相关文章:
Facebook的物体分割新框架研究1——写在前面
Facebook的物体分割新框架研究2——DeepMask
二、SharpMask【Learning to Refine Object Segments.2016 ECCV】
从名字就能看出来,主要为了是refine DeepMask的输出。DeepMask的问题在于它用了一个非常简单的前向网络产生粗略的object mask,但不是像素级别准确的分割。显然因为DeepMask采用了双线性上采样以达到和输入图像相同大小这一机制,使得物体边缘是粗略估计出来的,不准确。SharpMask的insight来自,物体精确地边缘信息可以从low-level图像中得到,与网络高层的物体信息结合,应该能够得到比较精确的边缘。因此主要的思路是,首先用DeepMask生成粗略的mask,然后把这个粗略的mask通过贯穿网络的很多refinement模块,生成最终的精细mask。
1.网络结构
显然网络信息流除了传统的自下而上,还得有自上而下的通道,网络结构是:
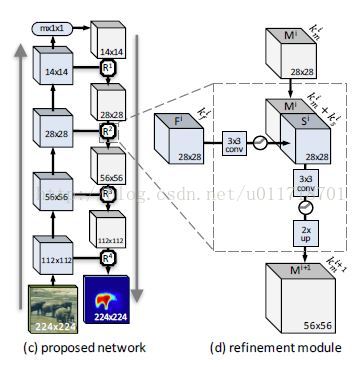
可以看到自下而上的过程是传统的前向CNN网络,比如DeepMask(本文后面还调研了其他网络结构 例如ResNet等),输出一个粗略的mask,然后需要逐层融合low-level的特征来找到精确的物体边缘等信息。
2.Refinement 模块
refinement模块的作用是逆转pooling的作用,输入上层传下来的mask encoding和自下而上传递过来的匹配的features map,并且融合两个过程的信息来生成一个新的mask encoding,有着两倍的空间分辨率。这个过程一直持续到patch的全部分辨率被恢复,然后最后的输出就是精细的object mask。
每个模块Ri的输入是来自上一层的mask Mi和来自下一层的feature Fi(是pooling前的卷积层的输出),他们的空间分辨率是相同的,通道数分别是kmi和kfi,refinement要完成的就是Mi+1 = Ri(Mi,Fi)。通常,kfi很大,而且远远大于kmi,所以如果直接把它们级联起来的话,一是运算量会特别大,二是会淹没Mi中的信号。
所以文章采取的方式是:首先用一个3*3的卷积层(有ReLU)作用在Fi上,减少它的通道数kfi,但是保持空间分辨率不变,这样就产生了一个‘skip’feature Si,ksi远远小于kfi。现在就可以把Si和Mi直接在通道维度级联起来了,生成ksi+kmi通道的feature map。然后通过一个3*3的卷积层(有ReLU),再经过双线性上采样得到refinement模块的最终输出Mi+1,通道数kmi+1由卷积层的kernel个数决定。
refinement模块的操作只有卷积、ReLU、双线性上采样和级联,因此完全是可以反向传播的。其中比较重要的是ksi和kmi既不能过大使得计算量繁重,也不能过小丢失了信息,所以一开始可以用一个比较大的值,随着空间分辨率越来越大,逐渐减小通道数目(这和一般的前向网络正好相反有木有~)。
显然,refinement模块的数目应该等于前向网络中pooling层的数目。
训练过程分两个阶段:第一阶段和DeepMask一毛一样;第二阶段,等第一阶段收敛了之后呢,去掉前向网络最后的mask预测层,换成一个线性层,这个线性层产生一个mask encoding M1来代替实际的mask输出。然后“冻住”前向网络的参数不再变化,用SGD训练refinement网络。
整图推断的时候,与DeepMask相似,相邻窗口的大部分计算都通过卷积共享了,包括skip层Si【这里博主一开始没有看懂什么意思。。后来觉得是这样吧,image patch是224像素的,整图推断时候stride是16像素,所以有着很大部分的重叠呢。但是博主又想了,难道你还要搞一个内存记录下那些部分已经被计算过了?真的不会更麻烦吗?用存储换时间?】。不过,refinement模块在每个空间位置都会输入一个唯一的M1,因此这个阶段计算在每个空间位置是独立进行的,就没法子共享啦~
为了减少计算,也不是每个位置的proposal都要refine的啦,而是选择N个score最大的proposal,这N个作为一个batch【SGD的batch】一起优化。
3.前向网络结构研究
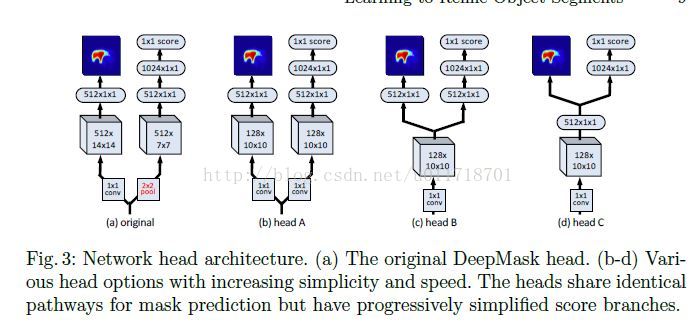
文中,把segmentation和scoring共享的叫做Trunk architecture,二者独有的叫做Head architecture。
使用ImageNet上训练好的50层Residual Network代替VGG-A,研究了输入尺寸W、pooling层个数、步长S、模型深度D和最终的feature通道数F。
这部分没啥难理解的,就是选择参数,博主就不详细总结了,毕竟我们分析SharpMask是为了借鉴它的思想。~
作者们觉得,原来的结构里mask和score分支都需要比较大的卷积操作,而且score分支还得有个额外的pooling层,太不美观了,所以设计了下列的变形,主要是想让两个分支可以share more computation。
最后通过实验采用W160-P4-D39-F128的trunk architecture和C head architecture作为最终的前向网络,称为DeepMask-ours【你的你的都是你的。。这名起的跟谁要夺你版权似的= =】
DeepMask-ours和refinement一结合,就是我们的主角:SharpMask了,它是2016年COCO数据集上的state-of-the-art。博主觉得最值得借鉴的部分就是想办法把低层的像素级别的信息和高层的物体级别的信息融合,因此未来我们可以设计更好的融合方案,也许能大大提高性能。


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









