







计算机中字符的编码方式是很基础很重要的内容,本文主要介绍常用的一些编码方式,以备快速查找和复习。
1.ASCII基本字符集
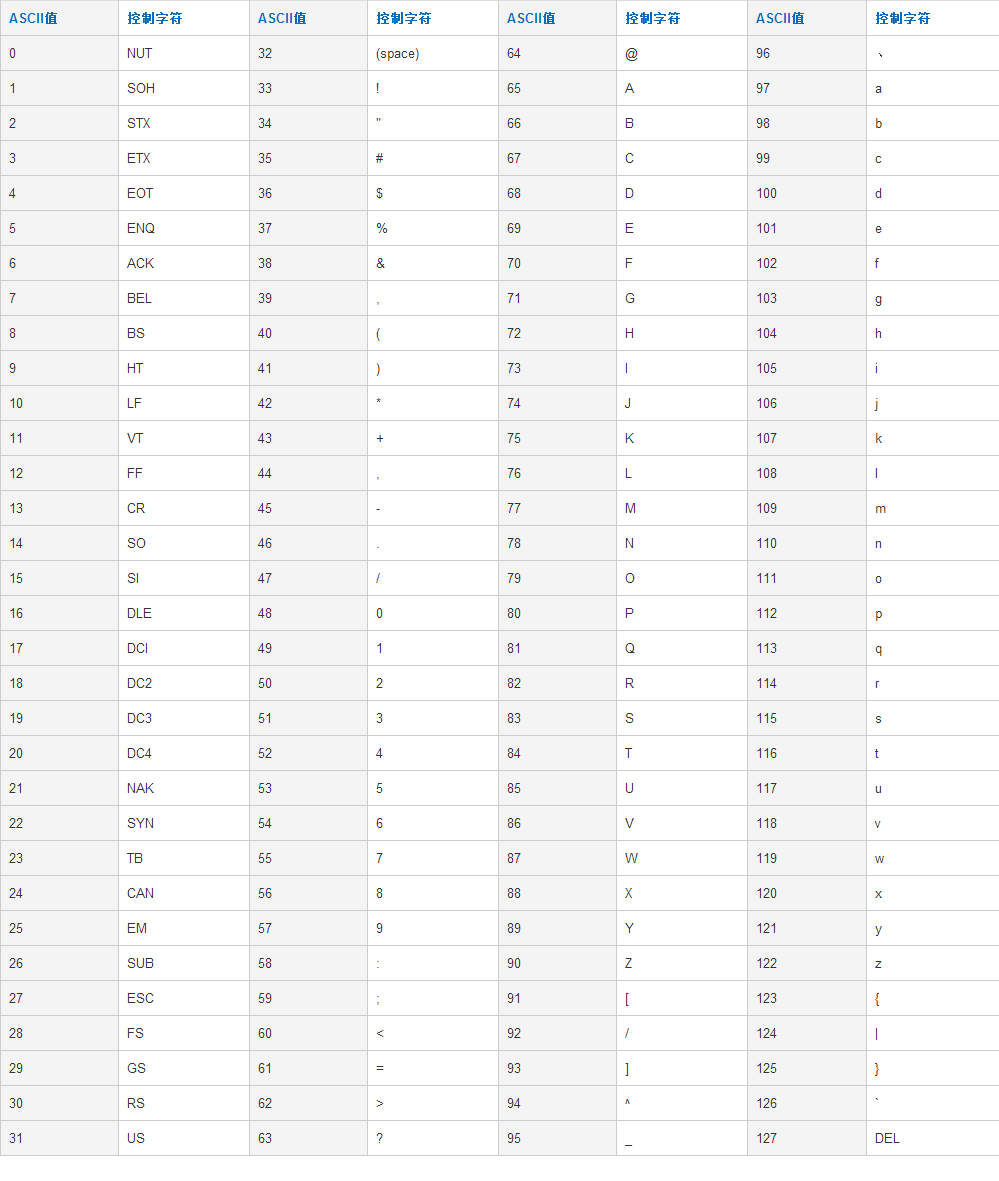
ASCII全称American Standard Code for Information Interchange,翻译为“美国信息交换标准代码”,用一个字节(8bit)来表示计算机中的各种符号。在8bit中,最高位一直保持为0,所以一个字节能表示的符号数为2^7=128个,也就是0~127。其中0~31为控制字符,32~127为可打印字符,如此可以把所有的英文字母(包括大小写)都包含进去了。
ASCII码表如下所示:
2.ASCII扩展字符集
由于ASCII基本字符集只能显示英文和有限的符号,为了能够让它可以显示其它的文字符号和更多的图画符号,人们在使用一个字节的基础上保留0~127代表的意思不变,使得最高位可以为1,如此可以利用后面的128~255来表示额外的符号。
扩展字符集可以参考:ASCII 编码及扩展编码表
3.GB2312
由于一个字节的编码范围只有0~255,对于我们中文来说,怎么样都不够用,那么只有另谋出路了。首先,英文对我们也很重要,所以保持一个字节的ASCII基本字符编码不变,舍弃扩展的字符集。对于我们的汉字和汉语符号,采用两个字节来进行编码。其中,第一个字节表示的数称为“区”,第二个字节表示的数称为“位”,所以也可以称为“区位码”。我们首先可以根据GB2312区位表来查询某个汉字的区位码,比如“啊”的区位码即1601。如下图所示:

该区位码转换成16进制就是0x10,0x01。而ASCII基本字符集占用了十六进制的0x00~0x7f。因此,计算机收到0x10,0x01时就不知道到底该表示为汉字还是英文字符。为了解决这个问题,我们需要在区位码的高字节和低字节上分别加上0xA0(越过0~127),如此,形成GB2312编码。比如,“阿”在加上0xA0后变成了0xB0,0xA1,那么这个就是汉字“啊”的GB2312编码。由GB2312区位表可计算出高字节的范围是B0~F7,低字节的范围是A1~FE。
为什么要使用十六进制?
我们都知道计算机中的数据都是以二进制形式存储的,之所以使用十六进制是为了程序员编程的方便。比如,定义一个变量为255的时候,我们需要写16个1,相信你也不愿意吧,然后引入十六进制后,我们可以用FF来便捷的表示,这样不是更好吗?
当然,你也可以使用十进制或者八进制甚至是二进制,这也就是为什么我们需要为特殊进制的数字加上特定的符号,要不然计算机程序自己也不理解了。比如:
//十进制
int x = 255;
//十六进制
int y = 0xff;
//八进制
int z = 0377;
//二进制
int a = 0b1111_1111;
GB2312共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
4.GBK
我们国家的汉字远远不止7000个,为了能更多的显示汉字,我们又扩展了GB2312。因为ASCII的表示中,一个字节的最高位都为0(表示未定义)。我们现在有如下的规定,当计算机碰到的第一个字节,如果它的最高位为1,那么当前字节和下一个字节这两个字节就用来表示一个汉字;如果碰到的第一个字节最高位为0,还是使用ASCII(即,一字节兼容ASCII)。由此,我们可以大大地增加两个字节表示汉字的使用效率。由GBK编码表可知编码范围为8140~FEFE。剔除xx7F码位(空白),共23940个码位。共收录汉字和图形符号21886个,其中汉字(包括部首和构件)21003个,图形符号883个。
5.GB18030
汉字的问题是解决了,然后我国有那么多民族,那么多语言文字,也该为少数民族使用计算机考虑一下吧。因此,出现了一种变长编码方式,就是用不同的字节来对不同的文字符号进行编码,这个有点类似UTF-8,可以下本文的下面看到。
6.BIG5和JIS
BIG5是台湾地区用来表示汉字的编码方式,JIS是日本用来表示他们文字的编码方式,这两种也是采用两个字节来表示一个文字符号,但是这里要说的是接下来的问题。比如,在GB18030中用来表示“好”的字节编码在BIG5和JIS中却表示不同的符号,所以相同的文件在不同的编码方式下会出现乱码的问题。
7.Unicode
国际标准化组织ISO为了开发出一套能表示世界上所有文字符号的方案提出了UCS,全称Universal Multiple-Octet Coded Character Set。这一大串英文简称UCS,俗称Unicode,所以UCS和Unicode指的是同一个东西。Unicode规定,所有的文字符号都用两个字节来表示,即UCS-2。然而,两个字节可能还是不够全世界用的,因为两个字节总共才65536,我们汉字加起来就可能全用完了。所以,后来又有了UCS-4,没错,就是用四个字节来对全世界的文字符号进行编码,这下总算是够了。这样世界上每个文字符号在这种编码方式下都有了自己的ID号,从此成功地解决了乱码的问题。但是,英文符号只需要一个字节就可以表示,所以用来表示英文的Unicode码的高字节一直是0,造成了浪费。
8.UTF-8
Unicode对于英文国家来说实在是太浪费了,特别是在网络传输和数据保存上,因此出现了UTF-8编码规则。UTF-8是一种变长编码方式,可以使用1~4个字节来表示某一符号,不同的符号对应的UTF-8编码可能不是等长字节的。为什么要这样做呢?当然是为了减少前面说的浪费行为。
编码规则:
1.对于单字节符号,字节的首位必须为0,剩余的7位为该符号的ASCII码,其实这主要就是针对ASCII基本字符集。所以对于ASCII基本字符集而言,UTF-8编码和ASCII编码完全一样。
2.对于n个字节的符号(n>1),第一个字节的前n位为1,第n+1位为0,这样就便于让计算机知道该符号是用几个字节表示的,后面n-1个字节的前两位都是10,然后这n个字节中剩下的位用来存放该符号的Unicode码。
UTF-8编码规则表:
| Tables | Are |
|---|---|
| 1 | 0xxxxxxx |
| 2 | 110xxxxx,10xxxxxx |
| 3 | 1110xxxx,10xxxxxx,10xxxxxx |
| 4 | 11110xxx,10xxxxxx,10xxxxxx,10xxxxxx |
UTF-8编码示例:
我们使用Unicode编码查询工具查询汉字“东”的Unicode编码为4E1C,转换为二进制为0100,1110,0001,1100。根据上述UTF-8的编码规则,我们需要十六位来存放这个汉字的二进制数据,因此,选用3个字节存储。将字符编码填进去:
1110xxxx,10xxxxxx,10xxxxxx
0100 ,111000 ,011100
11100100,10111000,10011100
最终转换为十六进制为E4B89C,这就是汉字“东”的UTF-8编码。
总结
后续会增加新的内容以及更改错误的内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









