







 本文深入探讨了利用核函数的最小二乘法(RLS with Kernels)在目标跟踪中的应用。文章通过结构风险最小化的函数,采用核函数求解判别函数,并在傅里叶域中计算关键参数,实现快速跟踪。每帧图像经过灰度处理和预处理后,计算响应值,选择最大响应作为目标位置,不断更新目标状态。存在的疑问包括alpha中高斯分布的含义及Hann窗的作用等。
本文深入探讨了利用核函数的最小二乘法(RLS with Kernels)在目标跟踪中的应用。文章通过结构风险最小化的函数,采用核函数求解判别函数,并在傅里叶域中计算关键参数,实现快速跟踪。每帧图像经过灰度处理和预处理后,计算响应值,选择最大响应作为目标位置,不断更新目标状态。存在的疑问包括alpha中高斯分布的含义及Hann窗的作用等。
Tracking学习系列原创,转载标明出处: http://blog.csdn.net/ikerpeng/article/details/40144497
这篇文章很赞啊!很有必要将其好好的学习,今天首先记录它的代码思路(详细的推导过程后面会给出的)。
首先,这篇文章使用的决策函数是一个结构风险最小化的函数:
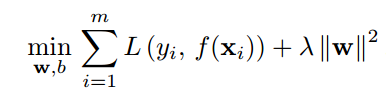
这个函数中:前面是一个损失函数,损失函数里面的f(x)就是最后要求的判别函数;后面是一个结构化的惩罚因子。对于SVM分类器来讲就是合页损失函数(Hinge loss)。但是实际上&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









