







首先我们先找一个html作为实验,可以随便在网上找个网址即可:
前期获取html如下:
import requests
from fake_useragent import UserAgent
from lxml import html
etree = html.etree
url = 'https://www.qidian.com/rank/yuepiao/'
# 定义变量:URL 与 headers
headers = {'User-Agent': str(UserAgent().random)}
#根据访问的网址为https选用“https”,选http用“http”
#proxies = {'协议': '协议://IP:端口号'}
ips= {"https":"https://58.20.232.245:9091"}
ip= {"http":"http://58.20.232.245:9091"}
get = requests.get(url, proxies=ip,headers=headers)
text = get.text
tree = etree.HTML(text)
1.选取所有节点
// 开头的 XPath 规则来选取所有符合要求的节点, * 代表匹配所有节点,也就是整个 HTML 文本中的所有节点都会被获取,可以看到返回形式是一个列表,每个元素是 Element 类型,其后跟了节点的名称,如 html、body、div、ul、li、a 等等,所有的节点都包含在列表中了。
result = tree.xpath('//*')
输出一下result:
可以看到输出的是一个列表。
2.输出文本,使用text()
result = tree.xpath('//*')
for i in result:
t = i.xpath('text()')
print(t)

3.子节点
/ 或 // 即可查找元素的子节点或子孙节点
我想查找div节点下的所以div节点:
result = tree.xpath('//div/div')

4.属性匹配
用 @ 符号进行属性过滤
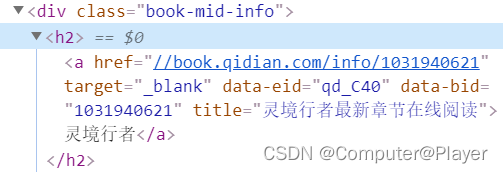
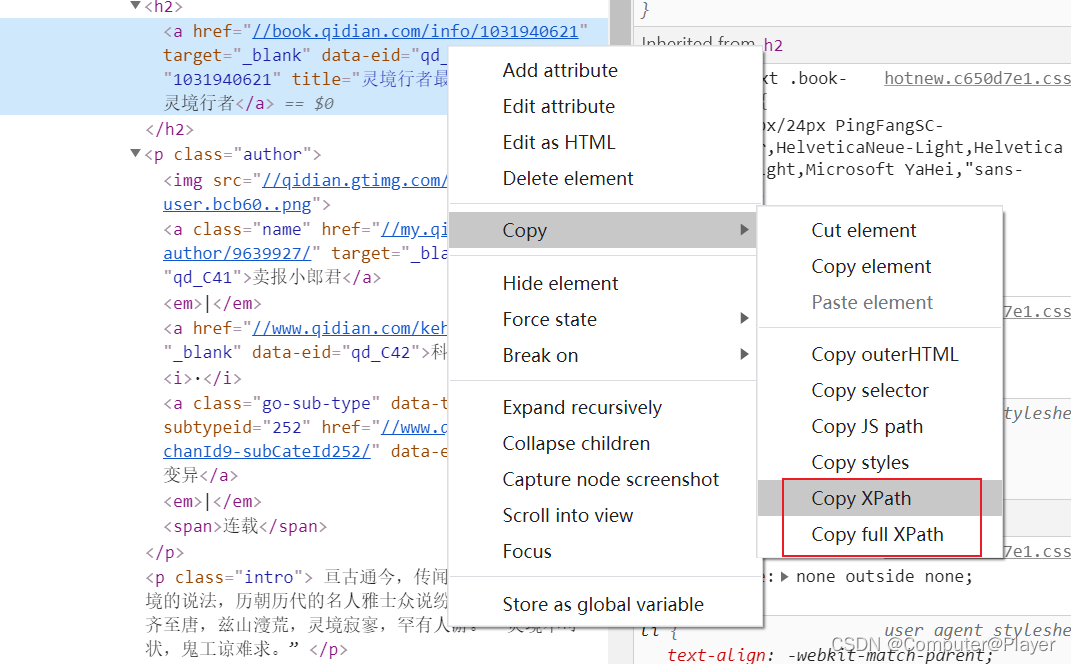
我想获取其中的书名:简单方法就是右键选择
result = tree.xpath('//*[@id="book-img-text"]/ul/li[1]/div[2]/h2/a/text()')
for i in result:
print(i)

5.文本获取和属性获取
文本获取上面已经展示过了,text() 方法可以获取节点中的文本
节点属性该怎样获取呢?其实还是用 @ 符号就可以
例如我想获取下图中的herf

result = tree.xpath('//*[@id="book-img-text"]/ul/li[1]/div[2]/h2/a/@href')
for i in result:
print(i)

属性有多个值就需要用 contains() 函数了
xpath('//div[contains(@class, "book-mid-info")]//text()')
需要根据多个属性才能确定一个节点,这是就需要同时匹配多个属性才可以,那么这里可以使用运算符 and 来连接
6.按序选择
例如
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/a/text()')
print(result)
result = html.xpath('//li[last()]/a/text()')
print(result)
result = html.xpath('//li[position()<3]/a/text()')
print(result)
result = html.xpath('//li[last()-2]/a/text()')
print(result)
第一次选择我们选取了第一个 li 节点,中括号中传入数字1即可,注意这里和代码中不同,序号是以 1 开头的,不是 0 开头的。
第二次选择我们选取了最后一个 li 节点,中括号中传入 last() 即可,返回的便是最后一个 li 节点。
第三次选择我们选取了位置小于 3 的 li 节点,也就是位置序号为 1 和 2 的节点,得到的结果就是前 2 个 li 节点。
第四次选择我们选取了倒数第三个 li 节点,中括号中传入 last()-2即可,因为 last() 是最后一个,所以 last()-2 就是倒数第三个。
7XPath Axes(轴)
XPath 提供了很多节点轴选择方法,英文叫做 XPath Axes,包括获取子元素、兄弟元素、父元素、祖先元素等等,在一定情况下使用它可以方便地完成节点的选择,我们用一个实例来感受一下:
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html"><span>first item</span></a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/ancestor::*')
print(result)
result = html.xpath('//li[1]/ancestor::div')
print(result)
result = html.xpath('//li[1]/attribute::*')
print(result)
result = html.xpath('//li[1]/child::a[@href="link1.html"]')
print(result)
result = html.xpath('//li[1]/descendant::span')
print(result)
result = html.xpath('//li[1]/following::*[2]')
print(result)
result = html.xpath('//li[1]/following-sibling::*')
print(result)
第一次选择我们调用了 ancestor 轴,可以获取所有祖先节点,其后需要跟两个冒号,然后是节点的选择器,这里我们直接使用了 *,表示匹配所有节点,因此返回结果是第一个 li 节点的所有祖先节点,包括 html,body,div,ul。
第二次选择我们又加了限定条件,这次在冒号后面加了 div,这样得到的结果就只有 div 这个祖先节点了。
第三次选择我们调用了 attribute 轴,可以获取所有属性值,其后跟的选择器还是 *,这代表获取节点的所有属性,返回值就是 li 节点的所有属性值。
第四次选择我们调用了 child 轴,可以获取所有直接子节点,在这里我们又加了限定条件选取 href 属性为 link1.html 的 a 节点。
第五次选择我们调用了 descendant 轴,可以获取所有子孙节点,这里我们又加了限定条件获取 span 节点,所以返回的就是只包含 span 节点而没有 a 节点。
第六次选择我们调用了 following 轴,可以获取当前节点之后的所有节点,这里我们虽然使用的是 * 匹配,但又加了索引选择,所以只获取了第二个后续节点。
第七次选择我们调用了 following-sibling 轴,可以获取当前节点之后的所有同级节点,这里我们使用的是 * 匹配,所以获取了所有后续同级节点。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











