







OrderedDict是dict的子类,它记住了内容添加的顺序。
使用方法:
import collections
d = collections.OrderedDict()
d['a'] = 'A'
d['b'] = 'B'
d['c'] = 'C'
for k,v in d,items():
print k,v
即输出的顺序为存储的顺序。
配合使用sorted(),可以实现使字典按照value排序:
sortedDict = sorted(d.items(), key = lambda d:d[1], reverse = True)其中reverse设置为True表示逆序排序,即由大到小排序;默认情况下是由小到大排序。
运用这个知识点,可以很容易解答以下的编程题:https://www.nowcoder.com/questionTerminal/67df1d7889cf4c529576383c2e647c48?orderByHotValue=2&done=0&pos=45&onlyReference=false
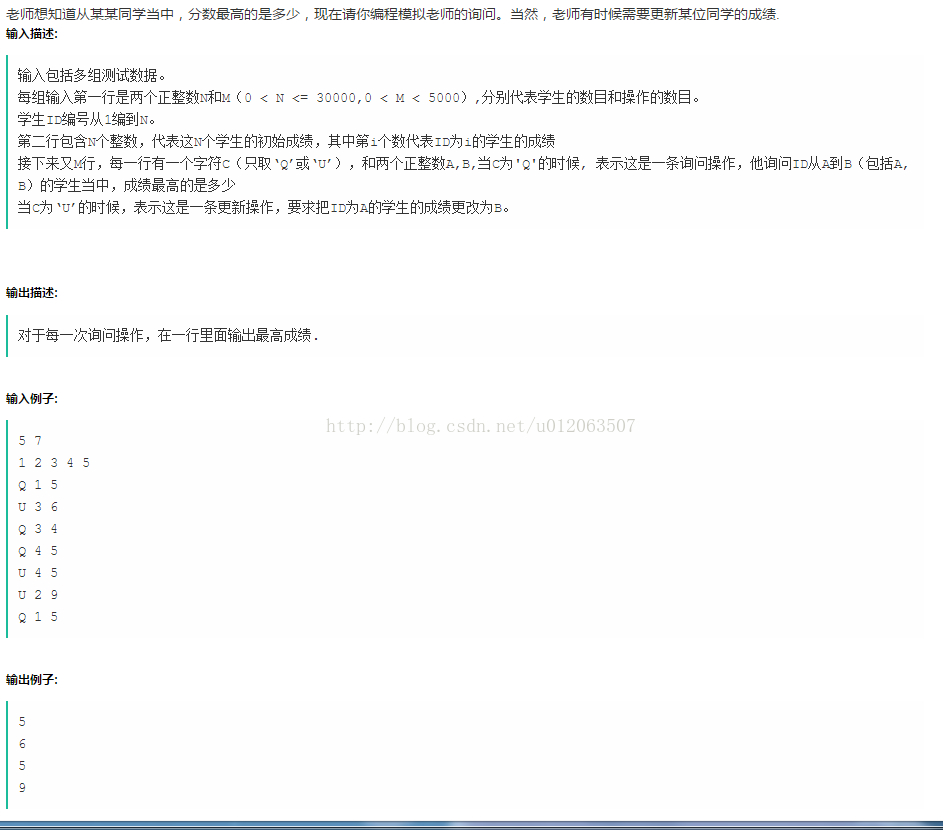
程序如下:
import sys
import collections
lst = []
dct = collections.OrderedDict()
#循环读取输入,将输入的出现次数计入有序字典里面
for line in sys.stdin:
ele = line.split('\\')[-1].strip('\n')
if ele not in lst:
lst.append(ele)
if ele in dct:
dct[ele] = dct[ele] + 1
else:
dct[ele] = 1
#对字典按照出现次数(value)排序
lstTuple = sorted(dct.items(), key = lambda d:d[1], reverse = True)
#输出不超过8行的结果
count = 0
for key in lstTuple:
if count > 7:
break
count = count + 1
#文件名取后16位
if len(key[0].split(' ')[0]) > 16:
print key[0].split(' ')[0][-16:], key[0].split(' ')[1], key[1]
else:
print key[0].split(' ')[0], key[0].split(' ')[1], key[1]
相关链接:
http://www.cnblogs.com/linyawen/archive/2012/03/15/2398292.html














 4241
4241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









