







相关文章:
Facebook的物体分割新框架研究3——SharpMask
MSRA Instace-aware semantic segmentation框架:InstanceFCN、R-FCN、FCIS
二、MultiPathNet【A MultiPath Network for Object Detection.2016 ECCV】
有了DeepMask输出的粗略分割mask,经过SharpMask refine边缘,接下来就要靠MultiPathNet来对mask中的物体进行识别分类了。MultiPathNet目的是提高物体检测性能,包括定位的精确度和解决一些尺度、遮挡、集群的问题。网络的起点是Fast R-CNN,所以如果你不知道Fast R-CNN是什么,先阅读博主关于Fast R-CNN的笔记吧 关于Faster R-CNN的一切——笔记2:Fast R-CNN~基本上,MultiPathNet就是把Fast R-CNN与DeepMask/SharpMask一起使用,但是做了一些特殊的改造,例如:skip connections、foveal regions和integral loss function。
1.背景工作
显然自从Fast R-CNN出现以来的object detector基本都是将它作为起点,进行一些改造,我们先来总结一下这些改造,以便理解本文的想法。
- Context
【还记得上马惠敏老师的课的时候,她说了句离开环境就不要谈识别,深有感悟。。】核心思想就是利用物体周围的环境信息,比如有人在每个物体周围crop了10个contextual区域辅助检测。本文就是借鉴这种做法不过只用了4个contextual区域,涉及特殊的结构。
- Skip connections
Sermanet提出一个多阶段的分类器利用许多个卷积层的特征来实现行人检测,取得了很好的效果,这种‘skip’结构最近在语义分割方面也很火呐~
- Classifers
大家都知道现在基本上是CNN结构的天下啦。。。本文用的是VGG-D,如果和何凯明的ResNet结合效果应该会更好哒。
2.网络结构
先上整个结构图:
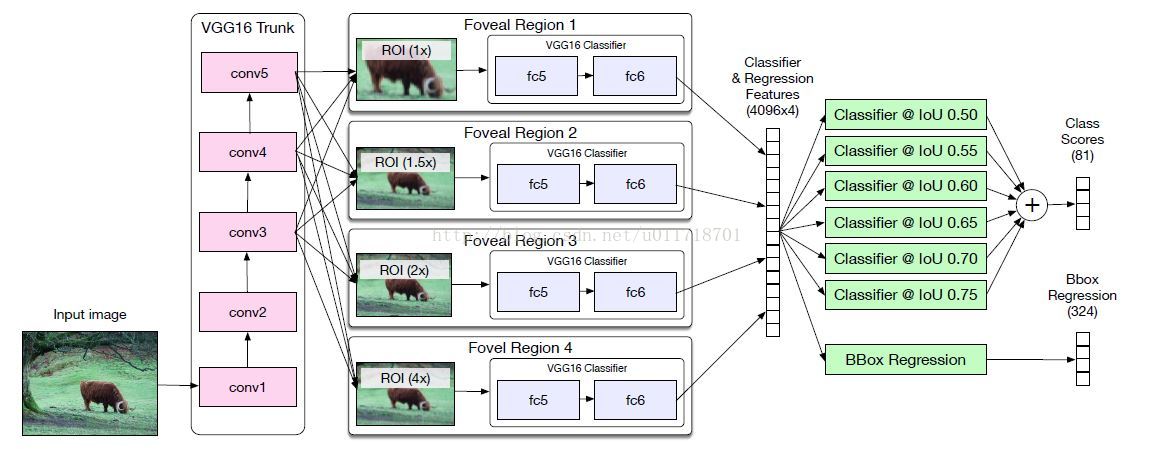
是不是蒙圈了?博主也是∑(っ °Д °;)っ,没关系咱一个一个部分地捋哈~
- Foveal regions
像Fast R-CNN一样,图像先经过VGG16的13个卷积层生成conv feature map【有人要问博主了,明明是conv1-5怎么13层呢?咳咳,数字代表的其实是卷积层的通道数发生了变化,比如conv1其实代表两个3*3,64kernel的卷积层;conv5代表三个3*3,512个kernel的卷积层。宝宝们请自行查阅VGG16的结构数数就明白了~】,然后经过RoI pooling层提取特征【如果你还记得Fast R-CNN的话,RoI pooling层其实就是一种把图像特征映射到一个能够描述regions的固定大小的feature map的方式~】。从结构图里可以看到,对每个object proposal,都产生4个不同的region crops,相当于从不同的尺度来看这个物体,这就是所谓的‘foveal region’【为啥这样就能达到利用contextual信息了呢?楼主觉得可能因为相同大小的RoI,物体尺寸变小,相应的包含进来的contextual信息就多了吧~】。
- Skip connections
VGG16有四个pooling层,所以图像尺寸会/16,那我们设想一个32*32大小的物体,经过VGG16就剩2*2了。。虽然RoI pooling层输出7*7的feature map,但是很显然我们损失了太多的空间信息 。
所以呢,要把conv3(/4*256)、conv4(/8*512)、conv5(/16*512)层的【RoI-pooled normalized 】feature级联起来一起送到foveal分类器(这个说得太模糊了,博主只好暂停这篇paper,去看了这个【Inside-Outside Net:Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks.CVPR 2016】才搞清楚,不明白的宝宝也可以去看看),这种级联使得foveal分类器可以利用不同位置的特征,有种弥补空间信息损失的味道在里面呢~注意需要用1*1的卷积层把级联特征的维度降低到分类器的输入维度喔。
【下面这话说得有点匪夷所思,好像并没有在网络结构图里体现出来啊??】文章说,他们只把conv3连接到1×的分类器head,conv4连接到1×、1.5×和2×的head。
- Integral Loss
在原来的Fast R-CNN中,如果一个proposal与一个ground-truth box的IoU大于50,那么就给它分配ground-truth的标签,否则就是0。然后在Fast R-CNN的分类loss里面(用的是log loss),对所有proposal的IoU大于50的一样对待,这其实有点不合理:我们希望IoU越大的对loss的贡献越大吧~所以本文就用Integral loss代替了原来Fast-RCNN的分类loss:
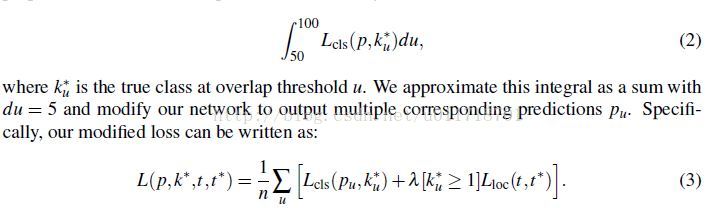
那当然积分就要用加和的方式近似啦,本文选择用n=6个不同的阈值,所以现在对每一个object rpoposal实际上有n个ground-truth label了,每个阈值一个~相应的每个阈值应该也得有一个分类输出的概率吧,所以我们看到结构图最后有6个分类器。在inference的时候,每个分类器的softmax概率输出求平均得到最终的class probabilities。
最后的实验部分博主就不写了~其实作者只是想在COCO集上提供一个baseline~所以大家还有很多改进空间呐。比如怎么更好的利用环境信息?
-The End-
- Skip connections
VGG16有四个pooling层,所以图像尺寸















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









