







 本文介绍了如何在3台机器上搭建Spark on Yarn集群,包括配置hosts、安装Java、Scala、Hadoop和Spark,以及启动和验证集群的过程。详细步骤包括设置SSH免密码登录、安装Java 1.8、Scala 2.10.6,配置Hadoop 2.7.2,启动Hadoop和Spark,并通过SparkPi示例验证安装成功。
本文介绍了如何在3台机器上搭建Spark on Yarn集群,包括配置hosts、安装Java、Scala、Hadoop和Spark,以及启动和验证集群的过程。详细步骤包括设置SSH免密码登录、安装Java 1.8、Scala 2.10.6,配置Hadoop 2.7.2,启动Hadoop和Spark,并通过SparkPi示例验证安装成功。
由于最近学习大数据开发,spark作为分布式内存计算框架,当前十分火热,因此作为首选学习技术之一。Spark官方提供了三种集群部署方案: Standalone, Mesos, Yarn。其中 Standalone 为spark本身提供的集群模式,搭建过程可以参考官网,本文介绍Spark on Yarn集群部署过程。使用3台普通机器搭建Spark集群,
软件环境:
Ubuntu 16.04 LTS
Ubuntu 16.04 LTS
CentOS7
Scala-2.10.6
Hadoop-2.7.2
spark-1.6.1-bin-hadoop2.6
Java-1.8.0_77
硬件环境:
一个Master节点
Intel® Core™ i5-2310 CPU @ 2.90GHz × 4
4G内存
300G硬盘
两个Slave节点
Intel® Core™ i3-2100 CPU @ 3.10GHz × 4
4G内存
500G硬盘
一、配置/etc/hosts及免密码登录
本文下载安装的软件都放在 home 目录下。
1. 主机hosts文件配置
在每台主机上修改host文件
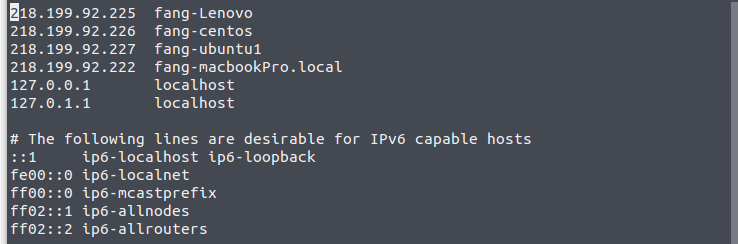
sudo vim /etc/hosts
218.199.92.227 fang-ubuntu1(Master)
218.199.92.226 fang-centos(Slave)
218.199.92.225 fang-Lenovo(Slave)
127.0.0.1 localhost
127.0.1.1 localhost
注:若此地未配置,或者未配置正确会导致集群启动不正常或者失败(nodemanager did not stop gracefully after 5 seconds )
配置之后ping一下各机器名称检查是否生效,例如ssh fang@fang-centos。
2. 配置SSH 免密码登录
如果没有安装ssh,需要安装Openssh server,命令为sudo apt-get install openssh-server。
1) 在所有机器上都生成私钥和公钥
ssh-keygen -t rsa #一路回车
2) 需要让机器间都能相互访问,就把每个机子上的id_rsa.pub发给master节点,传输公钥可以用scp来传输。
scp ~/.ssh/id_rsa.pub fang@fang-ubuntu1:~/.ssh/id_rsa.pub.slave1
3) 在master
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









