







上一篇:
介绍了分布式Zookeeper集群的搭建和Kafka集群的搭建,接下来学习一下Storm集群的搭建。
实验环境
- Cent OS 6.9
- apache-storm-1.1.0
- 三台服务器虚拟机:192.168.1.129、192.168.1.214、192.168.1.241
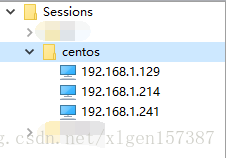
准备工作
1、修改服务器hostname和hosts文件使得可以直接通过hostname访问
使用hostname name修改hostname,例如:
#hostname xuliugen129(或者直接修改/etc/hostname文件,输入要设置的hostname)
将三台服务器分别修改为:xuliugen129、xuliugen214、xuliugen241。
2、然后,修改/etc/hosts使之在内网环境下可以ping 通:
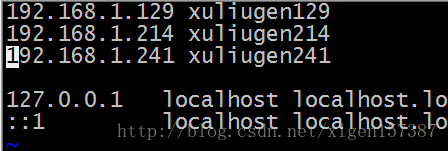
每台机子都设置为上边的hostname,只需要添加上边的三行即可。
3、关闭3台服务器的防火墙:
service firewalld stop关于Cent OS防火墙的使用可以参考:CentOS 7中firewall防火墙详解和配置以及切换为iptables防火墙
Zookeeper安装与配置
在上一篇中介绍了Zookeeper集群的安装方式,这里不再介绍,请查看:Kafka 单机和分布式环境搭建与案例使用
Storm安装与配置
1、选择合适的版本进行下载Storm
下载地址:http://storm.apache.org/downloads.html
这里选择的是apache-storm-1.1.0.tar.gz ,点击进去选择合适的镜像地址进行下载,我这里的下载地址为:http://mirrors.tuna.tsinghua.edu.cn/apache/storm/apache-storm-1.1.0/apache-storm-1.1.0.tar.gz
使用wget进行下载:
>wget http://mirrors.tuna.tsinghua.edu.cn/apache/storm/apache-storm-1.1.0/apache-storm-1.1.0.tar.gz
分别下载到3台服务器上,然后解压到自己合适的位置,我这里都是:/home/xuliugen/server
2、配置Storm
配置文件在:/home/xuliugen/server/apache-storm-1.1.0/conf 目录下的storm.yaml
默认只需要修改如下部分:
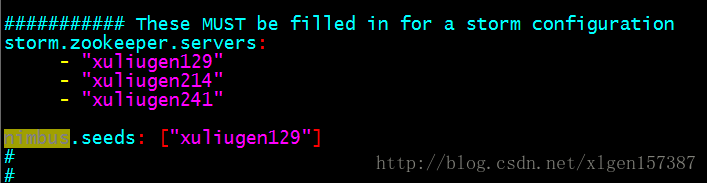
3台服务器的Storm进行上述相同的配置即可。
Storm启动与应用
1、Storm命令
启动命令在:/home/xuliugen/server/apache-storm-1.1.0/bin 文件夹下,
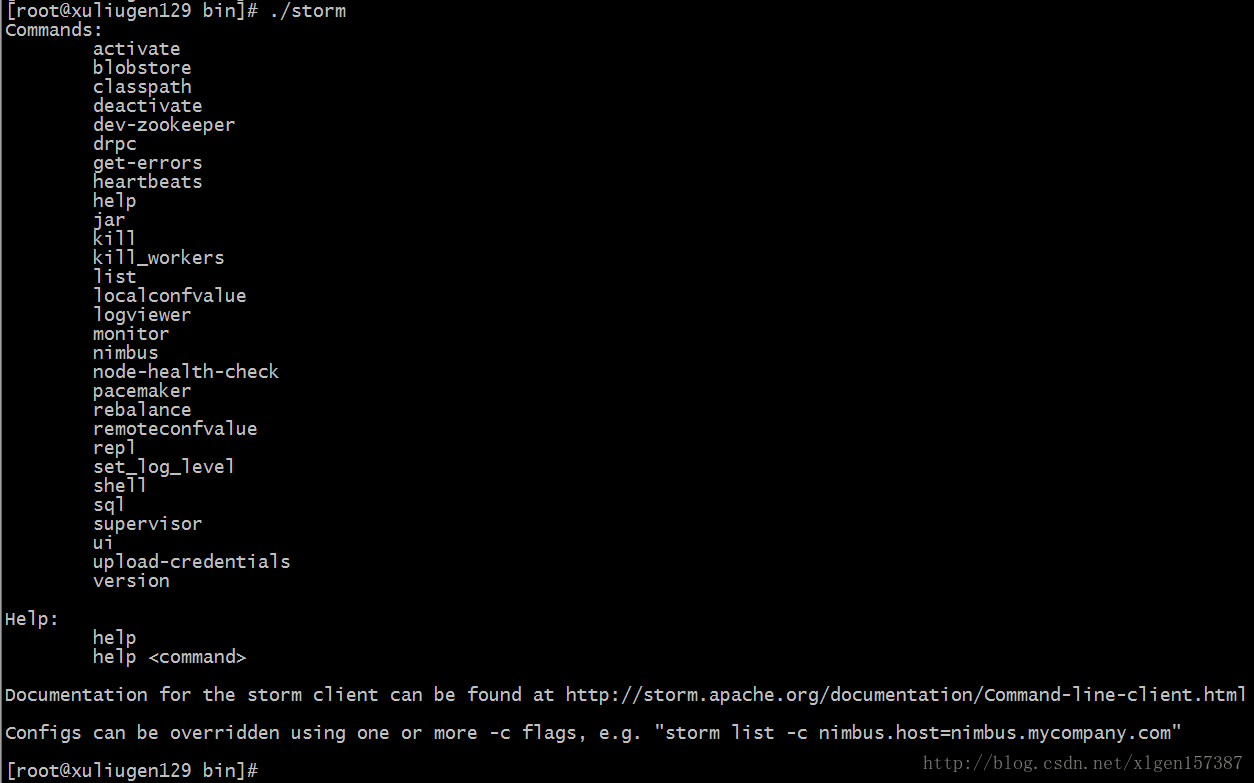
以上列出了所有可以执行的命令模式。
2、启动nimbus
nimbus主机为:xuliugen129

另外开启一个控制界面,使用jps查看是否正常启动:
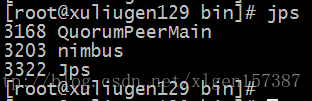
nimbus表示正常启动。
3、启动Storm UI
Storm UI这可以在启动nimbus的机器上运行,这里是:xuliugen129,启动如下:
启动之后,jps如下:
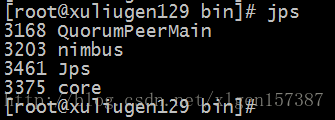
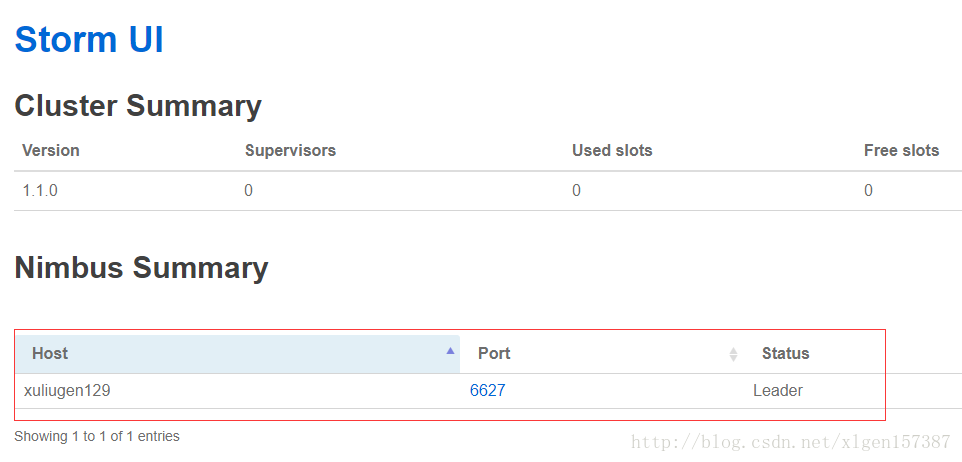
Storm UI 进程为core,访问xuliugen129:8080(这里我的PC级访问的话,就不再是上述设置的hostname,应该是对应的内网IP,默认端口为8080)
3、启动另外两台supervisor
主机分别为:xuliugen214、xuliugen241
>./storm supervisor
查看Storm UI如下:
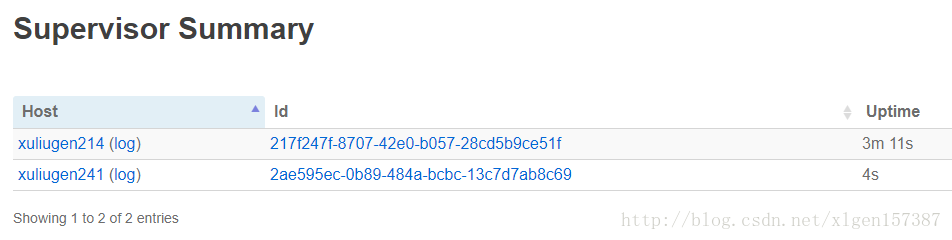
4、最后查看任一台Zookeeper服务器,查看节点情况:


项目代码使用
CSDN代码地址:http://download.csdn.net/download/u010870518/9949050
百度云盘地址: 链接:http://pan.baidu.com/s/1qYoJ6I4 密码:zsni
1、项目结构
核心jar为:storm-core-1.1.0.jar
2、执行原理:
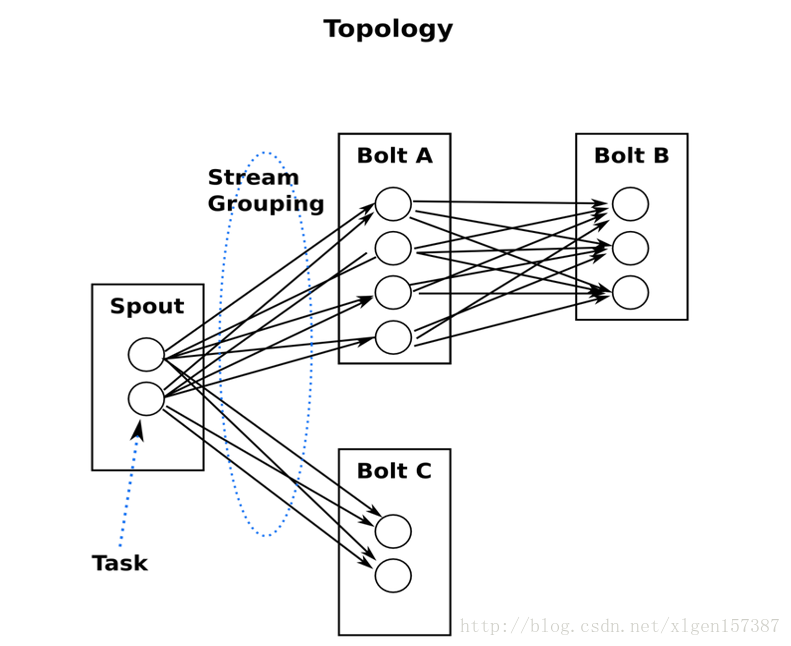
一个Topology是Spouts和Bolts组成的图, 通过Stream Groupings将图中的Spouts和Bolts连接起来,如下图:
3、Spout代码
public class RandomNameSpout extends BaseRichSpout {
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
// 模拟一些数据
String[] names = { "zhangsan", "lisi", "wangwu", "zhaoliu", "sunqi", "wangba" };
/**
* 不断地往下一个组件发送tuple消息 这里面是该spout组件的核心逻辑
*/
@Override
public void nextTuple() {
Random random = new Random();
int index = random.nextInt(names.length);
// 通过随机数拿到一个姓名
String lowerName = names[index];
// 将姓名封装成tuple,发送消息给下一个组件
collector.emit(new Values(lowerName));
// 每发送一个消息,休眠500ms
Utils.sleep(500);
}
/**
* 初始化方法,在spout组件实例化时调用一次c
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/**
* 声明本spout组件发送出去的tuple中的数据的字段名
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("lowerName"));
}
}
3、UpperBolt代码
public class UpperBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector;
@Override
public void execute(Tuple tuple) {
// 先获取到上一个组件传递过来的数据,数据在tuple里面
String lowerName = tuple.getString(0);
// 将姓名转换成大写
String upperName = lowerName.toUpperCase();
// 将转换完成的商品名发送出去
collector.emit(new Values(upperName));
}
@Override
public void prepare(Map conf, TopologyContext topologyContext, OutputCollector collector) {
this.collector = collector;
}
/**
* 声明该bolt组件要发出去的tuple的字段
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("upperName"));
}
}
4、AppendBolt代码
public class AppendBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
FileWriter fileWriter = null;
@Override
public void execute(Tuple tuple) {
// 先拿到上一个组件发送过来的姓名
String upperName = tuple.getString(0);
String suffix_name = upperName + "_csdn";
try {
fileWriter.write(suffix_name);
fileWriter.write("\n");
fileWriter.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 在bolt组件运行过程中只会被调用一次
*/
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
try {
fileWriter = new FileWriter("/home/xuliugen/server/stormdata/" + UUID.randomUUID());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 本bolt已经不需要发送tuple消息到下一个组件,所以不需要再声明tuple的字段
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
}5、TopologyMain代码
public class TopologyMain {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
// 将我们的spout组件设置到topology中去
// parallelism_hint :4 表示用4个excutor来执行这个组件
// setNumTasks(8) 设置的是该组件执行时的并发task数量,也就意味着1个excutor会运行2个task
builder.setSpout("randomspout", new RandomNameSpout(), 4).setNumTasks(8);
// 将大写转换bolt组件设置到topology,并且指定它接收randomspout组件的消息
// .shuffleGrouping("randomspout")包含两层含义:
// 1、upperbolt组件接收的tuple消息一定来自于randomspout组件
// 2、randomspout组件和upperbolt组件的大量并发
// task实例之间收发消息时采用的分组策略是随机分组shuffleGrouping
builder.setBolt("upperbolt", new UpperBolt(), 4).shuffleGrouping("randomspout");
// 将添加后缀的bolt组件设置到topology,并且指定它接收upperbolt组件的消息
builder.setBolt("suffixbolt", new AppendBolt(), 4).shuffleGrouping("upperbolt");
// 用builder来创建一个topology
StormTopology stormTopologyDemo = builder.createTopology();
// 配置一些topology在集群中运行时的参数
Config conf = new Config();
// 这里设置的是整个StormTopologyDemo所占用的槽位数,也就是worker的数量
conf.setNumWorkers(4);
conf.setDebug(true);
conf.setNumAckers(0);
// 将这个topology提交给storm集群运行
StormSubmitter.submitTopology("StormTopologyDemo", conf, stormTopologyDemo);
}
}6、提交到Storm集群运行:
1、将项目导出jar,步骤如下:
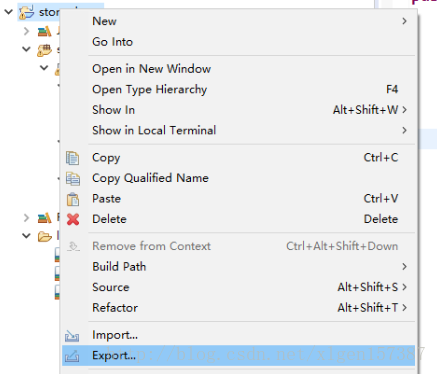
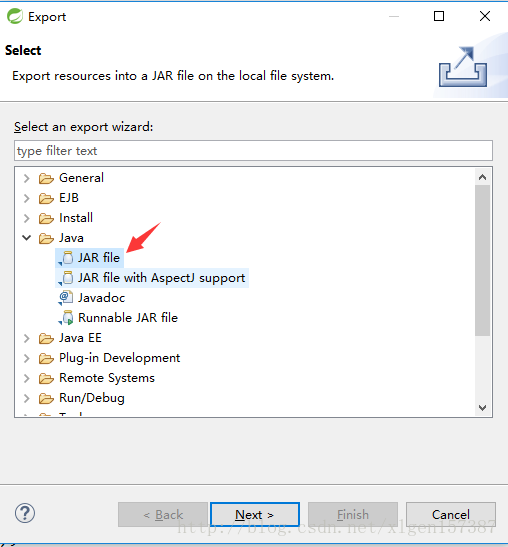
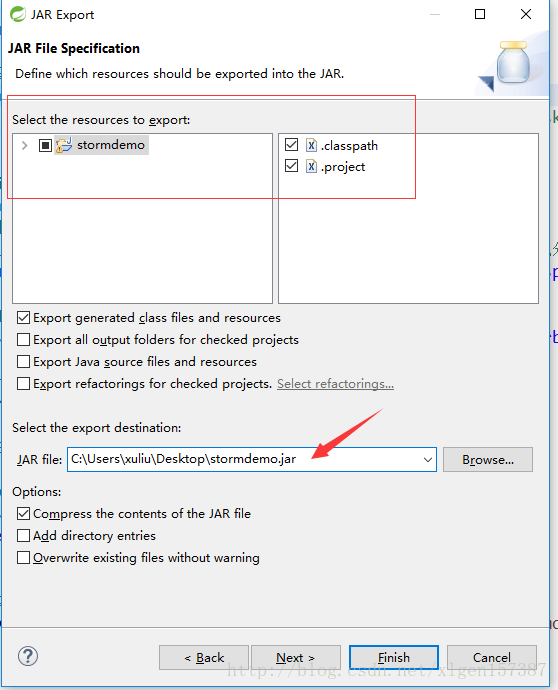
2、如果有警告的话,直接忽略即可。
3、将导出的jar上传到服务器上,nimbus主机即可,我这里上传到:/home/xuliugen/temp 目录下,
4、在2台supervisor主机上创建项目中需要的目录:
/home/xuliugen/server/stormdata/5、提交到Storm集群的命令为:
>./storm jar /home/xuliugen/temp/stormdemo.jar com.xuliugen.demo.topology.TopologyMain(1)/home/xuliugen/temp/stormdemo.jar为打包的jar在服务器上的位置;
(2)com.xuliugen.demo.topology.TopologyMain位主函数全路径;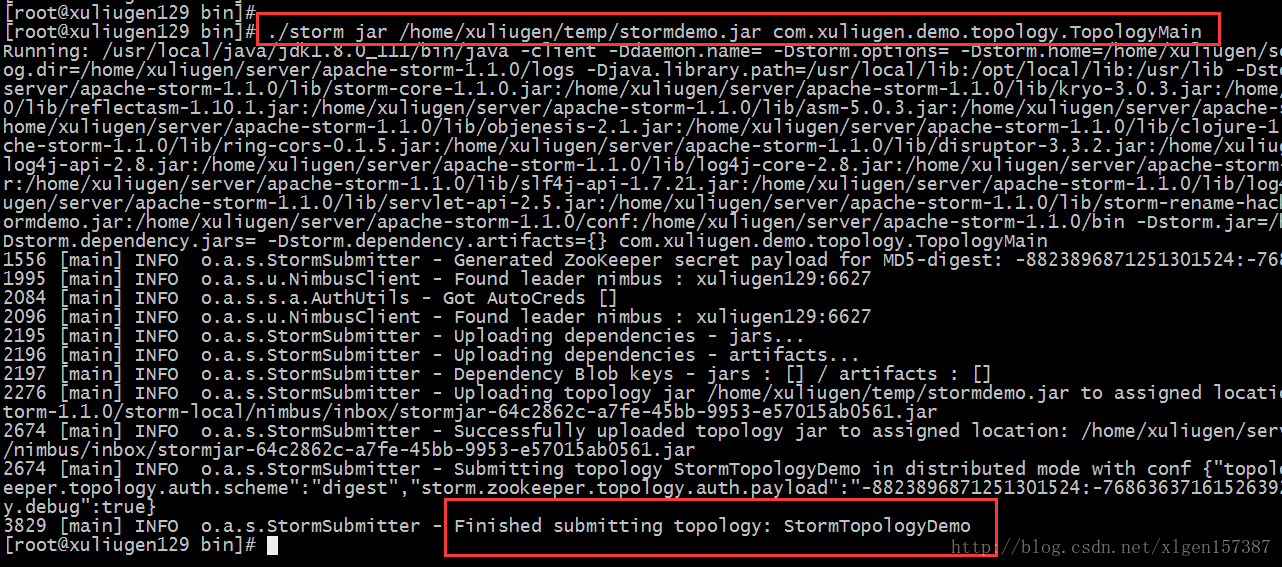
6、最后查看Storm UI可以看到:
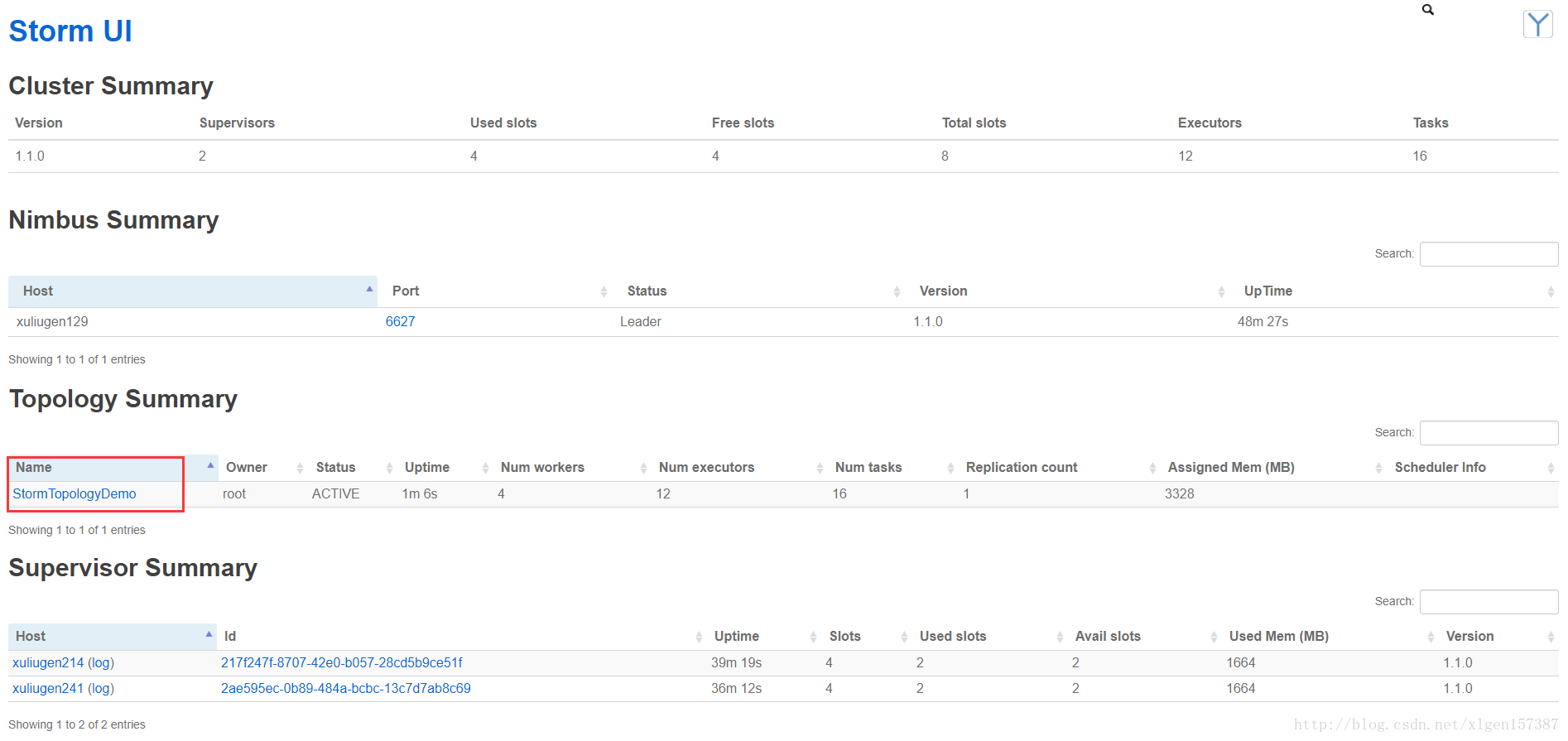
7、运行效果
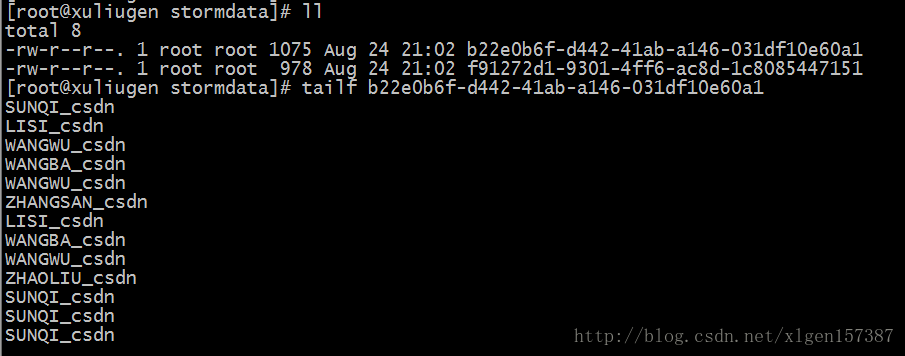
















 2463
2463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











