







本文只是在Ubuntu下Hadoop环境的搭建步骤,不涉及原理。供自己下次搭建时能有个参考。
1.准备下载内容
VMware Workstations
Ubuntu12.x以上版本的安装镜像
jdk.gz,最好是1.6或者1.8的版本
hadoop.gz,最好是1.2的版本
2.环境的搭建
a)虚拟机的安装
在VMware中安装好Ubuntu虚拟机,设置网络连接方式为host-only,磁盘形式为单一文件。
b)网络设置
(此时在Linux中请一直保持具有root权限)
step1:在Windows下查询到网卡VMware Network Adapter VMnet1(host-only模式的网卡)的IP地址为192.168.137.1
step2:在Linux下打开网络设置,将IP获取方式由Automatic(自动)改为Manual(手动),IP地址设置为192.168.137.100,其中前三位不变,最后一位随便指定(只要不与该网段下其它计算机冲突),子网掩码255.255.255.0,网关地址为宿主机的该网卡的IP地址,就是上述192.168.137.1
step3:此时在Windows下ping客户机,在Linux下ping 宿主机,发现两者都可以连通,则宿主机和客户机之间可以通信了。
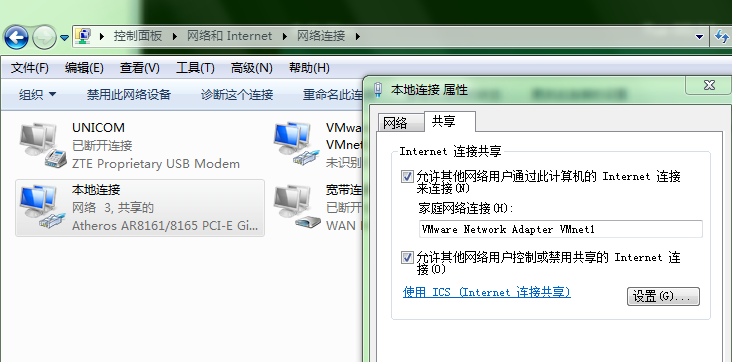
step4:在Windows找到本地连接网卡,属性,共享,勾选“允许其它网络用户通过此计算机的Internet……”,家庭网络连接选择VMware Network Adapter VMnet1。
step5:在Linux网络设置中设置DNS服务器为8.8.8.8,应用后重启系统,此时Linux客户机就可以通过Windows宿主机和外网进行通信了。
c)更换客户机的主机名
step1: sudo su输入密码进入root权限。
step2:在Shell中输入hostname,会显示Ubuntu,我们需要将主机名改成blacksheep,vi /etc/hosts,然后在顶部加入192.168.137.100 blacksheep,保存退出。此后这也是客户机的域名来代替192.168.137.100,此时在Linux中ping blacksheep和ping 192.168.137.100的效果是一样的。
d)关闭防火墙
step1:在Linux输入sudo ufw disable
step2:输入sudo ufw status 或者重启测试防火墙是否关闭
e)SSH免密码登录
step1: cd /root进入root目录
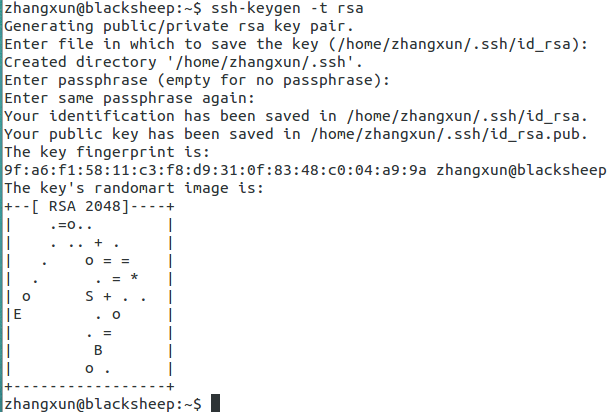
step2:输入ssh-keygen -t rsa,一路回车,如下图,会自动创建.ssh文件夹
step3: cd .ssh进入目录,输入 cp id_rsa.pub authorized_keys对公钥复制
step4:依次执行
apt-get updat
apt-get upgrade
apt-get install 'openssh-server'
进行安装(过程比较长)
step5:输入ssh localhost,然后yes来建立ssh访问。此时可以输入exit来进行验证(需要重启)。
f)安装jdk和hadoop
step1:将jdk安装包和hadoop安装包下载到DownLoads文件夹下面(这只是个示例)。
step2:cd /usr/local进入该目录下
step3:cp /home/zhangxun/Downloads/* .将所有文件复制到当前目录下
step4:tar -zxvf jdk-8u25-linux-i586.gz进行解压缩,然后发现当前目录下多出了jdk1.8.0_25文件夹,mv jdk1.8.0_25 jdk对它重命名
step5:tar -zxvf hadoop-1.1.2.tar.gz进行解压缩,多出文件夹hadoop-1.1.2文件夹,mv hadoop-1.1.2 hadoop对它重命名
step6:配置环境变量vi /etc/profile,在最下面加上如下内容:
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH然后保存退出,source /etc/profile立即生效,输入java -version发现jdk安装成功!
step7:修改hadoop配置文件(usr/local/hadoop/conf目录下)
(1)hadoop-evn.sh
将第九行的
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
修改为
export JAVA_HOME=/usr/local/jdk
(2)core-site.xml
增加以下内容
<property>
<name>fs.default.name</name>
<value>hdfs://blacksheep:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property> (3)hdfs-site.xml
增加以下内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property> (4)mapred-site.xml
增加以下内容
<property>
<name>mapred.job.tracker</name>
<value>blacksheep:9001</value>
</property> step8:对hadoop进行格式化,输入hadoop namenode -format执行结果如下:

图上提示has been successfully formatted.
3.启动hadoop
step1:进入/root,进入/usr,进入local/hadoop/bin,执行sh start-all.sh
step2:打开浏览器(Windows或者Linux)输入blcaksheep:50070访问namenode界面,输入blcaksheep:50030访问mapred界面。
4.结束
1.经过多次验证,绝对正确!
2.Ubuntu安装实在伤不起,曾经出现很多各种各样的问题,现在决定以后使用CentOs了。















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









