







| 算法 | 预处理时间 | 匹配时间 |
|---|---|---|
| 朴素算法 | 0 | O((n-m+1)m) |
| Rabin-Karp | Θ(m) | O((n-m+1)m) |
| KMP算法 | Θ(m) | Θ(n) |
术语
前缀和后缀
如果对某个字符串y∈∑*有x = wy, 则称字符串w是字符串x的前缀,记做 w ⊂ x。
如果对某个字符串y∈∑*有x = yw, 则称字符串w是字符串x的后缀,记做 w ⊃ x。
朴素字符串匹配算法
描述
朴素字符串匹配算法是通过一个循环找到所有有效偏移地址,该循环对n-m+1个可能的s值进行检测,看是否满足条件P[1..m] = T[s+1..s+m]。
图说明
如下图所示,文本T = “acaabc”,P = “aab”,在对文本T进行循环的时候,隐藏着一个循环,该循环用于逐个检测对应位置上的字符,直到所有位置都能够成功匹配或者有一个位置不能匹配为止。

伪代码
NAVIE-STRING-MATCHER(T,P)
n = T.length
m = P.length
for s = 0 to n - m
if P[1..m] == T[s + 1 .. s + m]
print "Pattern occurs with shift"代码实现
由于实现相对简单,这里对代码不在做过多的说明,核心在于遍历文本的过程,如果成功匹配第一个元素,则遍历模板,进行内部匹配。
// 朴素字符串匹配算法
// 匹配时间为O((N-M+1)M)
// 输出文本T中子串出现的次数
int Naivie_String_matcher(string T, string P)
{
int num = 0;
int n = T.size();
int m = P.size();
for(int s = 0; s <= n - m; ++s) {
if(T[s] == P[0]) {
int k = 0;
for(int i = 0; i < m; ++i) {
if(T[s + i] == P[i]) {
++k;
}
else {
break;
}
}
if(k == m) {
++num;
}
}
}
return num;
}Rabin-Karp算法
描述
Rabin-Karp算法又叫做RK算法(下面都用这个简称),它的预处理时间为Θ(m),并且在最坏情况下,它的运行时间为Θ((n-m+1)m)。在实际情况下,它相对于朴素算法来说,是比较好的。
RK算法主要是利用两个数相对于第三个数模等价的概念。
例如:假设
A % B = C
D % B = C
即便不能判断A一定等于D , 但是如果取模不相等,那么A一定不等于D,所以可以用来提高效率
图说明
如下图, 我们选取的字符串T为“234590314121204”和模板字符串P为“3141”。我们将m个字符串转为d进制的数字(这里我们用十进制表示),转换后的整数取模进行匹配。当寻找到模相等的时候在进行内部匹配,检测是否为合法匹配。

相应的数学公式
先思考一个问题,如何将字符串“31415”转换为十进制的31415?
我们可以容易知道
31415 = 3 × 10000 + 1 × 1000 + 4 × 100 + 1 × 10 + 5
即
31415 = ((((3 × 10 + 1) × 10 + 4 ) × 10) + 1 ) × 10 + 5
由上面的等式我们可以知道,给定一个模式P[1..m],假设p表示其相应的十进制值。那么我们利用霍纳法则得
利用循环的方式我们可以简化代码,其中i为0到m
对应的C++代码
for(int i = 0; i < m; ++i) {
p = (d * p + P[i]) ;
}当文本移动的时候
例如m = 5时,T = “31245678”,t_0 = 31245, t_1= 12456
如何得到t_1的值?这是我们要思考的第二个问题。可以看得出 t_1的值为t_0去掉最高位“3”和加末尾加上“6”,因此
归纳后得
相应的C++代码
//h = static_cast<int>(pow(d, m - 1));
t = d * (t - T[s] * h) + T[s + m];伪代码
RABIN-KARP-MATCHER(T,P,d,q)
n = T.length
m = P.length
h = d^(m - 1) mod q
p = 0
t0 = 0
for i = 1 to m
p = (dp + P[i]) mod q
t0 = (dt0 + T[i]) mod q
for s = 0 to n - m
if p == t(s)
if P[1..m] == T[s + 1 .. s + m]
print "Pattern occurs with shift"s
if s < n - m
t(s+1) = (d(t(s) - T[s + 1] * h) + T[s + m + 1]) mod q代码
本人没有完全按照上面的伪代码实现,本代码在VS2013上可以成功运行,但在sublime3上有个bug,对于匹配纯数字字符串,它可以完美匹配,在字符字符串上,只能部分匹配。例如:文本为“abcdefghijdefgkldefg”,对应模板为“d”,“de”,“def”,“defgh”。。。“defghij”中“def”和“defgh”无法匹配成功。置于原因可以与我探讨。
// Rabin-Karp算法
// 预处理时间(M),匹配时间O((N-M+1)M),实际优于朴素算法
// d : 表示字符都是由d为基数表示的数字
// q : 素数,用于模计算
// 输出子串出现的次数
int Rabin_Karp_matcher(string T, string P, int d, int q)
{
int num = 0;
int n = T.size();
int m = P.size();
// 计算h
int h = static_cast<int>(pow(d, m - 1));
/*int pow_d = 1;
for(int i = 0; i < m - 1; ++i) {
pow_d *= d;
}
int h = pow_d % d;*/
// p和t0用于求出相应的子串对应的d进制整数
/*
相应数学公式(霍纳法则)
p = P[m] + d(P[m - 1] + d(P[m - 2] + d(P[m - 3] + ... + d(P[2] + dP[1])...))
可以看出一共有(m-1)个d
通过数学归纳法我们可以知道
p = (d * p + P[i]))
又因为要取模
易知p(总) % q 和每次计算的出的p % q是一样的
*/
int p = 0;
int t = 0;
for(int i = 0; i < m; ++i) {
p = (d * p + P[i]) % q;
t = (d * t + T[i]);
}
for(int s = 0; s <= n - m; ++s) {
if(p == (t % q)) {
int k = 0;
for(int i = 0; i < m; ++i) {
if(T[s + i] == P[i]) {
++k;
}
else {
break;
}
}
if(k == m) {
++num;
cout << "The position : " << s + 1 << endl;
}
}
// 前面我们之算出了T的前m个字符对应的d进制的值,如果不匹配,那么需要往下移动一个字符
// 所以我们需要去除最前面的数,在尾部加入新的数,例如m = 5时,T = "31245678",t(0) = 31245, t(1) = 12456
// 根据公式
// t(s+1) = d * (t(s) - d^(m - 1) * T[s + 1]) + T[s + m + 1]
// 其中h % q = d^(m-1)
// h 是一个具有m数位的文本窗口的高位数的数位上的数字“1”的值。
if(s < n - m) {
t = (d * (t - T[s] * h) + T[s + m]);
}
}
return num;
}Knuth-Morris-Pratt算法
建议看之前先看一篇国外的关于KMP算法的博客:The Knuth-Morris-Pratt Algorithm in my own words
描述
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的关键在于部分匹配表的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是实现一个compute_prefix_function()函数,函数本身包含了模式串的局部匹配信息。时间复杂度O(m+n)。
当我们进行匹配的时候,假设文本T =“bacbababaabcbab”和模板 P = “ababaca”
当我们进行字符串匹配的时候,如果匹配到成功的字符,那么它将进行内循环,如下图所示
逐一匹配
检索字符
检索字符
检索字符
当匹配到不相同的时候开始进行跳步
根据部分匹配表(Partial Match Table)
char : | a | b | a | b | a | c | a |
index: | 0 | 1 | 2 | 3 | 4 | 6 | 7 |
value: | 0 | 0 | 1 | 2 | 3 | 0 | 1 |






查表可知,最后一个匹配字符a对应的”部分匹配值”为3
因此按照下面的公式算出向后移动的位数:移动位数 = 已匹配的字符数 - 对应的部分匹配值(value)
因为 5 - 3 等于2,所以将搜索词向后移动2位。
- 跳两步
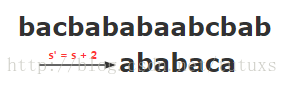
分析
上图简单介绍了下KMP进行匹配时候的运行原理,现在我们来进行分析KMP算法的正确性,然后再来搞清楚怎么获取到部分匹配表。
假设模式字符P[1..q]与文本字符T[s + 1.. s + 1]匹配,s’是最小的偏移量,s’>s,那么对某些k < q ,满足
P[1..k] = T[s’ + 1 .. s’ + k]
的最小偏移s’>s是多少,其中s’+ k = s + q。换句话说,已知P_q⊃P_k,我们希望P_q的最长真前缀P_k也就是T_(s+q)的后缀。
即:已知一个模式P[1..m],模式P的前缀函数是函数π:{1,2,….,m}->{0,1,…,m-1},满足
π[q] = max{k:k < q 且 P_k ⊃ P_q}
即π[q]是P_q的真后缀P的最长前缀长度。
什么是前缀和后缀
要知道部分匹配表的由来,首先,要了解两个概念:”前缀”和”后缀”。
“前缀”指除了最后一个字符以外,一个字符串的全部头部组合。
“后缀”指除了第一个字符以外,一个字符串的全部尾部组合。
例如:字符串“ABCDEF”,那么它的前缀和后缀分别为
前缀:“A”,“AB”,“ABC”,“ABCD”,“ABCDE”
后缀:“BCDEF”,“CDEF”,“DEF”,“EF”,“F”
部分匹配表
算法导论书上说的有点不是很清楚,我们可以换一种思路,来得到部分匹配表。
对于模式P = “ababaca”,从左到右依次增加一个字符
当下标为0的时候
“a” 的前缀和后缀都没有,故部分匹配表里的 value=0当下表为1的时候
“ab”的前缀为:“a”,后缀为“b”,由于前缀和后缀不相同,故 value = 0当下标为2的时候
“aba”的前缀为:“a”,“ab”,后缀为“ba”,“a”,由于前缀和后缀有一个相同,且最长度为1,故 value = 1当下标为3的时候
“abab”的前缀为:“a”,“ab”,“aba”,后缀为:“bab”,“ab”,“b”,由于前缀和后缀有一个相同,且最长度为2,故 value = 2当下标为4的时候
“ababa”的前缀为:“a”,“ab”,“aba”,“abab”,后缀为:“baba”,“aba”,“ba”,“a”,前缀和后缀有两个相同,但是最长长度为3,故 value = 3
以此类推,就能得出所有的部分匹配表
代码实现
int* compute_prefix_function(string P_string)
{
int P_length = P_string.size();
int* PI = new int[P_length];
PI[0] = 0;
int k = 0;
for(int q = 1; q < P_length; ++q) {
while(k > 0 && P_string[k] != P_string[q]) {
k = PI[k];
}
if(P_string[k] == P_string[q]) {
k += 1;
}
PI[q] = k;
}
return PI;
}整体代码
得出部分匹配表后,剩下的就是根据部分匹配表里的值,进行跳步。
关键点就是下一个有效偏移s'= s + (q - π[q]),这里s表示有效偏移,q表示匹配的字符长度,π[q]表示对应部分匹配表里的信息
int* compute_prefix_function(string P_string)
{
int P_length = P_string.size();
int* PI = new int[P_length];
PI[0] = 0;
int k = 0;
for(int q = 1; q < P_length; ++q) {
while(k > 0 && P_string[k] != P_string[q]) {
k = PI[k];
}
if(P_string[k] == P_string[q]) {
k += 1;
}
PI[q] = k;
}
return PI;
}
// Knuth-Morris-Pratt算法
// 预处理时间Θ(m),匹配时间Θ(N)
// 输出子串出现的次数
int Knuth_Morris_Pratt_matcher(string T, string P)
{
int num = 0;
int n = T.size();
int m = P.size();
int k = 0;
int* tb = compute_prefix_function(P);
for(int i = 0; i < n; ++i) {
if(k > 0 && T[i] != P[k]) { // 进行跳步
i += k - tb[k]; // s'= s + (q - π[q])
k = 0;
}
if(T[i] == P[k]) {
k = k + 1;
}
if(k == m) {
++num;
cout << "The position : " << i - k + 2 << endl;
k = 0;
}
}
return num;
}拓展
字符串匹配算法还有很多,例如:Boyer-Moore algorithm,神奇的Sunday algorithm等等。
以后有机会,会把BM算法和Sunday算法加上。















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









