







任何数据都要通过计算来产生价值才有意义,大数据也一样。结构化大数据的计算能力的高低决定了大数据的实用性。
我总结了几种常见的计算方法:API 、Script、SQL、类SQL。
1、 API:这是指没有使用JDBC或ODBC,而是自成体系的API访问方法。以MapReduce为例,MapReduce从底层就是以廉价并行计算为设计目标的,所以它的横向扩展性最好,扩容时无需停机,成本最低。MapReduce是Hadoop的组件之一,代码开源,资料丰富。示例如下:
publicvoid reduce(Text key, Iterator<Text> value,
OutputCollector<Text,Text> output, Reporter arg3)
throws IOException {
double avgX=0;
double avgY=0;
double sumX=0;
double sumY=0;
int count=0;
String [] strValue = null;
while(value.hasNext()){
count++;
strValue = value.next().toString().split("\t");
sumX = sumX +Integer.parseInt(strValue[1]);
sumY = sumY +Integer.parseInt(strValue[1]);
}
avgX = sumX/count;
avgY = sumY/count;
tKey.set("K"+key.toString().substring(1,2));
tValue.set(avgX + "\t" +avgY);
output.collect(tKey, tValue);
}
MapReduce使用的是通用编程语言,并不适合专业的数据计算,因此计算能力要比SQL等专业的计算语言低。它的开发效率同样低,“痛苦”是程序员对MapReduce开发过程的普遍感觉。另外死板的框架使MapReduce的性能也较差。
用API的产品还有很多,但MapReduce是其中最典型的。
2、 Script:这里的Script是指SQL之外的专业的计算脚本语言,以集算器为例,它除了具有廉价横向扩容能力外,计算能力强特别是异种数据源之间的计算方便、适合复杂计算等特点,也提高了Hadoop的能力。另外它使用的是网格脚本,调试方便。示例如下:
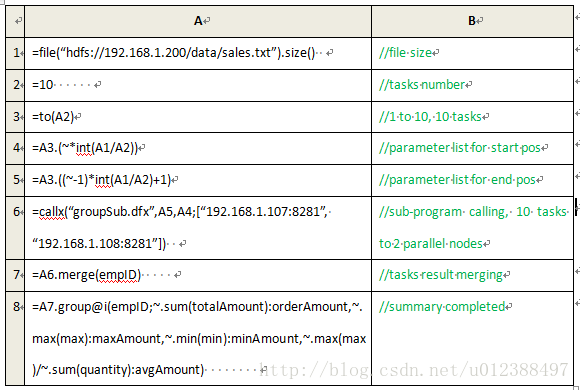
JAVA调用集算器的计算结果时要通过 JDBC,但只能以存储过程的形式调用,不能是任意的SQL语句,这是它的一大缺陷。不开源是它的另一个缺点。
MongoDB,Redis等很多大数据方案都使用了Script,但他们在计算方面不够专业。比如MongoDB的多表关联计算不仅运算效率低,而且代码复杂度太高。
-----------未完---------------
个人观点,欢迎交流,转载请注明地址。















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









