







在数据结构与算法中,包括在做《剑指OFFER》的过程中,很多时候都会用到递归,之前对尾递归概念模模糊糊的,看了很多前辈写的博客,这里对其做点总结。
1.递归:在计算机科学领域中,递归是通过递归函数来实现的,程序调用自身的编程技巧称为递归
还是从简单的阶乘来理解:计算n!
计算公式:n!=nx(n-1)x(n-2)......2x1;
使用递归的方式定义为:

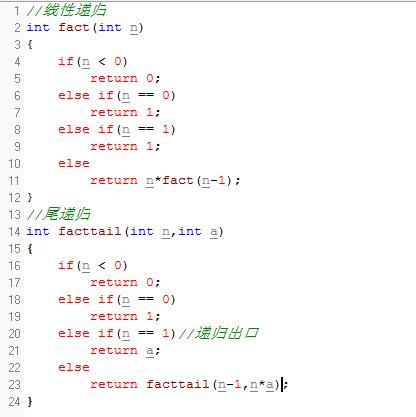
2.线性递归:线性递归函数的最后一步操作不是递归操作,而是其他的操作,这样的递归方式称为线性递归。这里我可以看到线性递归的最后一步是n*fact(n-1),是乘法而非递归。在每次递归调用时,递归函数中的参数,局部变量等都要进行压栈操作,当数据量很大的时候,会造成栈溢出
3.尾递归:尾递归函数的最后一步操作是递归,以上述代码为例:最后一步操作是facttail(n-1,n*a),即递归操作,所以是尾递归。这样的好处是,不用花费大量的栈空间来保存上次递归中的参数、局部变量等,即不需要重复压栈。这是因为上次递归操作结束后,已经将之前的数据计算出来,传递给当前的递归函数,所以尾递归只会占用衡量的内存
如何写尾递归?形式上只要最后一个return语句是单纯函数就可以。如:
return tailSum(x+1);而不是return tailSum(x+1)+x;
另外需要注意的是:
1.线性递归,函数在递归调用之前并没有完成全部计算,还需要调用递归函数完成后才能完成运算任务,比如return n * fact(n - 1);这句话,这个fact(n)在算完fact(n-1)之后才能得到n * fact(n - 1)的运算结果然后才能返回。
2.尾递归,函数在递归调用之前已经把所有的计算任务已经完毕了,他只要把得到的结果全交给子函数就可以了,无需保存什么,子函数其实可以不需要再去创建一个栈帧,直接把就着当前栈帧,把原先的数据覆盖即可。
3.编译器对尾递归的优化实际上就是当他发现在做尾递归的时候,就不会去不断创建新的栈帧,而是就着当前的栈帧不断的去覆盖,一来防止栈溢出,二来节省了调用函数时创建栈帧的开销
4.java,C#和python都不支持编译环境自动优化尾递归,而C支持尾递归
5.尾递归是把变化的参数传递给递归函数的变量;非尾递归,下一个函数结束以后此函数还有后续,所以必须保存本身的环境以供处理返回值。

















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









