







上一篇:
Storm和Zookeeper集群搭建及在java项目中的使用:
http://blog.csdn.net/xlgen157387/article/details/77540057
一、Storm架构简介
在上一篇,我们对Storm集群进行了搭建,并使用Java完成了代码的演示,我们知道在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。这个拓扑将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。
一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。由spout发射出的tuple是不可变数组,对应着固定的键值对。
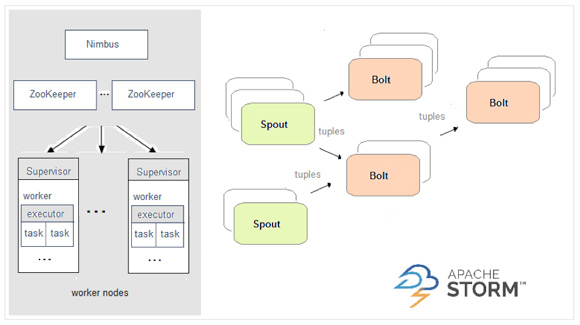
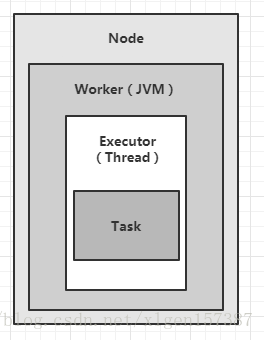
在Storm中,一个task可以简单的理解为在集群某节点上运行的一个spout或者bolt实例。在集群运行运行中,topology主要有四个组成部分:他们从低到高分别是:task(bolt/spout实例)、Executor(线程)、Workers(JVM虚拟机)、Nodes(服务器)
各个部分的含义如下:
(1)Nodes(服务器):是指配置在一个Storm集群中的服务器,会执行topology的一部分运算。一个Storm集群可以包括一个或者多个工作node。
(2)Workers(JVM虚拟机):是指一个node节点服务器上相互独立运行的JVM进程。每一个node可以配置运行一个或者多个worker。一个topology会分配到一个或者多个worker上运行。
(3)Executor(线程):是指一个worker的JVM进程中运行的Java线程。多个task可以指派给同一个executor来执行。除非是明确指定,Storm默认会给每一个executor分配一个task。
(4)Task(bolt/spout实例):task是spout和bolt的实例,衙门的nextTuple()和execute()方法会被executors线程调用执行。
结构图如下:
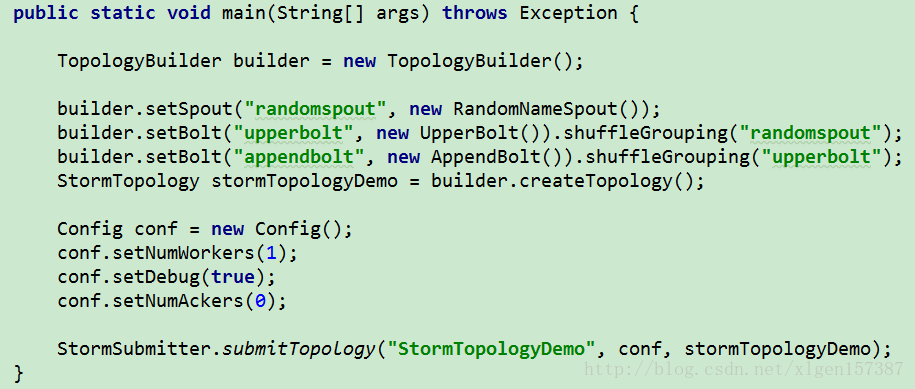
二、Topology的并发机制–默认配置
以上一篇的代码为例,Topology的代码(代码A)如下:
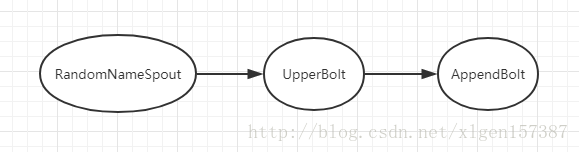
可以看到Topology中有RandomNameSpout和两个Bolt:UpperBolt、AppendBolt,执行流程如下:
上边的代码在默认的情况下,我们没有使用Storm中并发机制提供的API,全部都是默认的,在大多数情况下,除非明确指定,Storm的默认并发设置是1。
在这里,我们假设有一台服务器(Node节点),为topology分配了一个worker,并且每个executor执行一个task,那么上述代码(代码A)的执行流程如下图(图A)所示:
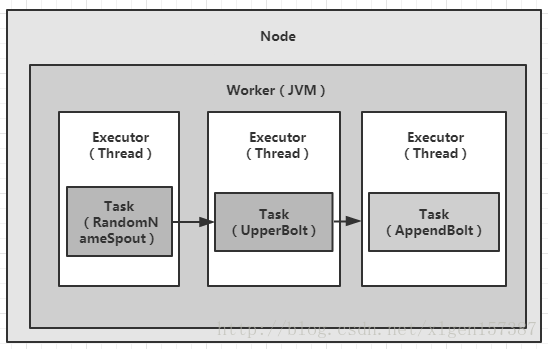
由上图,我们可以看出,唯一的并发机制出现在线程级。每个任务Task在同一个JVM的不同线程中执行。
三、Topology的并发机制–给Topology增加Worker
增加额外的worker是增加topology计算能力的简单方式,Storm提供了简单的配置使我们增加worker的方式变得很容易,只需修改如下代码即可,其它代码不变:
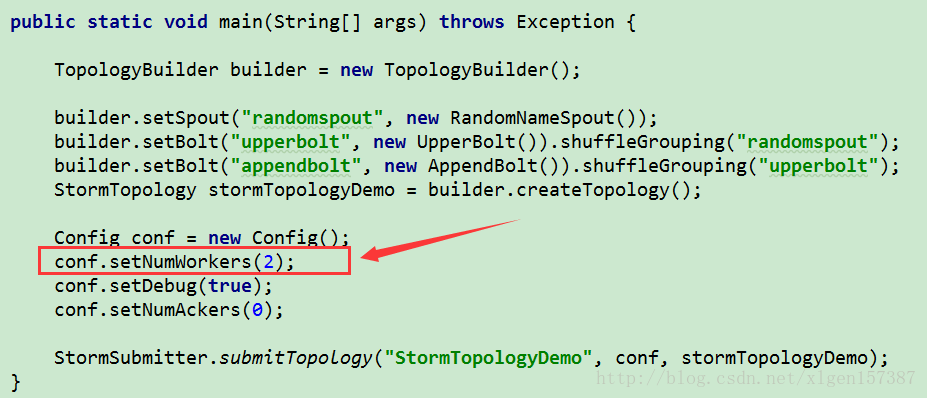
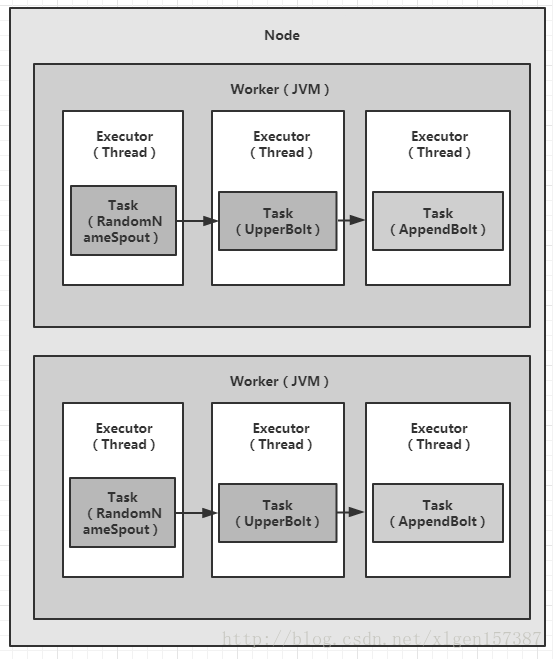
这样的话,整个topology就分配了2个worker而不是默认的1个。那么上图图A应该变成如下方式,如图(图B):
四、Topology的并发机制–配置executor和task(1)
Storm并发机制API允许设定每个task对应的executor个数和每个executor可执行的task个数。在定义流分组的时候,也可以设置每一个组件指派的executor的数量。例如:我们修改RandomNameSpout并发为两个task,每个task指派各自的executor线程,还是只使用1个worker代码修改如下:
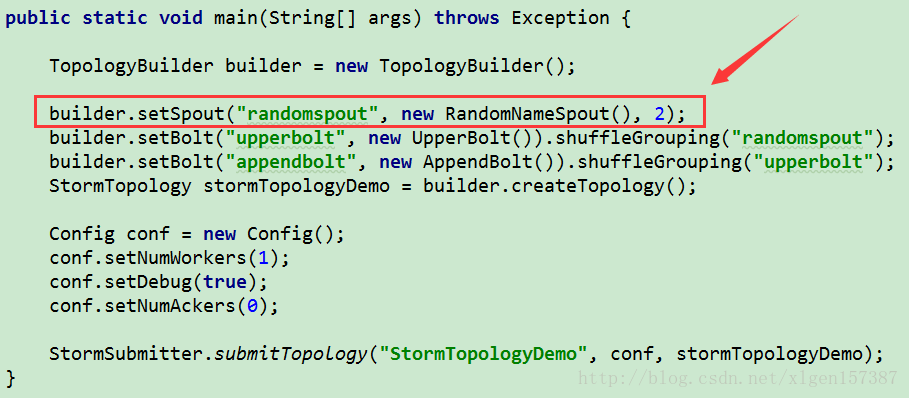
注意官方API对于setSpout()方法的定义是这样的:
/**
* Define a new spout in this topology with the specified parallelism. If the spout declares
* itself as non-distributed, the parallelism_hint will be ignored and only one task
* will be allocated to this component.
*
* @param id the id of this component. This id is referenced by other components that want to consume this spout's outputs.
* @param parallelism_hint the number of tasks that should be assigned to execute this spout. Each task will run on a thread in a process somewhere around the cluster.
* @param spout the spout
* @throws IllegalArgumentException if {@code parallelism_hint} is not positive
*/
public SpoutDeclarer setSpout(String id, IRichSpout spout, Number parallelism_hint) throws IllegalArgumentException {
validateUnusedId(id);
initCommon(id, spout, parallelism_hint);
_spouts.put(id, spout);
return new SpoutGetter(id);
}
对于第三个参数,意思是:设置Spout的并发为两个task,每个task指派给各自的executor线程,由于默认情况下,每一个线程executor执行一个task,所以我们可以理解为,分配了两个线程executor,每一个executor线程执行一个任务task。
那么上图图A应该变成如下方式,如图(图C):
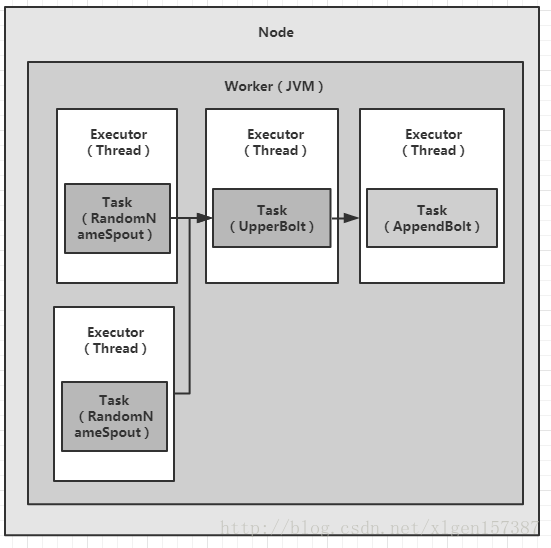
五、Topology的并发机制–配置executor和task(2)
上述,增加了Spout的线程数,在默认情况下每一个线程executor是处理一个task,那么,我们接下来设置多个executor和多个task,完整代码如下:
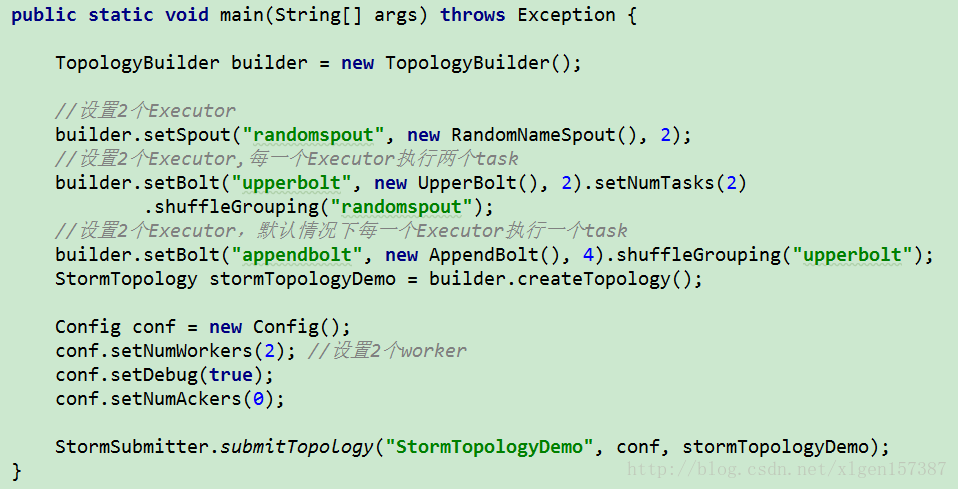
那么上图图A应该变成如下方式,如图(图D):
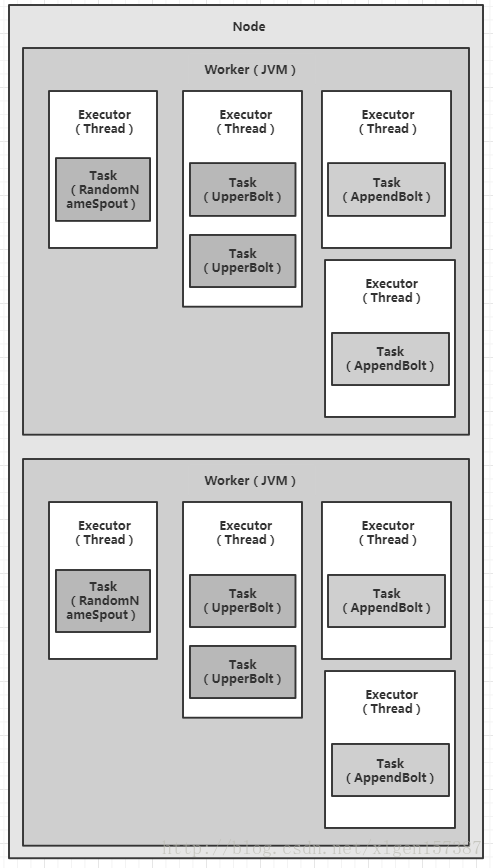
有上述代码,可知设置了2个worker,因此每一个worker平均分摊执行相应的task,最后的结果就如上图所示。
值得注意的是:如果只在一台Node服务器上增加worker的数量,例如:topology执行在本地模式的时候,并不会显著地提升系统的性能,也是会出现瓶颈的,这是因为topology在本地模式下是在同一个JVM进程中执行的,必然会有相关资源的竞争等,所以只有增加task和executor的并发配置才会生效。
六、Topology的并发机制的特殊情况
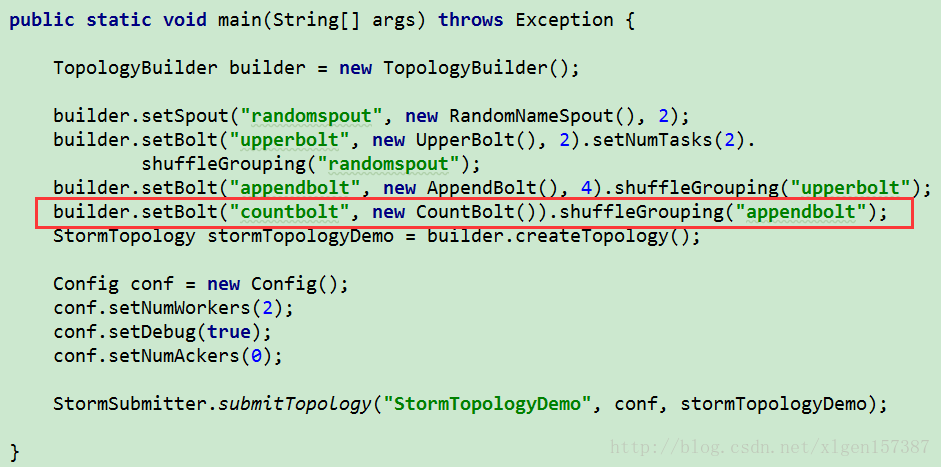
实际开发中可能存在这种情况,例如:我们在上述的基础上在增加一个类似于汇总的Bolt进行统计字符串的多少,那我,我们只可能对这个Bolt设置为单线程、单任务的方式进行统计,而不可能在使用多线程或多任务的方式进行统计,原因很简单,执行示意图如下:
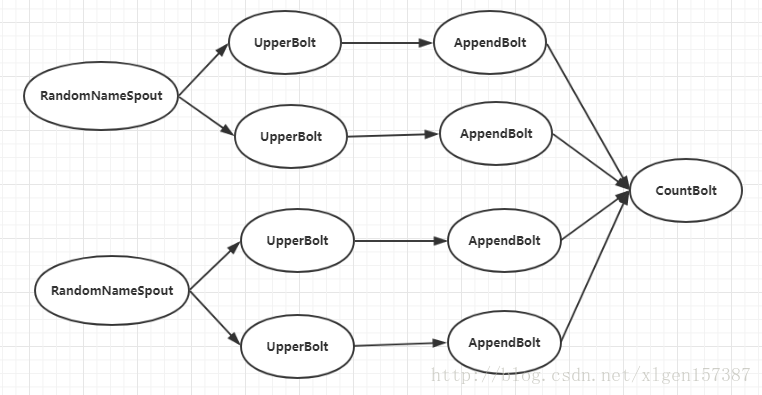
代码如下:
那么上图图A应该变成如下方式,如图(图E):
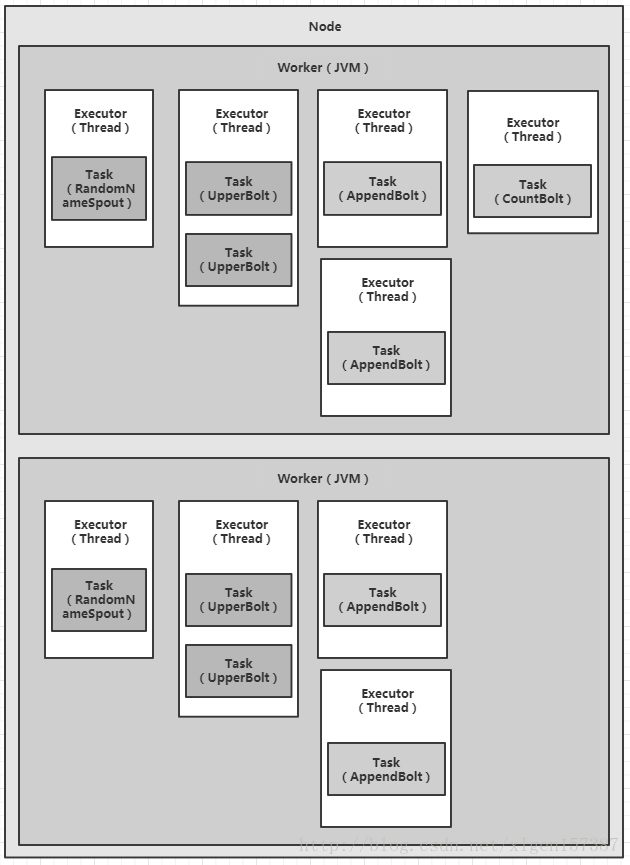
由此,我们可以知道,Storm提供了简单的API接口让我们能够很方便的进行并发控制,但是我们也要根据具体的业务设置合理的executor和task等数目,以免发生错误的结果。
参考文章:















 9384
9384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











