







首先,做一下简介:Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
1、创建工程:选择一个文件夹,然后:scrapy startproject youku
2、进入文件夹:cd youku
3、创建py文件,制定采集网址后缀: scrapy genspider data youku.com
如图:

4、打开data.py文件进行主程序编写。
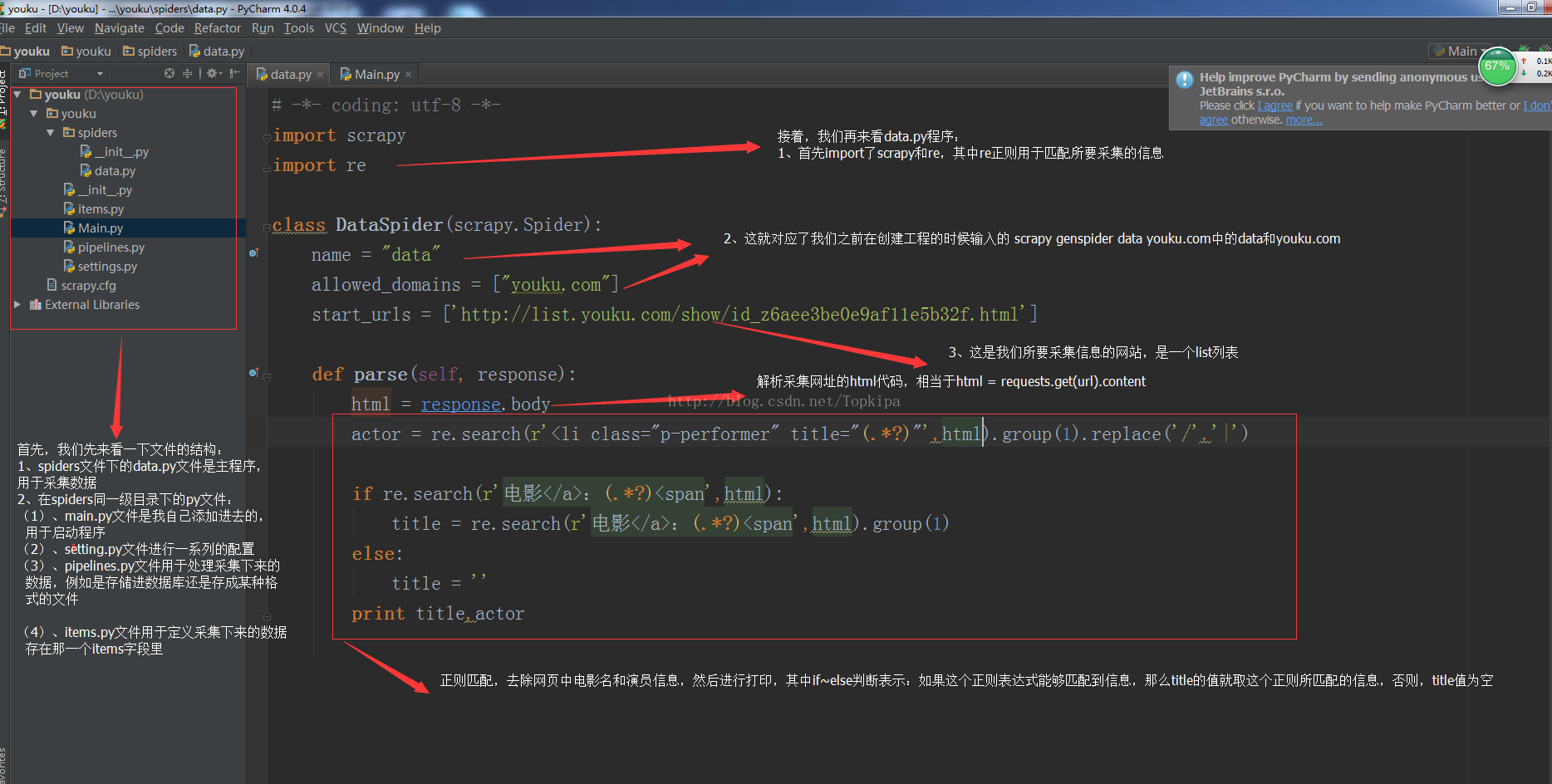
5、我们再来看一下正则匹配的一些内容
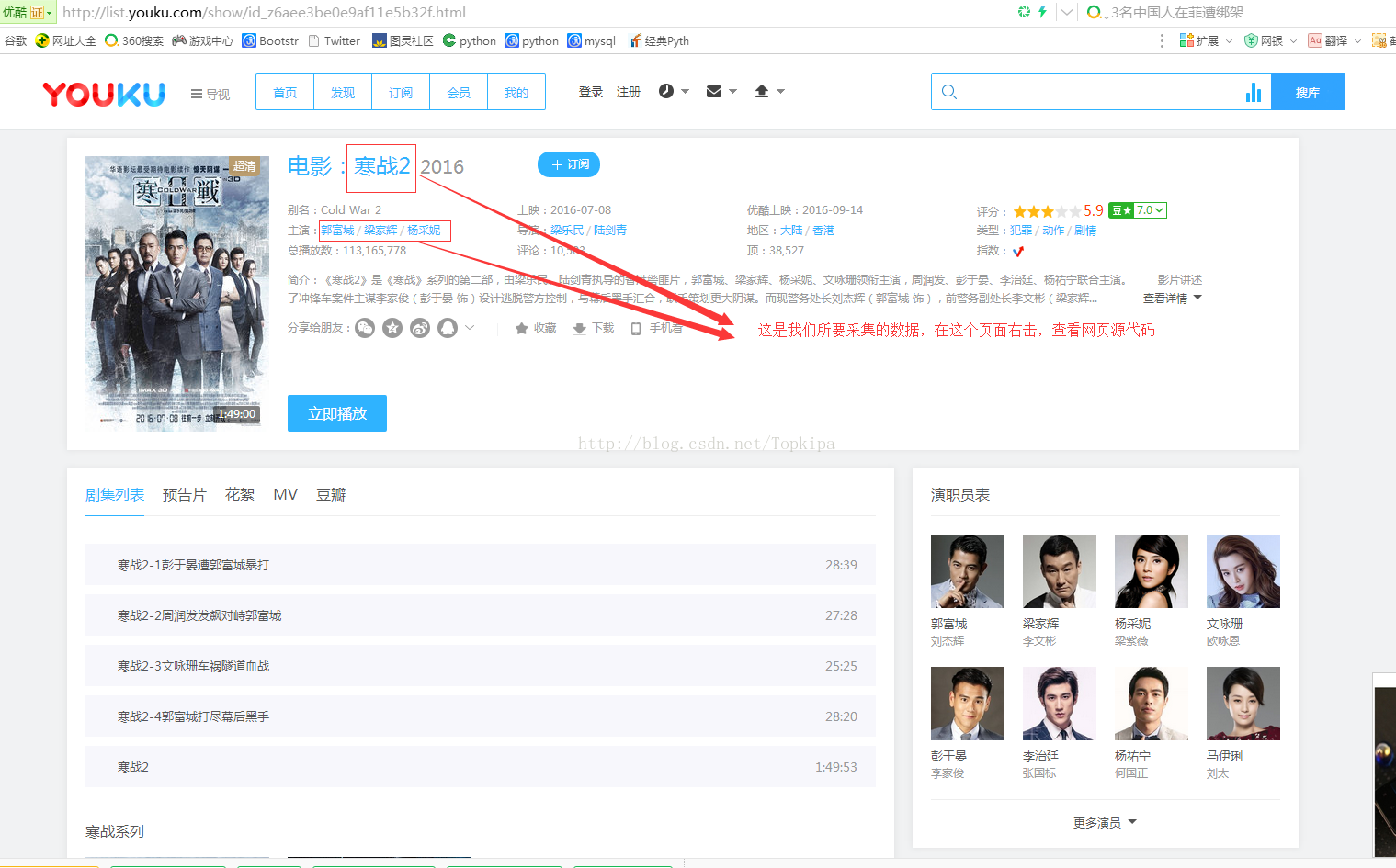
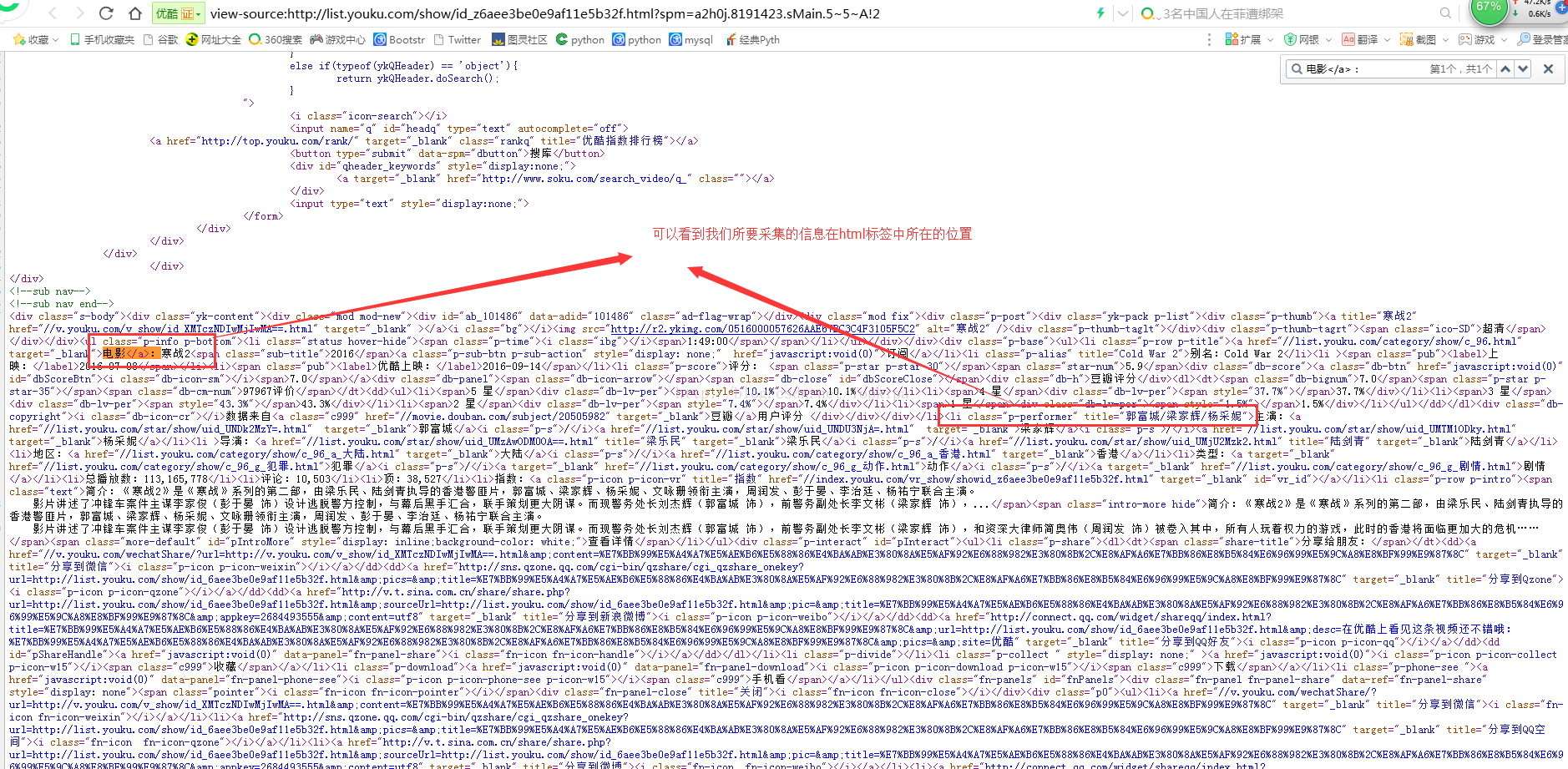
6、运行程序
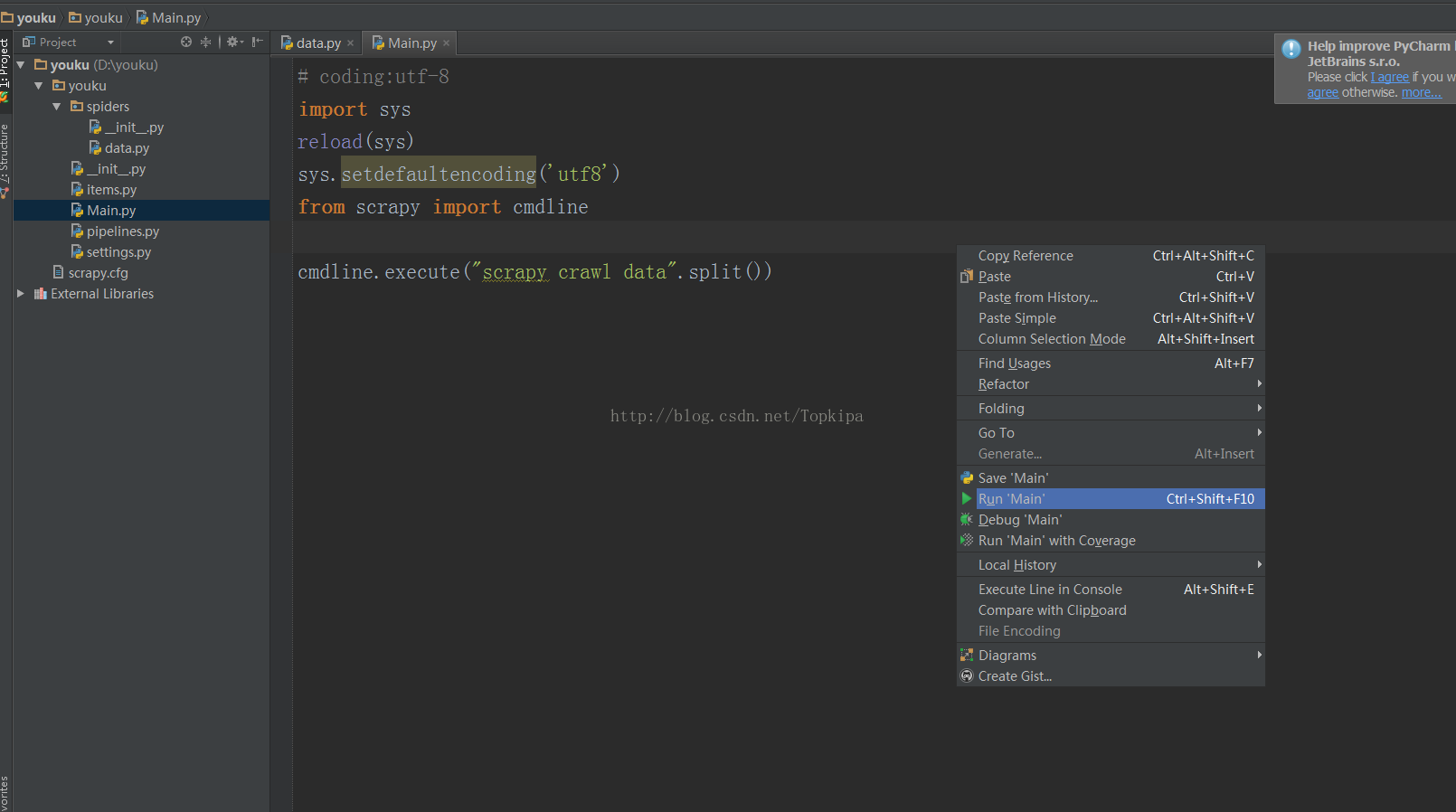
main.py中写入以下程序,然后右击运行
7、运行结果:

下一章节对数据采集入库,网页跳转,翻页进行讲解















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









