







一、神器XPath的介绍与配置
1 XPath是什么?
XPath,即XML路径语言(XML Path Language),是确定XML文档中某位置的语言,基于XML的树状结构,提供在数据结构树中寻找节点的能力。
简言之,XPath是一门语言,可以在XML文档中查找信息,支持HTML,通过元素和属性进行导航;
XPath用以提取信息,类似于正则表达式,但比正则表达式厉害、简单,因为使用正则表达式时即使是正确的,却也没法获取需要的信息,或网页原代码结构复杂,不知道如何使用正则表达式进行匹配。
2 安装lxml库
方法1:使用easyinstall
方法2:使用pip install lxml
方法3;https://pypi.python.org/pypi,搜索lxml,选择lxml 3.5.0 package,显示最新版本是3.6.0,点击进入,根据自己安装Python版本、计算机32位/64位,选择以.whl为扩展名的lxml File——lxml-3.6.0-cp27-none-win_amd64.whl (md5)进行下载,将文件扩展名修改成.zip,打开并把压缩文件的中的lxml文件夹放置在安装Python目录下的Lib文件夹中
3 使用lxml库
from lxml import etree # 导入etree
Selector=etree.HTML(网页源代码) # 转化成被xpath识别和匹配的对象,并赋值给Selector变量
Selector.xpath(一段神奇的符号) # 提取感兴趣的内容
二、神器XPath的使用
先导问题:想要找到极客学院的办公大楼
使用正则表达式:寻找的大楼左边有一个三角形的建筑,右边有一个圆形建筑,而中国很大,需要很多时间才能找到;
使用XPath:寻找的大楼在北京市海淀区某某路某某号;
1 XPath与HTML结构
HTML是树状结构,可逐层展开, 利用该特点可逐层定位,在逐层定位的基础上寻找独立节点。
举例:
打开一个网站:
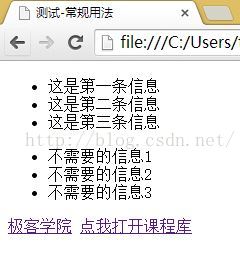
查看器源代码:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>测试-常规用法</title>
</head>
<body>
<div id="content">
<ul id="useful">
<li>这是第一条信息</li>
<li>这是第二条信息</li>
<li>这是第三条信息</li>
</ul>
<ul id="useless">
<li>不需要的信息1</li>
<li>不需要的信息2</li>
<li>不需要的信息3</li>
</ul>
<div id="url">
<a href="http://jikexueyuan.com">极客学院</a>
<a href="http://jikexueyuan.com/course/" title="极客学院课程库">点我打开课程库</a>
</div>
</div>
</body>
</html>使用正则表达式匹配时,使用先抓大后抓小原则,先匹配ul标签,在匹配的结果中再匹配li标签,需要使用多行代码才能实现;
使用XPath匹配时,只需要一行代码即可实现:
2 获取网页元素的XPath
2.1 手动分析法
html -> body -> div -> ul[@useful] -> li
2.2 Chrome生成法
右击页面点击审核元素 -> 对想要的信息的一行(“这是第一条信息”)右击点击Copy Xpath -> 粘贴到记事本,内容是//*[@id="useless"]/li[1]
其中,id="useless"对应标签<ul id="useful">;又因为整个源代码只有一处id="useful",因此只是用id即可,不用指定标签,使用*代替;li[1]只代表第一条信息,若想要所有信息,需要li,则以列表形式返回;//表示从什么地方开始,
3 应用Xpath提取内容
//定位根节点
/往下层寻找
/text()提取文本内容
/@XXX提取XXX属性内容
#-*-coding:utf8-*-
import lxml
from lxml import etree
html = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>测试-常规用法</title>
</head>
<body>
<div id="content">
<ul id="useful">
<li>这是第一条信息</li>
<li>这是第二条信息</li>
<li>这是第三条信息</li>
</ul>
<ul id="useless">
<li>不需要的信息1</li>
<li>不需要的信息2</li>
<li>不需要的信息3</li>
</ul>
<div id="url">
<a href="http://jikexueyuan.com">极客学院</a>
<a href="http://jikexueyuan.com/course/" title="极客学院课程库">点我打开课程库</a>
</div>
</div>
</body>
</html>
'''
# 转化成被xpath识别和匹配的对象,并赋值给Selector变量
selector = etree.HTML(html)
#提取文本
content = selector.xpath('//ul[@id="useful"]/li/text()')
# 限定id="useful"属于ul标签
# content = selector.xpath('//ul/li/text()')获取的内容有需要的和不需要的
# 因为ul标签里的id="useful"是独一无二的,可直接寻找;但保险写法是content=Selector.xpath('//div[@id="content"]/ul[@id="useful"/li/text()]')
for each in content:
print each
print
#提取属性href
link = selector.xpath('//a/@href')
# 保险写法link=Selecotr.xpath('//div[@id="url"]/a/@href')
for each in link:
print each
print
#提取属性title
title = selector.xpath('//a/@title')
print title[0]运行程序:
这是第一条信息
这是第二条信息
这是第三条信息
http://jikexueyuan.com
http://jikexueyuan.com/course/
极客学院课程库
三、神器XPath的特殊用法
1 以相同的字符开头
使用start-with(@属性名称, 属性字符相同部分);
用以处理如下形式:
#-*-coding:utf8-*-
from lxml import etree
html1 = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test-1">需要的内容1</div>
<div id="test-2">需要的内容2</div>
<div id="testfault">需要的内容3</div>
</body>
</html>
'''
# 想要提取这三部分内容,而其id内容是不同的,但前4个字符都是test
# 使用正则表达式也可以提取,但需要对其分别识别,即使用三行代码才能实现
# 而是用xpath只需要一行代码就可解决
selector=etree.HTML(html1)
content=selector.xpath('//div[starts-with(@id,"test")]/text()')
# 提取在id属性值以test开头的所有div标签,并以列表形式返回
for each in content:
print each执行结果:
需要的内容1
需要的内容2
需要的内容3
2 标签套标签
使用string(.)过滤多余标签;
用以处理如下形式,想要提取整个内容:
<div id="test3">
我左青龙,
<span id="tiger">
右白虎,
<ul>上朱雀,
<li>下玄武。</li>
</ul>
老牛在当中,
</span>
龙头在胸口。
</div>2.1 先结合上节知识进行匹配:
#-*-coding:utf8-*-
from lxml import etree
html2 = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test3">
我左青龙,
<span id="tiger">
右白虎,
<ul>上朱雀,
<li>下玄武。</li>
</ul>
老牛在当中,
</span>
龙头在胸口。
</div>
</body>
</html>
'''
selector=etree.HTML(html2)
content=selector.xpath('//div[@id="test3"]/text()')
for each in content:
print each执行结果:
结果只提取了第一句和最后一句内容;
用此方法只能提取div标签直接的文字内容,无法提取div标签内其他标签的直接内容。
我左青龙,
龙头在胸口。
2.2 再用string(.)进行匹配:
#-*-coding:utf8-*-
from lxml import etree
html2 = '''
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title></title>
</head>
<body>
<div id="test3">
我左青龙,
<span id="tiger">
右白虎,
<ul>上朱雀,
<li>下玄武。</li>
</ul>
老牛在当中,
</span>
龙头在胸口。
</div>
</body>
</html>
'''
# 使用先大后小的方法,首先提取id属性为test3的div标签,对返回的元素继续使用xpath
selector=etree.HTML(html2)
data=selector.xpath('//div[@id="test3"]')[0]
info=data.xpath('string(.)')
content=info.replace('\n','').replace(' ','')
print content执行结果:
我左青龙,右白虎,上朱雀,下玄武。老牛在当中,龙头在胸口。
四、Python并行化介绍与演示
1 Python并行化介绍
多个线程同时处理任务,更加高效、快速;
2 map的使用
map函数一手包办了序列操作、参数传递和结果保存等一系列的操作;
首先导入Pool类,再实例化Pool,然后指定爬取函数即网址列表进行并行化处理:
from multiprocessing.dummy immport Pool
pool = Pool(4) # 表示四核
results = pool.map(爬取函数名, 网址列表)举例:
#-*-coding:utf8-*-
from multiprocessing.dummy import Pool as ThreadPool
# 导入Pool类,并重命名为ThreadPool
import requests
import time
def getsource(url):
html = requests.get(url)
urls = []
for i in range(1,21):
newpage = 'http://tieba.baidu.com/p/3522395718?pn=' + str(i)
urls.append(newpage)
time1 = time.time() # 开始计时
for i in urls:
print i
getsource(i)
time2 = time.time() # 结束计时
print u'单线程耗时:' + str(time2-time1)
pool = ThreadPool(4)
time3 = time.time()
results = pool.map(getsource, urls)
pool.close()
pool.join()
time4 = time.time()
print u'并行耗时:' + str(time4-time3)运行结果:
单线程耗时:9.08299994469
并行耗时:2.625
五、实战——百度贴吧爬虫
1 目标网站
http://tieba.baidu.com/p/3522395718
2 目标内容
前20页的跟帖用户名、跟帖内容、跟帖时间
3 涉及知识点
requests获取网页源代码、xpath获取网页内容、map实现多线程爬虫
4 步骤
1‘ 确定爬虫内容目标网站
点击以上网站转到该帖吧的首页,点击下一页时网站更改为:http://tieba.baidu.com/p/3522395718?pn=2;
由此确定前20页的网站为:http://tieba.baidu.com/p/3522395718?pn=<num>,其中<num>取值为1~20;
2’ 使用Chrome的审核元素功能确定爬取内容的位置
点击左侧放大镜,鼠标移至要爬取的内容(这里指“跟帖内容”)并点击,审核元素自动定位到相应位置;
右击拷贝XPath,粘贴至文本中,观察到其中的"62866844122"在每个跟帖内容都不一样,因此无法使用现成的XPath作为定位标志进行匹配;
//*[@id="post_content_62866844122"]
只能观察并获取要爬取内容的对应路径,折叠代码发现每个跟帖信息都在class属性值为"l_post j_l_post l_post_bright "div的标签的中;
跟帖用户名、跟帖时间分别在上述div标签中data-field属性中的author的user_name中和content的date中;
跟帖内容在上述标签的元素子节点class属性值为"d_post_content_main"的元素子节点div标签下的元素子节点cc标签下的元素子节点class属性值为"d_post_content j_d_post_content clearfix"下的文本内容;
3’ 编程前注意事项
data-field保存的数据是JSON格式,需要导入json模块进行JSON解析;
(也可以使用正则表达式解析)
5 代码
#-*-coding:utf8-*-
from lxml import etree #使用xpath进行定位
from multiprocessing.dummy import Pool as ThreadPool # 使用map进行并行化处理
import requests
import json # 百度贴吧的data-field属性值是用json,需要使用json模块进行解析,也可用正则表达式解析
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
'''重新运行之前请删除content.txt,因为文件操作使用追加方式,会导致内容太多。'''
# 将爬取的内容写入content.txt文件中
# 注意!!!对于显示内容,需要进行单步调试确定当前数据格式,如有必要需要转换
def towrite(contentdict):
f.writelines(u'回帖时间:' + contentdict['topic_reply_time'] + '\n')
f.writelines(u'回帖内容:' + contentdict['topic_reply_content'] + '\n')
f.writelines(u'回帖人:' + contentdict['user_name'] + '\n\n')
# 爬取函数
def spider(url):
html = requests.get(url) # 获取url
selector = etree.HTML(html.text) # 使用etree.HTML转换成XPath可处理的对象
# 使用XPath获取一整个div,即先抓大
content_field = selector.xpath('//div[@class="l_post j_l_post l_post_bright "]')
item = {} # 字典,爬取的内容放入该字典中
for each in content_field:
# 先将述标签复制元素并粘贴到文本中,对于要爬取的data-field数据,将'"'替换为空
# 因为data-field数据是JSON格式,因此需要使用json.loads()将JSON格式解析成字典格式
reply_info = json.loads(each.xpath('@data-field')[0].replace('"',''))
author = reply_info['author']['user_name']
reply_time = reply_info['content']['date']
content = each.xpath('div[@class="d_post_content_main"]/div/cc/div[@class="d_post_content j_d_post_content clearfix"]/text()')[0]
print content
print reply_time
print author
item['user_name'] = author
item['topic_reply_content'] = content
item['topic_reply_time'] = reply_time
towrite(item)
if __name__ == '__main__':
pool = ThreadPool(4)
f = open('content.txt','a')
page = []
for i in range(1,21):
newpage = 'http://tieba.baidu.com/p/3522395718?pn=' + str(i)
page.append(newpage)
results = pool.map(spider, page)
pool.close()
pool.join()
f.close()
6 涉及知识点总结
6.1 多进程的使用
6.1.1 导入进程池Pool
from multiprocessing.dummy import Pool as ThreadPool 6.1.2 实例化Pool
pool=ThreadPool(4) # 4代表共有4个进程进行处理,要根据自己电脑的配置,双核填2,四核填46.1.3 多进程处理
pool.map(函数名, 参数列表)6.1.4 关闭进程池Pool
pool.close(); # 等待进程池中的进程执行完毕再关闭进程池
pool.terminate(); # 直接关闭进程池6.1.5 防止主进程在进程结束前结束
pool.join();6.2 JSON
6.2.1 序列化
序列化:将对象的状态信息转化为可以存储或可以通过网络传输的过程,传输格式可以使JSON、XML等;
反序列化:从存储区域(JSON、XNL)读取反序列化对象的状态,重新创建该对象。
6.2.2 JSON
JSON ( JavaScript Object Notation )是一种轻量级数据交换格式,相对于XNL更简单,也易于阅读和编写,机器也方便解析和生成,
JSON构建于2种结构:
a ”名称/值“对的集合
b 值的有序列表
6.2.3 编码与解码
a 编码Encoding
概念:把一个Python对象编码转换为JSON字符串
方法:json.dumps()
转换规律:
| Python | JSON |
| dictionary | object |
| list, tuple | array |
| string, unicode | string |
| int, long, float | number |
| True | true |
| False | false |
| Node | null |
b 解码Decoding
概念:把JSON格式字符串解码转换为Python对象
方法:json.loads()
转换规律:
| JSON | Python |
| object | dictionary |
| array | list |
| string | unicode |
| number (int) | int, long |
| number (real) | float |
| true/ false | True/ False |
| null | None |
6.2.4 可选参数
dumps方法提供一些可选参数,使输出格式更具有可读性;
a sort_keys参数
含义:使编码器按照字典排序(a到z)输出
举例:
import json
data = [ { 'a':'A', 'b':(2, 4), 'c':3.0 } ]
print 'DATA:', repr(data)
unsorted = json.dumps(data)
print 'JSON:', json.dumps(data)
print 'SORT:', json.dumps(data, sort_keys=True)输出:
DATA: [{'a': 'A', 'c': 3.0, 'b': (2, 4)}]
JSON: [{"a": "A", "c": 3.0, "b": [2, 4]}]
SORT: [{"a": "A", "b": [2, 4], "c": 3.0}]
注意:repr()内置函数是对Python友好,返回参数在Python中的描述。
b indent参数
含义:根据数据格式缩进显示
举例:
import json
data = [ { 'a':'A', 'b':(2, 4), 'c':3.0 } ]
print 'DATA:', repr(data)
print 'NORMAL:', json.dumps(data, sort_keys=True)
print 'INDENT:', json.dumps(data, sort_keys=True, indent=2)输出:
DATA: [{'a': 'A', 'c': 3.0, 'b': (2, 4)}]
NORMAL: [{"a": "A", "b": [2, 4], "c": 3.0}]
INDENT: [
{
"a": "A",
"b": [
2,
4
],
"c": 3.0
}
]
c separators参数
含义:去掉','和':'后面的空格
举例:
import json
data = [ { 'a':'A', 'b':(2, 4), 'c':3.0 } ]
print 'DATA:', repr(data)
print 'repr(data) :', len(repr(data))
print 'dumps(data) :', len(json.dumps(data))
print 'dumps(data, indent=2) :', len(json.dumps(data, indent=2))
print 'dumps(data, separators):', len(json.dumps(data, separators=(',',':')))输出:
DATA: [{'a': 'A', 'c': 3.0, 'b': (2, 4)}]
repr(data) : 35
dumps(data) : 35
dumps(data, indent=2) : 76
dumps(data, separators): 29
6.3 XPath
语法:
import requests
# 从lxml模块中导入etree类
from lxml import etree
url='网站地址'
html=requests.get(url)
# 将获取到的源代码对象html转换成可被XPath识别和匹配的对象
Selector=etree.HTML(html)
# 使用xpath方法进行文本匹配
content=Selector.xpath('参数')
--------------------------------------------
课程总结:
使用Xpath提取网页内容
使用map实现多线程爬虫














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









