







 本文详细介绍了Apache Sqoop在实际操作中的应用,包括从MySQL、Phoenix到Hive的数据导入,以及 Sqoop 的工作原理。通过具体的实例展示了如何使用Sqoop创建表、导入数据,并解释了各种参数的用途。
本文详细介绍了Apache Sqoop在实际操作中的应用,包括从MySQL、Phoenix到Hive的数据导入,以及 Sqoop 的工作原理。通过具体的实例展示了如何使用Sqoop创建表、导入数据,并解释了各种参数的用途。
摘要:本文主要讲了笔者在使用sqoop过程中的一些实例
一、概述与基本原理
Apache Sqoop(SQL-to-Hadoop) 项目旨在协助 RDBMS 与 Hadoop 之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。因此,可以说Sqoop就是一个桥梁,连接了关系型数据库与Hadoop。qoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。Sqoop的基本工作流程如下图所示:
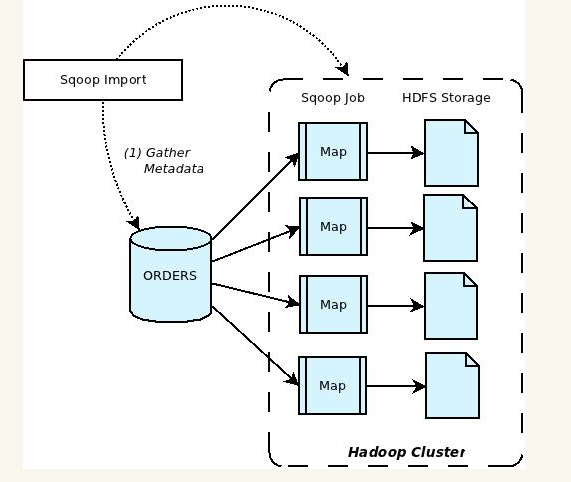
从关系数据库到Hive/hbase
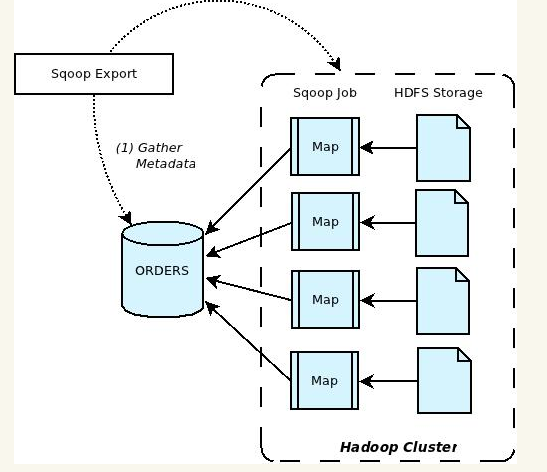
从Hive/hbase到关系数据库
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中(由此也可知,导入导出的事务是以Mapper任务为单位)。同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。 比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
二、使用实例
接下来将以实例来说明如何使用<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









