









堆排序
堆排序是利用堆的性质进行的一种选择排序。下面先讨论一下堆。
- 堆
堆实际上是一棵完全二叉树,其叶子节点从n/2+1开始。
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
堆分为大顶堆和小顶堆:
满足 Key[i]>=Key[2i]&&key>=key[2i+1]称为大顶堆;
满足 Key[i]<=key[2i]&&Key[i]<=key[2i+1]称为小顶堆。
由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
- 堆排序的思想
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆):
1) 将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无须区;
2) 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
操作过程如下:
1) 初始化堆:将R[1..n]构造为堆;
2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。
因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
下面举例说明:
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到:
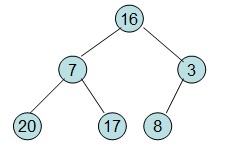
然后需要构造初始堆,则从最后一个非叶节点开始调整,调整过程如下:



20和16交换后导致16不满足堆的性质,因此需重新调整:
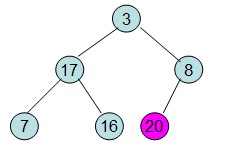

此时3位于堆顶不满堆的性质,则需调整继续调整:









这样整个区间便已经有序了。
从上述过程可知,堆排序其实也是一种选择排序,是一种树形选择排序。只不过直接选择排序中,为了从R[1…n]中选择最大记录,需比较n-1次,然后从R[1…n-2]中选择最大记录需比较n-2次。事实上这n-2次比较中有很多已经在前面的n-1次比较中已经做过,而树形选择排序恰好利用树形的特点保存了部分前面的比较结果,因此可以减少比较次数。对于n个关键字序列,最坏情况下每个节点需比较log2(n)次,因此其最坏情况下时间复杂度为nlogn。堆排序为不稳定排序,不适合记录较少的排序。
下面是堆排序C++实现代码:
/********************************************************
* HeapSort C++ Code *
* DATE:2017年5月30日 *
* Author: Leon *
*=======================================================*
* NOTE:在读取时节点下标 -1 *
*********************************************************/
#include <stdio.h>
#include <iostream>
#include <vector>
#include <time.h>
#include <fstream>
using namespace std;
vector<int> d;
void MAX_HEAPIFY(vector<int> &a,int i,int lenth);//最大堆化,调整使根节点最大
void BUILD_MAXHEAP(vector<int> &a); //建堆
void HEAP_SORT(vector<int> &a); //堆排序
void ReadData(); //从文件读入数组
void PrintVector(const vector<int> &a); //输出数组
void Swap_Node(vector<int> &a, int i, int j); //交换数值
int main()
{
clock_t end;clock_t start = clock();
double TotalTime; //记录运行时间
ReadData(); //cout << d.size() << endl; system("pause");//检查是否读入
HEAP_SORT(d); //堆排序开始~
cout << "Sorted : " << endl;
PrintVector(d); //排序结果输出
end = clock();
TotalTime = (double)(end - start) / CLOCKS_PER_SEC;
cout << "\nTotal Running Time : " << TotalTime << " s \n"; //耗时输出
system("pause");
return 0;
}
void MAX_HEAPIFY(vector<int> &a, int i,int lenth) //最大堆化
{
int left_child = 2 * i; //根节点为i,则左孩子为2i,为了清晰,i从1开始
int right_child = 2 * i + 1; //右孩子为2i+1
int max = i; //记录最大数所在节点
if ((left_child<=lenth)&&(a[i-1] < a[left_child-1]))
{
max = left_child; //不要现在就交换,先记录其下标
}
if ((right_child<=lenth)&&(a[max-1] < a[right_child-1])) //与上次记录的最大值比较
{
max = right_child;
}
if (max != i) //避免多余的交换
{
Swap_Node(a, max-1, i-1);
MAX_HEAPIFY(a, max, lenth);
}
}
void BUILD_MAXHEAP(vector<int> &a)
{
/*对于n个节点,其第n/2+1...第n个节点为叶子节点,
故建堆只需将前n/2个节点为根节点的子堆最大堆化*/
for (int i = a.size()/2; i>0; i--) //i为节点顺序,从1开始,这里最大化对必须从下往上
{
MAX_HEAPIFY(a, i,a.size()); //将所有根节点 最大化
}
}
void HEAP_SORT(vector<int> &a)
{
int lenth = a.size();
BUILD_MAXHEAP(a);
while (lenth>1)
{
Swap_Node(a, 0, lenth-1); //将最大值移到最后
lenth--;
MAX_HEAPIFY(a, 1, lenth);
}
}
void ReadData()
{
fstream InFile("data.txt");
int num = 0;
while (!InFile.eof())
{
InFile >> num;
d.push_back(num);
}
}
void PrintVector(const vector<int> &a)
{
for (auto iter = a.begin(); iter != a.end(); iter++)
{
cout << *iter << "\t"; // "\t"很好用,有对齐效果
}
}
void Swap_Node(vector<int> &a, int i, int j)
{
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}














 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









