







Java8的另一大新特性就是引入了Stream流操作,并且升级了集合类的接口,使得程序员可以在更高的层面对集合做一些抽象操作,之前有一篇文章讲过函数式编程的思想,而Stream就是用函数式编程在集合上进行复杂操作的工具。
这篇文章将从以下三点带大家认识Stream
一.Stream的基本用法
二.其他转换Stream的方法
三.功能强大的汇聚操作
一.Stream的基本用法
先看一个简单的例子:
List<Student> students;//省略掉students的构造方法
List<String> nameList = students.stream()
.filter(e -> e.getMathScore() >= 60)
.map(e -> e.getName())
.collect(Collectors.toList());麻雀虽小,五脏俱全,上面这行代码可以简单概括Stream的用法,包括Stream的生成、filter操作、map操作、reduce操作

如上图所示,Stream的操作可以分为上面几部
1.创建一个Strream,最常用的就是通过集合的.stream方法将一个集合转化为Stream,Java8中所有的集合都实现了这个方法,可以轻松调用。
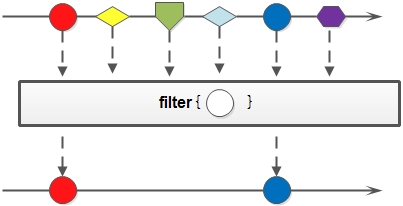
2.Stream的过滤方法,这个方法传入了一个Pridicate类型的lambda表达式(上一节有提到过),它过滤出符合条件的元素,生成新的Stream,在上面代码中我们过滤出所有数学成绩及格的同学,filter示意图如下
.
3.map函数,map函数接收一个Function类型接口(在上节讲过),将Stream中的每个元素进行一个转化,生成新的Stream,上例中我们做了获取学生姓名的操作, 将Student类型的元素转化为String类型的元素,最后生成一个包学生姓名的String类型的Stream,map函数的示意图如下
4.汇聚操作,前面几步都是对Stream进行的处理,他们的返回类型都是Stream,最后一步操就是将处理后的Stream转换成List的操作,它的作用就是将Stream转换成我们需要的结果对象。本例只是汇聚操作的一小部分,Stream的汇聚操作非常强大,比如查找姓名最长的名字、计算名字的总个数。如果是Int类型的Stream,还可以进行min()、max()、average()等操作,而光是一个collect()方法,就可以玩出很多花样,后面我们会讲到。
5.惰性求值和及早求值,在上面例子中,前面的过滤、转换操作都是对Stream的一种描述,这些方法只是刻画了操作Stream的方法,并没有真正执行,这种方法叫做惰性求值方法,只有在最后调用聚集操作时,才会真正执行操作Stream的方法,生成新的集合,这种方法叫做及早求值方法。区分惰性求值方法和及早求值方法很简单,只要看方法的返回类型是否为Stream,像filter、map这种就是惰性求值方法,而collect()方法返回了一个List,就是一个及早求值方法。
二.其他转换Stream的方法
上面我们讲到了filter、map等常用的操作stream的方法,下面介绍一些其他操作Stream的方法,也非常有用
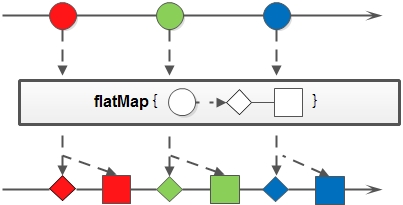
1.flatMap map是将Stream中的元素转化为另外一种类型然后生成新的Stream,flatMap和它比较相似,不过flatMap是将流中的每个元素都转化为一个Stream,然后将这些Stream拼起来,返回一个新的Stream。
看一个例子
List<Integer> together = Stream.of(asList(1, 2), asList(3, 4))
.flatMap(e -> e.stream())
.peek(e -> System.out.println(e))
.collect(toList());Stream.of(T... values)是Stream的一个静态构造函数,调用flatMap将原Stream中的每个列表转换成Stream对象,然后将Stream列表合并,生成新的Stream。flatMap方法相关函数接口和map方法一样,都是Function接口,只是方法的返回值限定为Stream罢了,flatMap的示意图如下。
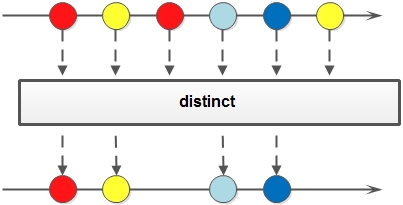
2.distinct 从名字就可以看出来它的作用是对Stream内的元素进行去重,不过去重逻辑依赖于元素的equals方法。
3.limit 同样,看到名字我们就懂这个函数的用法了,截取Stream前N个元素返回新的Stream。
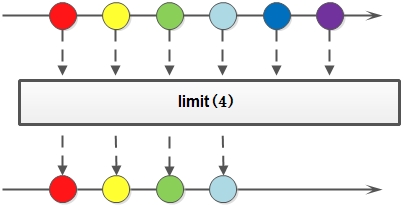
4.skip 丢弃Stream中前N个元素,返回新的Stream,若Stream中元素个数小于等于N则返回空的Stream。
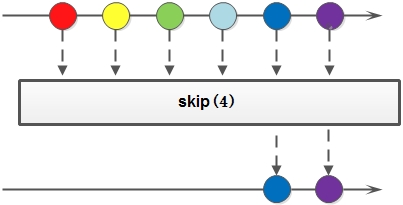
5.peek 生成一个包含原Stream的所有元素的新Stream,同时会提供一个消费函数(Consumer ),新Stream每个元素被消费的时候都会执行给定的消费函数。
先看示例图
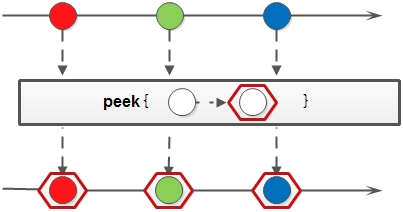
通俗地将就是对Stream中元素循环执行一段代码。
看代码
List<Integer> list = Stream.of(1, 2, 3, 4).
peek(System.out::println).collect(Collectors.toList());这段代码类似于foreach(),会依次打印流中每个元素,看peek的参数,还记得上节讲过的方法引用吗?这里引用了System.out类的println方法,这是一个Consumer类型函数接口,也可这样写 e->System.out.println(e)
三.功能强大的汇聚操作
Stream中的汇聚操作有三种:collect()、reduce()以及sum max min count等这些特殊用途的汇聚操作
1.花样繁多的收集器collec()
前面我们使用collect(toList()),从流中生成列表,这是最常见的数据结构,但有时候我们需要生成其他类型的数据结构如Map或String,
这时候就需要用到收集器了,一种通用的、从流生成复杂值的结构,只要将它传给collect方法,所有的流就可以使用它了。
幸运的是,标准类库已经为我们提供了很多有用的收集器,下面我们就来看看,以下收集器都是从java.util.stream.Collectors类中静态导入的。
(1)数据分块 partitioningBy
这个方法将流分为两部分,它接收一个Predicate 类型参数判断元素应该属于哪一部分,对true List中的元素,Predicate返回true,对false List中的元素,Predicate都返回false,下面就是将一个整数流分为两部分,true List部分大于2,false List部分小于 2
Map<Boolean, List<Integer>> map
= Stream.of(1, 2, 3, 4).collect(partitioningBy(e -> e>2));partitioningBy的示意图如下
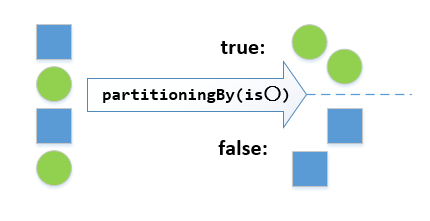
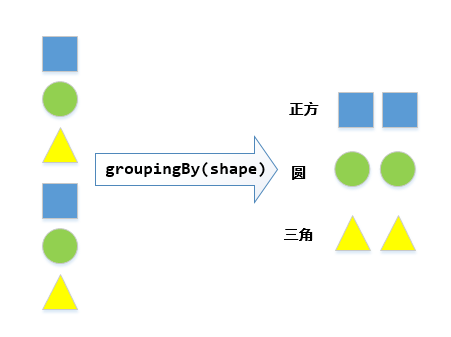
(2)数据分组 groupingBy
这个收集器接收一个Function类型参数,将数据分为不同的组,类似SQL中的group by操作。
Map<String, List<Student>> map =
students.stream().collect(groupingBy(e -> e.getClassRoom()));它的示意图如下
(3)字符串操作 jioining()
很多时候我们处理流都是为了得到一个字符串对象,比如我们希望的得到"[小明,李白,韩梅梅]"这样的学生姓字符串,在以前可能需要for循环去处理
现在只需要在流上调用joining()收集器即可,非常方便
String names =
students.stream()
.map(e -> e.getName())
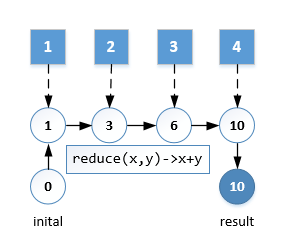
.collect(joining(",", "[", "]"));reduce操作可以实现从一组值中生成一个值。下图演示了一个reduce的典型流程,实现了对整数流的求和。
代码:
int sum = Stream.of(1, 2, 3, 4).reduce(0, (acc, e)-> acc+e);T reduce(T identity, BinaryOperator<T> accumulator);reduce第一个参数是一个初始值,用来作为第一次组合函数的参数,第二个参数是一个BinaOperator类型的函数。reduce会遍历Stream中每个函数,每一步操作都是以上一步操作的结果和当前元素作为参数,执行组合函数,生成新的结果,然后继续下一步组合函数,直到遍历完所有元素。
在本例中 reduce函数 为(acc, e) -> acc+e 它接收上一轮acc值和当前元素,返回新的acc值。
实际上,max() min() count()这些汇聚操作都是一种reduce操作,只是因为他们被经常用到,才被封装起来。
3.其他的汇聚操作
– allMatch:是不是Stream中的所有元素都满足给定的匹配条件
– anyMatch:Stream中是否存在任何一个元素满足匹配条件
– findFirst: 返回Stream中的第一个元素,如果Stream为空,返回空Optional
– noneMatch:是不是Stream中的所有元素都不满足给定的匹配条件
– max和min:使用给定的比较器(Operator),返回Stream中的最大|最小值
三.Stream的并行操作
Java8中Stream的另一大特性就是支持对Stream进行并行操作,我们只需要在将集合的stream()方法改为parallelStream()或者调用Stream的parallel()方法即可将Stream转化为一个支持并行化操作的Stream。
比如上面的一些例子就可以改成这样:
students.parallelStream()
.filter(e -> e.getMathScore()>=60)
.map(e -> e.getName()).collect(toList());//并行过滤和map
int sum = Stream.of(1, 2, 3, 4).parallel().reduce(0, (acc, e)-> acc+e);//并行求和1.reduce初始值必须为组合函数的“恒等值”,拿恒等值和其他值作组合操作时,其他值必须保持不变。用公式来表示就是R(inital, element)=element,R代表reduce参数中的组合函数,比如用reduce操作求和,组合函数为(acc, element) -> acc+element,则其初值必须为0,因为任何数字加0,值不变。
2.组合函数必须符合结合律。用公式表示就是R(R(a, b), c)=R(a, R(b,c))
只有reduce操作满足这两点约束,才能在并行环境下正常工作,关于这个结论的证明,在此就不详细列出,有兴趣的读者欢迎和笔者讨论。
因为笔者不建议大家过度使用并行操作,除了一些简单的运算。第一要注意reduce的这两个约束,第二并行流是否比串行流快,这一点在实际生产环境中是有很多影响因素的:数据大小、数据结构、是否装箱、物理机核的数量、单元处理开销等等。有可能一个流并行处理后的耗时比串行还慢。
关于Stream的知识就介绍到这里, 大家在平时开发过程中可以多使用流去处理一些集合,或者将老旧的代码用Stream的操作方式重构,相信会有很大收获,Stream的API很多,只有多用多练,才能灵活使用。
下节我们将为大家带来Java8的另一大特性Optional的用法介绍,欢迎关注。
上节回顾《初始Java8- lambda表达式》
PS:部分示意图来自[RxJava](https://github.com/Netflix/RxJava)














 2028
2028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









