







 不均衡学习中,抽样方法是通过过抽样(增加少数类样本)和欠抽样(减少多数类样本)来改善数据分布。随机过抽样简单易行但可能导致过拟合,欠抽样可能丢失重要信息。informed 欠抽样的 EasyEnsemble 和 BalanceCascade 算法可避免信息缺失。合成抽样方法如 SMOTE 通过生成新样本减轻过拟合。数据清洗技术如 Tomek 线可用于消除重复样本,提高分类性能。实验表明,选择适合数据分布的预处理方法是关键。
不均衡学习中,抽样方法是通过过抽样(增加少数类样本)和欠抽样(减少多数类样本)来改善数据分布。随机过抽样简单易行但可能导致过拟合,欠抽样可能丢失重要信息。informed 欠抽样的 EasyEnsemble 和 BalanceCascade 算法可避免信息缺失。合成抽样方法如 SMOTE 通过生成新样本减轻过拟合。数据清洗技术如 Tomek 线可用于消除重复样本,提高分类性能。实验表明,选择适合数据分布的预处理方法是关键。
通常情况下,在不均衡学习应用中使用抽样方法的目的就是为了通过一些机制改善不均衡数据集,以期获得一个均衡的数据分布。
研究表明,对于一些基分类器来说,与不均衡的数据集相比一个均衡的数据集可以提高全局的分类性能。数据层面的处理方法是处理不均衡数据分类问题的重要途径之一,它的实现方法主要分为对多数类样本的欠抽样和对少数类样本的过抽样学习两种。其主要思想是通过合理的删减或者增加一些样本来实现数据均衡的目的,进而降低数据不均衡给分类器带来的负面影响。
按照对样本数量的影响又可分为:
- 过抽样,即合理地增加少数类的样本
- 欠抽样,即合理地删减多数类样本
随机过抽样和欠抽样
随机过抽样
随机过抽样是一种按照下面的描述从少数类中速记抽样生成子集合 E 的方法。
- 首先在少数类 Smin 集合中随机选中一些少数类样本
- 然后通过复制所选样本生成样本集合 E
- 将它们添加到 Smin 中来扩大原始数据集从而得到新的少数类集合 Smin−new
用这样方法, Smin 中的总样本数增加了 |E| 个新样本,且 Smin−new 的类分布均衡度进行相应的调整,如此操作可以改变类分布平衡度从而达到所需水平。
欠抽样
欠抽样技术是将数据从原始数据集中移除。
- 首先我们从 Smaj 中随机地选取一些多数类样本 E
- 将这些样本从 Smaj 中移除,就有 |Smaj−new|=|Smaj|−|E|
缺陷
初看,过抽样和欠抽样技术在功能上似乎是等价的,因为它们都能改变原始数据集的样本容量且能够获得一个相同比例的平衡。
但是,这个共同点只是表面现象,这是因为这两种方法都将会产生不同的降低分类器学习能力的负面效果。
- 对于欠抽样算法,将多数类样本删除有可能会导致分类器丢失有关多数类的重要信息。
- 对于过抽样算法,虽然只是简单地将复制后的数据添加到原始数据集中,且某些样本的多个实例都是“并列的”,但这样也可能会导致分类器学习出现过拟合现象,对于同一个样本的多个复本产生多个规则条例,这就使得规则过于具体化;虽然在这种情况下,分类器的训练精度会很高,但在位置样本的分类性能就会非常不理想。
informed 欠抽样
两个 informed 欠抽样算法:EasyEnsemble 和 BalanceCascade 算法,这两种方法克服了传统随机欠抽样方法导致的信息缺失的问题,且表现出较好的不均衡数据分类性能。
EasyEnsemble 和 BalanceCascade 算法介绍
1. EasyEnsemble 核心思想是:
- 首先通过从多数类中独立随机抽取出若干子集
- 将每个子集与少数类数据联合起来训练生成多个基分类器
- 最终将这些基分类器组合形成一个集成学习系统
EasyEnsemble 算法被认为是非监督学习算法,因此它每次都独立利用可放回随机抽样机制来提取多数类样本
2. BalanceCascade 核心思想是:
- 使用之前已形成的集成分类器来为下一次训练选择多类样本
- 然后再进行欠抽样
最近邻规则(ENN)
因为随机欠抽样方法未考虑样本的分布情况,采样具有很大的随机性,可能会删除重要的多数类样本信息。针对以上的不足,Wilson 等人提出了一种最近邻规则(edited nearest neighbor: ENN)。
- 基本思想:删除那些类别与其最近的三个近邻样本中的两个或两个以上的样本类别不同的样本
- 缺点:因为大多数的多数类样本的样本附近都是多数类,所以该方法所能删除的多数类样本十分有限。
领域清理规则 (NCL)
Laur Ikkala J 等人在 ENN 的基础行提出了 领域清理规则 (neighborhod cleaning rule: NCL)。该算法的整体流程图如下所示:
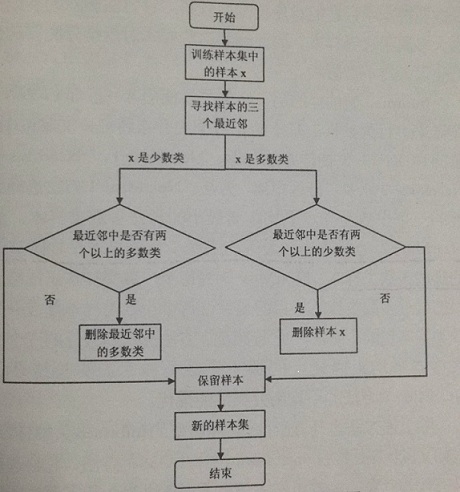
- 主要思想:针对训练样本集中的每个样本找出其三个最近邻样本,若该样本是多数类样本且其三个最近邻中有两个以上是少数类样本,则删除它;反之当该样本是少数类并且其三个最近邻中有两个以上是多数类样本,则去除近邻中的多数类样本。
- 缺陷:未能考虑到在少数类样本中存在的噪声样本而且第二种方法删除的多数类样本大多属于边界样本,删除这些样本,对后续分类器的分类产生很大的不良影响。
K-近邻(KNN)
基于给定数据的分布特征,有四种 KNN 欠抽样方法:
1. NearMiss-1
选择到最近的三个少数类样本平均距离最小的那些多数类样本
2. NearMiss-2
选择到最远的三个少数类样本平均距离最小的那些多数类样本
3. NearMiss-3
为每个少数类样本选择给定数目的最近多数类样本,目的是保证每个少数类样本都被一些多数类样本包围
4. 最远距离
选择到最近的三个少数类样本平均距离最大的那些多数类样本
Note:实验结果表明 NearMiss-2 方法的不均衡分类性能最优
数据生成的合成抽样方法
在合成抽样技术方面, Chawla NV 等人提出的 SMOTE 过抽样技术是一个强有力的方法。SMOTE 过抽样技术与传统的简单样本复制的过抽样方法不同,它是利用少数类样本控制人工样本的生成与分布,实现数据集均衡的目的,而且该方法可以有效地解决由于决策区间较小导致的分类过拟合问题。
SMOTE 算法是利用特征空间中现存少数类样本之间的相似性来建立人工数据的。特别是,对于子集 Smin⊂S ,对于每一个样本 xi⊂Smin 使用 K-近邻法,其中 K 是某些制定的整数。
这里 K-近邻 被定义为考虑 Smin 中的 K 个元素本身与 xi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









