







概述,生态系统以及周边的配套
- 本地实现
- 线上 HDFS 实现
运行的时候
- 交互式 shell 编写
- IDE 编写
对spark内核进行解析,结合源码,能写基本代码
对 transformation 了解,map(),能写代码
什么是 Spark ?
Apache Spark is an open source cluster computing system that aims to make data analytics fast — both fast to run and fast to write
不仅分析快,写代码也快
以下为 the Berkeley Data Analytics Stack (BDAS)
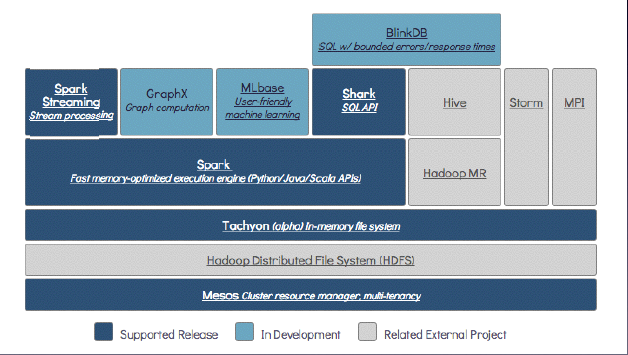
Mesos 与 yarn 功效类似,有效区别
国内用 yarn 比较多,生态系统 yarn 更多一些
Mesos 的上一层是 分布式文件系统 HDFS
Tachyan 是分布式内存文件系统,并不仅支持 spark,也支持map-reduce
hadoop2.3.0 的datanode 也支持 cache(重大改进)
Spark Streaming Stream processing 是实时流处理
GraphX 是个图处理
MLlib 是个机器学习库
Shark SQL API 相当于 Hive on Spark ,相当于在 spark 上面建立一个 SQL
BlinkDB是海量数据上运行交互式SQL查询的大规模并行查询引擎,它允许用户通过传衡数据精度提升查询响应时间,可以将查询时间限制在误差范围之内
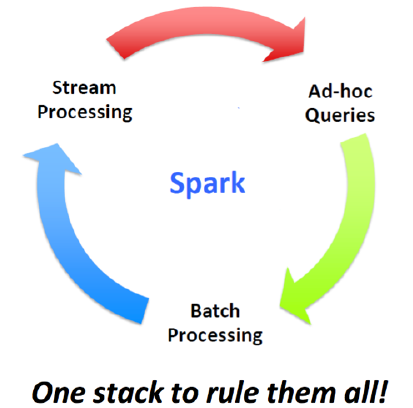
只需要一个站,就可以将所有都搞定了!无论是实时查询、流处理还是批处理,都可以实现
而以往的 Hadoop MapReduce来进行海量数据的分析,用 Strom 来进行实时流处理,Hive来做 SQL 处理,但维护这么多系统,必然会出现很多问题!spark 却不会出现这些问题,因为兼容好,原始设计的初衷也是这样。spark 是最有希望成为下一代分布式计算系统
回顾 Hadoop
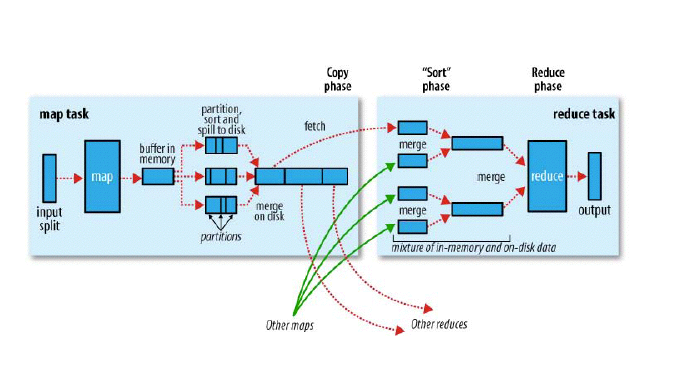
- 两个阶段,map / reduce
- 每个 map 从 HDFS 若干个数据处理,input split 。inputfomat,将 hdfs上的数据处理为 key-value。通过inputfomat 实现。可供用户的 map 程序执行。排序后的会不断的spilt到 disk 上
- 然后有一各分片的过程,partition过程 。map需要哪找 partiton 过程 , 可以指定分片被放在哪个 reduce 上。一个排好序的大文件
- combine 相当于在本地已经进行 reduce 的过程了。
- reduce 就是”要“数据,从map拿数据,数据量大放在磁盘上,数据量小,放在内存上。但由于小文件过多,全在内存,会爆。
面试必问题
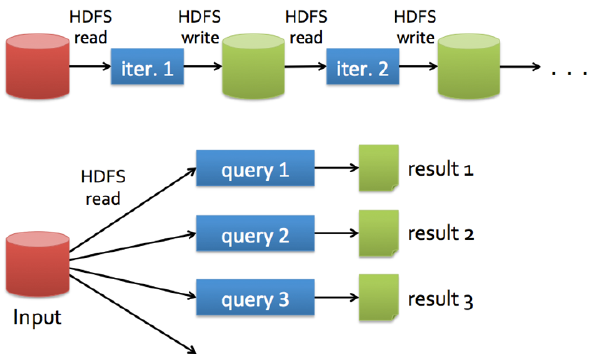
Hadoop的数据共享?慢
为什么慢???额外的复制,序列化和磁盘IO开销
每次迭代操作写入和写出都是在 hdfs 上完成的。然而数据挖掘和机器学习 迭代次数非常多
将来 spark 从 datanode(有 cache)上取数据将非常完美了
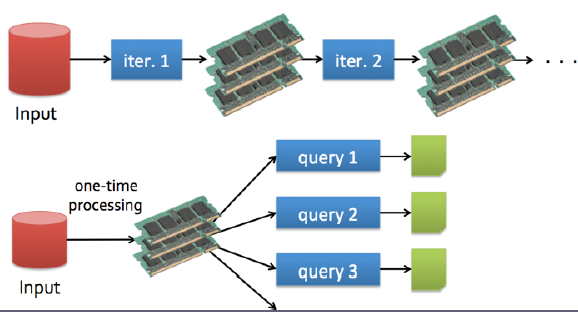
十几G和百来G很适合 spark
Spark的快只是因为内存?
- 内存计算
- DAG 是把整个执行过程做成一张图,然后再进行优化
很多优化措施其实是相通的,譬如说delay scheduling
比如 A节点上正在运行程序,当 B 节点需要从 A 节点上获取资源时,那么将延迟一段时间在执行。这样可以避免以往从忙碌的A节点上复制数据,这样是很耗费时间的,因为如果等待也许只需要几秒钟呢…
Spark API
- 支持3种语⾔言的API
- Scala(很好)
- Python(不错)
- Java(不建议)
通过哪些模式运行Spark呢
有4种模式可以运⾏
- local(多⽤用于测试)
- Standalone
- Mesos
- YARN(工作时)
一切都以RDD为基础
- A list of partitions(源代码里的注释里)一系列的分片
A function for computing each split
定义一个函数计算或迭代A list of dependencies on other RDDs
一系列的依赖,RDD(a)->RDD(b)->RDD(c) ,则C 依赖 B ,B依赖A,这样就相互依赖Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
告诉它怎么去分片的,利用小的技巧,可以避免很大的shuffle,避免宽依赖,优化成窄依赖Optionally, a list of preferred locations to compute each split on(e.g. block locations for an HDFS file)
选择最优的计算机子来进行,
Spark runtime
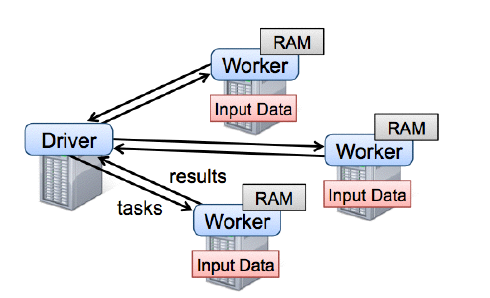
用户的 driver 程序,各个 worker 从分布式系统中获取数据并计算,把结果持久化。
流程图示意
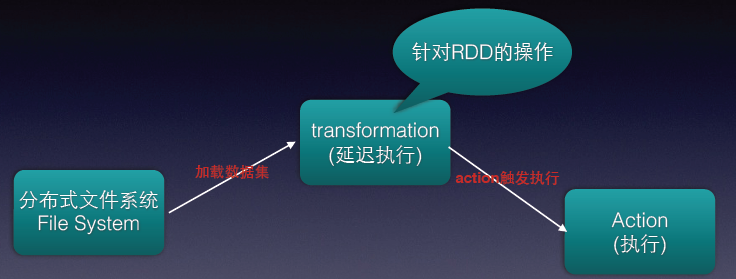
其中的 transformation 操作是针对 RDD 操作的,且是延迟执行的(比如 map()操作),spark 并不会真正执行,而是会在原数据下记录下即将对 A 进行 map 操作。到 action 才会执行。
RDD可以从集合直接转换⽽而来,也可以由从现存的任何Hadoop InputFormat⽽而来,亦或者HBase等等,但国内应用比较少
first demo

- sc 即为 sparkcontents
- lines 代表取了很多数据
- .filter() 过滤,再次强调这里的 transformation 延迟
- 有count 就是代表执行的操作
缓存策略
class StorageLevel private(!
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









