂度为O(logn)。
















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









