







九大排序算法
- 冒泡排序
- 插入排序
- 选择排序
- 快速排序
- 归并排序
- 堆排序
- 计数排序
- 基数排序
- 桶排序
注:
1. 以下遍历中用到了swap()函数,进行两个数的交换
2. 其中的伪代码参考自《算法导论第三版》
冒泡排序
冒泡排序是一种简单的排序算法。它重复地“走访”要排序的数列,一次比较两个元素,如果他们的顺序错误就进行交换。
时间复杂度:O(n^2)
最优时间复杂度:O(n)
平均时间复杂度:O(n^2)
空间复杂度:O(n),
需要辅助空间:O(1)
实现思路
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
实现代码
template <typename T>
void bubbleSort(T a[], int n) // n为数组的大小
{
for(int i = n; i >= 0; i--)
{
for(int j = 0; j < i; j++)
{
if(a[j] > a[j+1])
swap(a[j], a[j+1]);
}
}
}当然这种也可以
template <typename T>
void bubbleSort(T a[], int n)
{
for(int i = 0; i < n; i++)
for(int j = 0; j < n - 1; j++)
if(a[j] > a[j+1])
swap(a[j], a[j+1]);
}插入排序
当我们对少量元素进行排序的时候,插入排序不失为一种有效而又方便的排序算法
插入排序的伪代码
INSERTSORT(A)
for j = 2 to A.length
key = A[j];
i = j - 1;
while i > 0 and A[i] > key
A[i + 1] = A[i]
i = i -1
A[i + 1] = key实现思路
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
或者更通俗的讲,你可以将数组分类两部分,一部分为有序的即数组的第一个元素, 另一部分为除有序部分之外的元素。例如:a[0], a[1, n]。每次循环与有序的部分进行比较,插入有序的部分。
图解
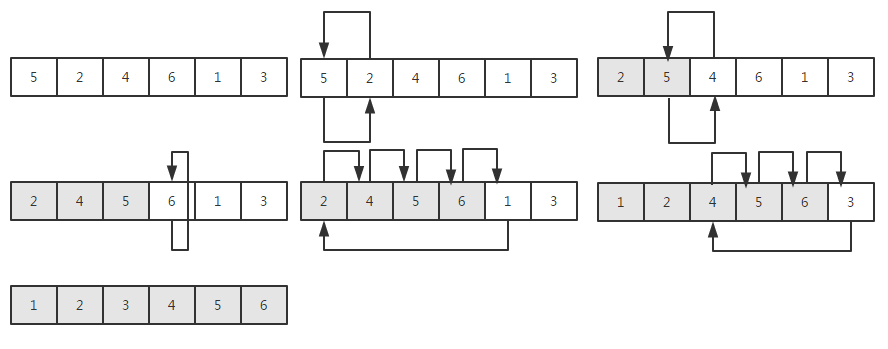
代码实现
template <typename T>
void insertSort(T a[], int n)
{
for(int i = 1; i < n; i++)
{
T t = a[i];
int j;
for(j = i -1 ; j >= 0 && t < a[j]; j--) // 这里循环遍历有序数组,把t插入有序数组
a[j+1] = a[j];
a[j+1] = t;
}
}选择排序
选择排序是一种简单直观的排序算法。
实现思路
它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
图解
任然拿上面的数组进行演示,这里以每次查找最大值为例
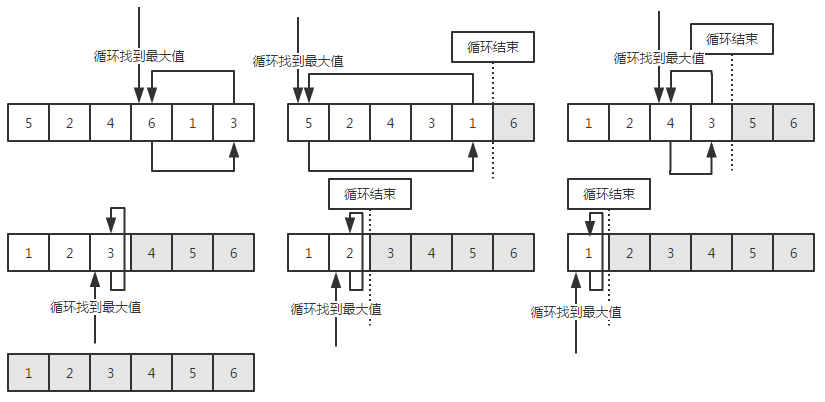
代码实现
template <typename T>
int findindex(T a[], int n)
{
int maxindex = 0;
for(int i = 1; i < n; i++)
{
if(a[maxindex] < a[i])
maxindex = i;
}
return maxindex;
}
template <typename T>
void selectSort(T a[], int n)
{
for(int i = n; i > 1; i--)
{
int maxindex = findindex(a, i);
swap(a[maxindex], a[i - 1]);
}
}当然如果你每次查找最小值的话,代码如下
template <typename T>
void selectionSort(T a[], int n)
{
for(int i = 0; i < n - 1; i++)
{
int min = i;
for(int j = i + 1; j < n; j++)
{
if(a[j] < a[min])
min = j;
}
swap(a[i], a[min]);
}
}
快速排序(快排)
快速排序通常是实际排序引用中最好的选择,因为它平均性能非常好
实现思路
- 将数组A[p…r]划分为两个子数组A[p…q-1]和A[q+1 … r],使得A[p…q-1]的每一个元素都小于A[q],而A[q+1 … r]的每一个元素都大于A[q]
- 通过递归调用快速排序,对子数组A[p…q-1]和A[q+1 … r]进行排序
伪代码
分为两段,一段递归调用,一段进行数组划分
QUICKSORT(A, p, r)
if p < r
q = PARTITION(A, p, r)
QUICKSORT(A, p, q-1)
QUICKSORT(A, q+1, r)PARTITION(A, p, r)
x = A[r]
i = p - 1
for j = p to r - 1
if A[j] <= x
i = i + 1
exchange A[i] with A[j]
exchange A[i + 1] with A[r]
return i + 1
图解
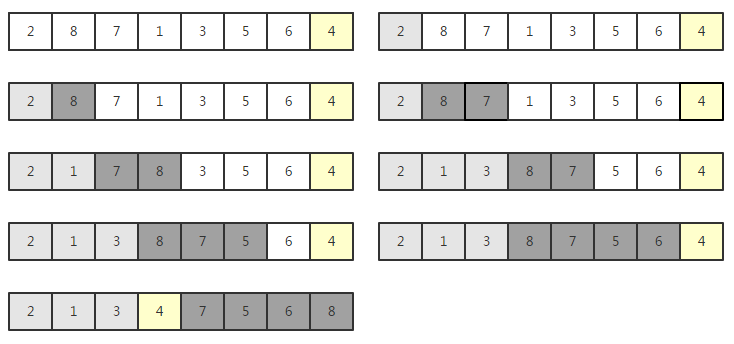
再分别对灰色和黑色数组进行快速排序,形成递归
代码实现
int partition(int a[], int p, int r)
{
int x = a[r];
int i = p - 1;
for(int j = p; j < r; j++)
{
if(a[j] <= x)
{
i += 1;
swap(a[i], a[j]);
}
}
swap(a[i+1], a[r]);
return i + 1;
}
void quickSort(int a[], int p, int r)
{
if(p < r)
{
int q = partition(a, p, r); // 第一次找出图中黄颜色的下标
quickSort(a, p, q - 1); // 递归灰色数组
quickSort(a, q + 1, r); // 递归黑色数组
}
}归并排序
归并排序算法完全遵循分治模式。而分治模式的三个步骤分别为“分解”,“解决”,“合并”。其中归并算法的关键操作是“合并”。
实现思路
假设我们有一副牌分为A,B两幅,并且每一副牌都已经排序好
1. 我们逐个比较两幅牌,如果A的第一张牌小于B的第一张牌,则A的第一张牌入队
2. 继续比较,A的第二张牌和B的第一张牌,较小的一张牌入队,如此重复直到遍历完所有牌
图解

然而我们大多数情况下, 一个数组分为两个小数组不可能两个数组都排序好的,那么我们就应该一步一步的往上推
思路和原来一样,只是现在的对象变为A(B),然后将A(B)再分为两副牌,对A(B)进行排序,一直往下递归,直至排序好。
伪代码
MERGE(A, p, q, r)
n1 = q - p + 1
n2 = r - 1
let L[1...n1 + 1] and R[1...n2 + 1] be new arrays
for i = 1 to n1
L[i] = A[p + i - 1]
for j = 1 to n2
R[j] = A[q + j]
L[n1 + 1] = -∞
R[n2 + 1] = -∞
for k = p to r
if L[i] <= R[j]
A[k] = L[i]
i = i + 1
else
A[k] = R[j]
j = j+1MERGE-SORT(A, p, r)
if p < r
q = [(p + r) / 2]
MERGE-SORT(A, p, q)
MERGE-SORT(A, q + 1, r)
MERGE(A, p, q, r)代码实现
void merge(int Array[], int p, int q, int r)
{
int n1 = q - p + 1;
int n2 = r - q;
int* lArray = new int[n1];
int* rArray = new int[n2];
for(int i = 0; i < n1; ++i) {
lArray[i] = Array[p + i];
}
for(int i = 0; i < n2; ++i) {
rArray[i] = Array[q + i + 1];
}
int i = 0;
int j = 0;
int k = p;
while(i < n1 && j < n2) {
if(lArray[i] <= rArray[j]) {
Array[k] = lArray[i];
i++;
}
else {
Array[k] = rArray[j];
j++;
}
k++;
}
while(i < n1) {
Array[k++] = lArray[i++];
}
while(j < n2) {
Array[k++] = rArray[j++];
}
}
void mergeSort(int Array[], int p, int r)
{
if(p < r) {
int q = p + (r - p) / 2;
mergeSort(Array, p, q);
mergeSort(Array, q + 1, r);
merge(Array, p, q, r);
}
}堆排序
要想理解堆排序首先需要知道什么是堆,这里我们利用二叉(最大)堆进行排序。二叉堆可以近似看成一个完全二叉树。其中又分为最大堆和最小堆。在最大堆中,最大堆性质是指除了根以外的所有节点i都要满足: A[parent(i)] >= A[i]。也就是说堆中的最大元素存放在根节点中。而最小堆真好相反。
实现思路
- 首先根据推导我们很容易知道它的父节点,左孩子和右孩子下标的计算方式.用于维护最大堆
// 父节点
int parent(int i)
{
return i / 2;
}
// 左子树
int left(int i)
{
return 2 * i;
}
// 右子树
int right(int i)
{
return 2 * i + 1;
}- 建立一个最大二叉堆,并且在建立最大堆的同时要维护最大堆的性质
- 由于最大堆的性质,他的堆中最大元素肯定处于顶层根节点中,因此每次只需要把最大元素取出来,在对剩下的元素重新维护,形成新的最大堆,再接着取最顶层的最大值,依次类推,直到最后一个
实现代码
#include <iostream>
#include <climits>
using namespace std;
int parent(int i)
{
return i / 2;
}
int left(int i)
{
return 2*i;
}
int right(int i)
{
return 2*i + 1;
}
/* 维护堆 */
void Max_HeapIfy(int a[], int i, int heap_size)
{
int l = left(i);
int r = right(i);
int largest;
if(l <= heap_size && a[l] > a[i])
largest = l;
else
largest = i;
if(r <= heap_size && a[r] > a[largest])
largest = r;
if(largest != i)
{
swap(a[i], a[largest]);
Max_HeapIfy(a, largest, heap_size);
}
}
/* 建立最大堆 */
void Build_Max_Heap(int a[], int heap_size)
{
for(int i = heap_size / 2; i > 0; i--)
Max_HeapIfy(a, i, heap_size);
}
/* 堆排序 */
void HeapSort(int a[], int heap_size)
{
Build_Max_Heap(a, heap_size);
for(int i = heap_size; i >= 0; i--)
{
swap(a[0], a[i]);
heap_size -= 1;
Max_HeapIfy(a, 0, heap_size);
}
}
int main()
{
int a[11] = {INT_MIN , 4, 5, 3, 3, 1, 19, 10, 14, 8, 7};
HeapSort(a, 10);
for(int i = 0; i < 10; i++) // for(int i = 0; i < 11; i++) 如果改成这样子会怎么样?
cout << a[i] << " ";
cout << endl;
return 0;
}
计数排序
在前面介绍的6中排序都有一个共同的特点:在排序的最终结果中,各元素的次序依赖于它们之间的比较。所以我们又把这类排序叫做比较排序。而计数排序和基数排序,以及接下来的桶排序则不是运用比较来确定排序顺序的。
实现思路
计数排序假设n个输入元素中的每一个都是在0到k区间的一个整数,其中k为某个整数。
对每一个输入元素x,确定小于x的元素个数。利用这一信息,就可以直接把x放到它在输出数组的位置上了。例如,如果有17个元素小于x,则x就应该放在第18个输出位置上。
伪代码
COUNT-SORT(A, B, k)
let C[0...k] be a new array
for i = 0 to k
C[i] = 0
for j = 1 to A.length
C[A[j]] = C[A[j]] + 1
for i = 1 to k
C[i] = C[i] + C[i - 1]
for j = A.length downto 1
B[C[A[j]]] = A[j]
C[A[j]] = C[A[j]] - 1由于代码中存在三个for循环,我个人喜欢叫它为三for排序
代码实现
void CountingSort(int a[], int b[], int k, int arr_size)
{
int *c = new int[k + 1]{0};
for(int j = 0; j < arr_size; j++)
c[a[j]] = c[a[j]] + 1;
for(int i = 1; i <= k; i++)
c[i] = c[i] + c[i-1];
for(int j = arr_size - 1; j >= 0; j--)
{
b[c[a[j]]] = a[j];
c[a[j]] = c[a[j]]-1;
}
delete[] c;
}基数排序
基数排序是先按最低有效位进行排序的排序算法
实现思路
- 从最低有效位进行排序,如下图的个位开始排序
- 个位排序完排十位,接下来是百位
而每一个位的排序则用到了计数排序的思路
图解
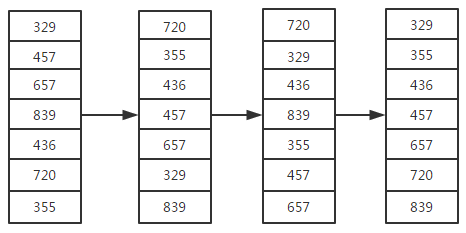
代码实现
// 假设n个d位的元素存放在数组A中,其中第一位是最低位,第d位是最高位
void radixSort(int a[], int b[], int len, int d)
{
int *arrC = new int[10]; //most 10 numbers;
int radix = 1;
for (int k = 1; k <= d; k ++) {
//using CountingSort for every bit;
for (int i = 0; i < 10; i ++)
arrC[i] = 0;
for (int i = 0; i < len; i ++) {
int temp = (a[i]/radix) % 10; //find every bit of a number
arrC[temp] = arrC[temp] + 1;
}
for (int i = 1; i < 10; i ++)
arrC[i] = arrC[i] + arrC[i-1];
for (int j = len-1; j >= 0; j --) {
int temp = (a[j]/radix) % 10;
b[arrC[temp] - 1] = a[j];
arrC[temp] = arrC[temp] - 1;
}
radix *= 10; //another bit;
memcpy(a, b, len * sizeof(int)); //note this line;
}
}桶排序
这里利用链表存储数组元素
实现思路
- 设置一个定量的数组当作空桶子。
- 寻访序列,并且把项目一个一个放到对应的桶子去。
- 对每个不是空的桶子进行排序。
- 从不是空的桶子里把项目再放回原来的序列中。
代码实现
typedef struct BucketNode{
double nValue;
BucketNode *pNext;
}Node;
void BucketSort_Link(double arrA[], int nLen)
{
Node *pBucket = new Node[10];
//initial the bucket
for (int i = 0; i < 10; i ++) {
pBucket[i].nValue = 0.0;
pBucket[i].pNext = NULL;
}
for (int i = 0; i < nLen; i ++) {
double nTemp = arrA[i];
Node *pNode = new Node();
pNode->nValue = nTemp;
pNode->pNext = NULL;
int nKey = int(arrA[i]*10);
if (pBucket[nKey].pNext == NULL) {
pBucket[nKey].pNext = pNode; //每个桶的第一个位置不存数据
}
else {
Node *p = &pBucket[nKey]; //p-->q
Node *q = pBucket[nKey].pNext;
while (q && q->nValue <= nTemp) {
p = q;
q = q->pNext;
}
pNode->pNext = q;
p->pNext = pNode;
}
}
int k = 0;
for (int i = 0; i < 10; i ++) {
Node *pTemp = pBucket[i].pNext;
while (pTemp) {
arrA[k ++] = pTemp->nValue;
pTemp = pTemp->pNext;
}
}
}














 854
854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









