






概述
随着业务数据的不断积累,传统的关系数据库面临大量数据的挑战,此时将数据导入廉价且安全性较高的NOSQL数据库中显得越有必要。面临类似的业务场景工程师们自然会通过编程来实现数据的导入导出,这样提供一个通用的比较完善的工具有显得有必要了,Apache Sqoop即是
场景举例
近期有这样一个业务:由于业务升级,需要将存储在Oracle中的大概14亿的两张表的数据导入到Elasticsearch 中进行索引,面临以下问题:
1. 由于历史原因数据不能直接被导入到ES,因为中间要进行多个字典项的翻译
2. 新系统即将面临新数据的写入,在此之前需要完成Oracle中历史数据的同步避免对实时数据的影响
鉴于以上原因,数据同步服务必须在可编程的基础上进行并行处理[实际上如果不需要字典值的翻译,现有直接支持Oracle导入ES的工具],综合给出以下方案:将Oracke表中的数据同步到HDFS中,使用Spark编程并行处理数据写入Elasticsearch,这期间Sqoop可以帮助完成Oracle到HDFS的操作,省去较为复杂的编程环节。
实际上遇到的问题不止如此,两表的数据最终需要按外键关系索引为ES的一个文档,意味着上述方案可能存在一定欠缺,关联关系如何来确定?于此同时将面临新的问题:
1. Oralce表中几乎没有能力使用连接查询,不是一般的慢
2. 如果采用第一种方案,将面临对14亿数据同时做一个连接操作,需要的内存现有环境几乎无法满足,又不愿意付出其它额外的代价[还有其它方案]
综合下来决定牺牲一定的性能给出以下方案:使用SparkSQL批量的从Oracle中使用外键来抓取一批数据,在Spark中进行连接操作,最后执行索引操作。但这建立在一个前提,外键是被索引的,否则这将是一场灾难。
虽然最终没有使用Sqoop.肯定会有用的
集群环境
ZK:host101,host102,host103
Hadoop:host102[主],host103[备],host104,host105,host106
Sqoop2:host105
主意事项:Sqoop先有两个版本分支,这里以Sqoop2为例
Sqoop2安装
1. 下载Sqoop2
http://mirror.bit.edu.cn/apache/sqoop/1.99.7/sqoop-1.99.7-bin-hadoop200.tar.gz 得到文件sqoop-1.99.7-bin-hadoop200.tar.gz 压缩文件
2. host150节点中安装Sqoop2 Server,server 需要部署在Hadoop节点上以便于想Yarn提交MR任务。 解压到 /app/路径下
3. 检查server节点上Hadoop环境变量,确保HADOOP_HOME被正确配置

4. 修改Sqoop配置文件
a) conf/sqoop.properties 定位Hadoop配置文件的路径,其它默认即可
org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/app/hadoop-2.7.3/etc/hadoop
5. 修改YARN配置文件
a) container-executor.cfg,配置允许提交应用的系统用户,下述允许sqoop2,root用户向YARN提交应用。
allowed.system.users=sqoop2,root
b) Sqoop2应用默认请求调度的内存为1536M需要确保YARN的最大允许请求内存大于此值
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2000</value>
</property>c) core-site.xml,配置代理用户,应该一个就够用了吧,这里配了两
<property>
<name>hadoop.proxyuser.sqoop2.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.sqoop2.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>6. 加入JDBC驱动包, 在server节点自定义目录将JDBC驱动包导入,将JDBC目录加入环境变量,这里将Oracle驱动包放在Server节点/app/dblib目录下
exportSQOOP_SERVER_EXTRA_LIB=/app/dblib
7. 启动Sqoop2 server
Sqoop安装目录下执行 bin/sqoop2-server start ,jps检查SqoopJettyServer进程启动成功即可。
Sqoop使用示例
Sqoop2支持配置预先配置数据源、作业等,可以在Shell 环境中便捷的完成支持的数据传输操作。
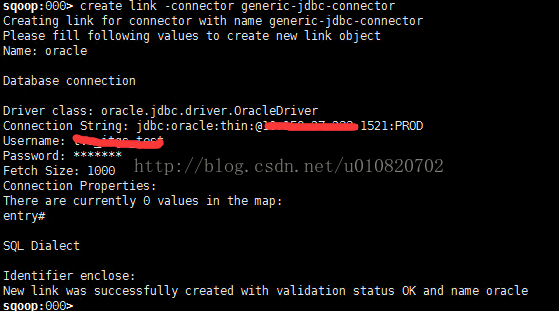
1. 创建Oracle数据源
a) 进入Sqoop2 shell环境
b) createlink -connector generic-jdbc-connector ,按提示执行,成功即可
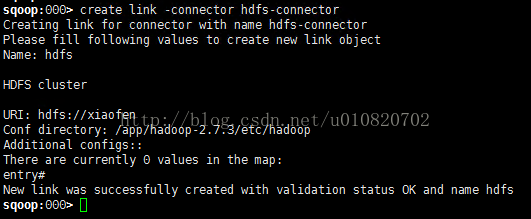
2. 创建HDFS数据源
a) shell中执行create link -connector hdfs-connector,按提示操作
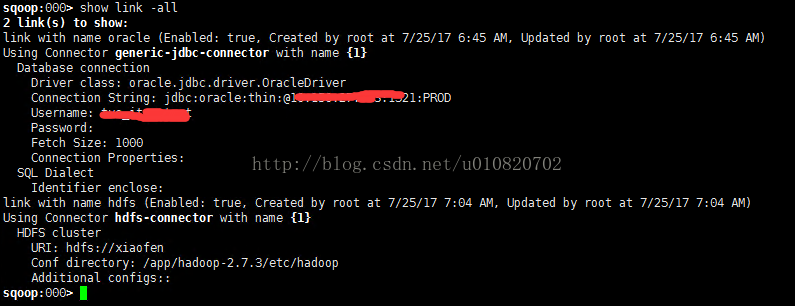
3. 查看已经创建的连接[数据源]
a) shell下执行 show link -all
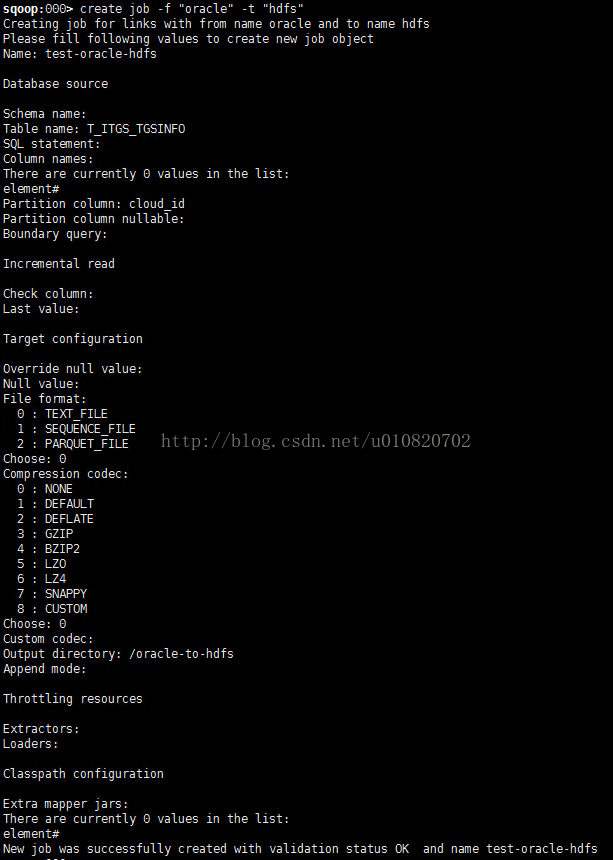
4. 定义Job,指定从Oracle导入数据到HDFS
a) shell中执行 create job -f "oracle" -t"hdfs",f指from t指to,按提示操作
5. 显示已经创建好的Job
a) 执行 show job -all
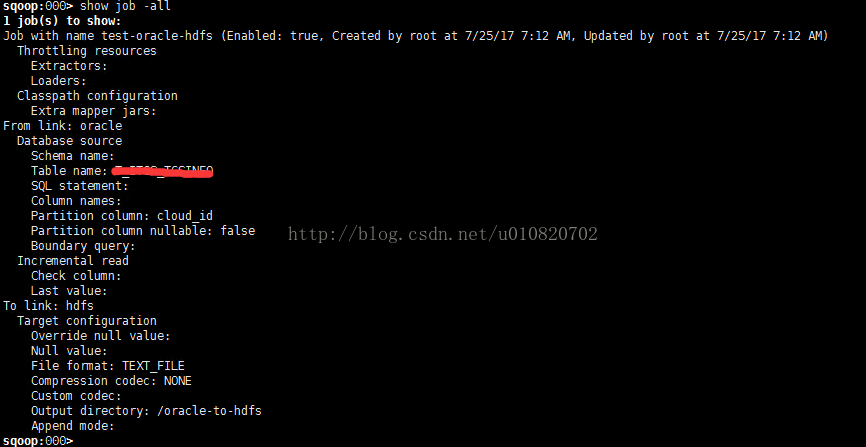
6. 执行Job
a) startjob -n test-oracle-hdfs 很遗憾报错了,见下

b) 看日志文件,bin目录下@LOGDIR@,有时候会直接在安装路径下的@LOGDIR@目录中,查看sqoop.log,找到错误时执行的SQL,见下,明显SQL中的标识符不应该是双引号,需要纠正Oracle的数据源定义.

c) 修改定义的数据源,纠正标识符,执行 update link -n oracle ,纠正Identifier enclose 不能忽略输入一个空格回车即可.
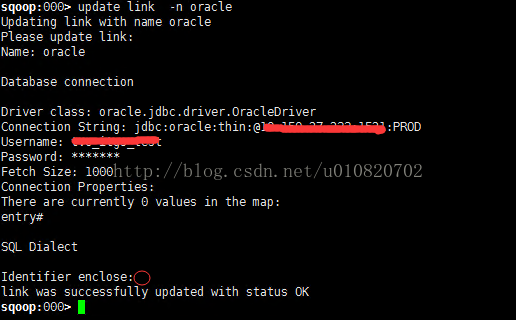
d) 重新启动Job,同上
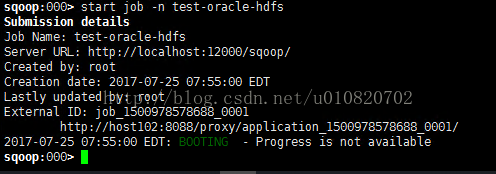
e)
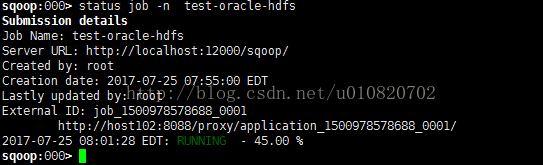
7. 查看Job执行进度
a) statusjob -n test-oracle-hdfs
8. Hadoop中确认作业
a) Yarn中确认已经被提交的应用
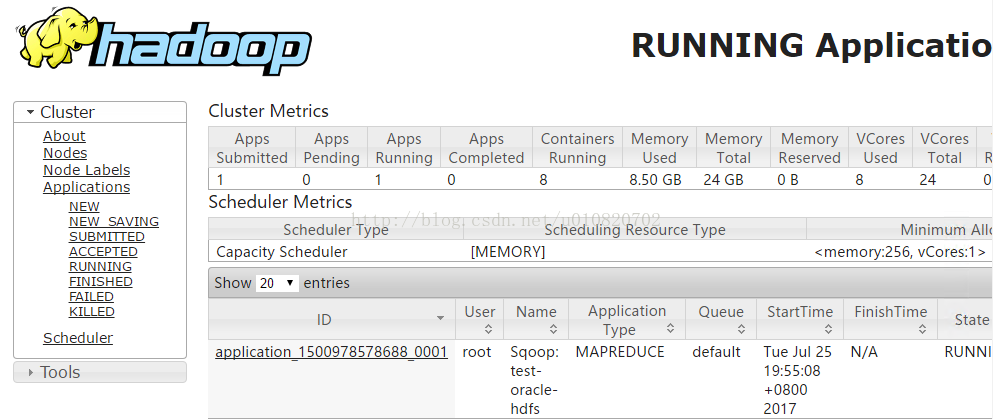
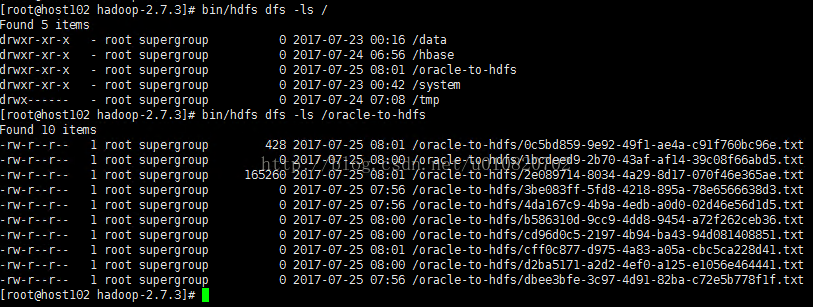
b) HDFS中确认被导入的数,Hadoop节点下,安装目录下执行bin/hdfs dfs -ls /














 2544
2544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









