







完成Hadoop上的搭建,开始运行几个小的测试,毕竟第一次,遇到了一些小问题。
首先,是参考资料中的 验证安装是否成功的步骤。
将下载数据 synthetic_control.data 上传到HDFS中,命令如下
(1) hadoop fs -mkdir testdata(注意,此命令的文件夹路径必须是如上,不可是/testdata 等其他形式)
(2) hadoop fs -put synthetic_control.data(注意,如果数据不是当前文件夹下,应该添加相对或者绝对路径) testdata/
(3) hadoop fs -ls testdata (查看是否上传成功)
数据上传成功之后,开始运行测试聚类程序,命令如下
(4) hadoop jar mahout-distribution-0.9/mahout-examples-0.9-job.jar (注意路径) org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
运行完成之后,查看结果
hadoop fs -ls output(注意路径)
完成。
其次,在运行数据序列化时遇到问题,就是将HDFS中数据转成Mahout可以识别额输入格式。
会提示,Exception in thread "main" Java.lang.NoClassDefFoundError: org/apache/mahout/common/AbstractJob 错误!!!!
这是因为没有将mahout中的jar文件进行相关的导入。网上找的一些解决方法,如下
要想让mapreduce程序引用第三方jar文件, 可以采用如下方式:
1。通过命令行参数传递jar文件, 如-libjars等;
2。直接在conf中设置, 如conf.set(“tmpjars”,*.jar), jar文件用逗号隔开;
3。利用分布式缓存, 如DistributedCache.addArchiveToClassPath(path, job), 此处的path必须是hdfs, 即自己讲jar上传到hdfs上, 然后将路径加入到分布式缓存中;第三方jar文件和自己的程序打包到一个jar文件中, 程序通过job.getJar()将获得整个文件并将其传至hdfs上. (很笨重)
4。在每台机器的$HADOOP_HOME/lib目录中加入jar文件. (不推荐)
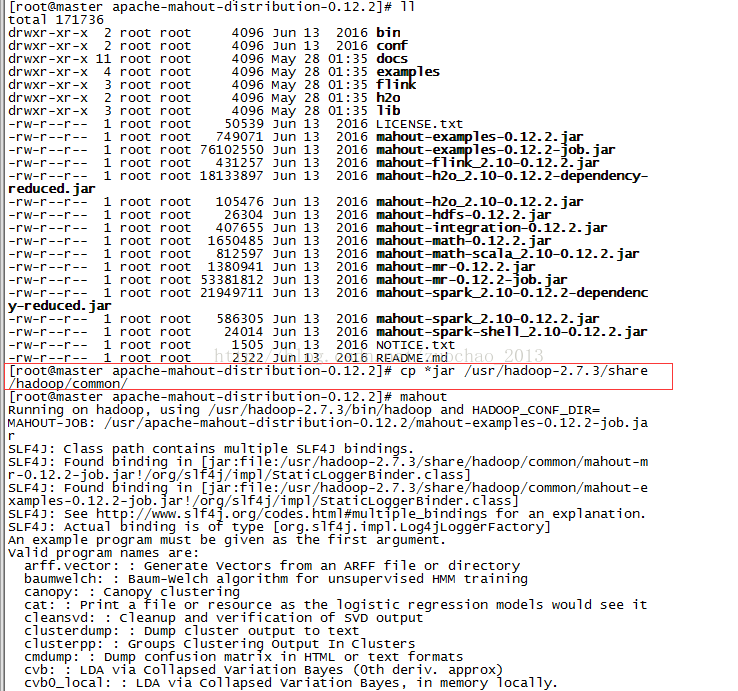
前三种没有研究和验证,使用的第四种,但是这里注意,hadoop老的版本放入lib文件夹下可以,我使用的是hadoop-2.5.2,需要将jar文件放到$HADOOP_HOME/share/hadoop/common 或者其他文件夹中。
完成之后,就可以正常执行了。
解决办法:














 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









