






转自: http://blog.csdn.net/u012388497/article/details/13019623
任何数据都要通过计算来产生价值才有意义,大数据也一样。结构化大数据的计算能力的高低决定了大数据的实用性。
我总结了几种常见的计算方法:API 、Script、SQL、类SQL。
1、 API:这是指没有使用JDBC或ODBC,而是自成体系的API访问方法。以MapReduce为例,MapReduce从底层就是以廉价并行计算为设计目标的,所以它的横向扩展性最好,扩容时无需停机,成本最低。MapReduce是Hadoop的组件之一,代码开源,资料丰富。示例如下:
publicvoid reduce(Text key, Iterator<Text> value,
OutputCollector<Text,Text> output, Reporter arg3)
throws IOException {
double avgX=0;
double avgY=0;
double sumX=0;
double sumY=0;
int count=0;
String [] strValue = null;
while(value.hasNext()){
count++;
strValue = value.next().toString().split("\t");
sumX = sumX +Integer.parseInt(strValue[1]);
sumY = sumY +Integer.parseInt(strValue[1]);
}
avgX = sumX/count;
avgY = sumY/count;
tKey.set("K"+key.toString().substring(1,2));
tValue.set(avgX + "\t" +avgY);
output.collect(tKey, tValue);
}
MapReduce使用的是通用编程语言,并不适合专业的数据计算,因此计算能力要比SQL等专业的计算语言低。它的开发效率同样低,“痛苦”是程序员对MapReduce开发过程的普遍感觉。另外死板的框架使MapReduce的性能也较差。
用API的产品还有很多,但MapReduce是其中最典型的。
2、 Script:这里的Script是指SQL之外的专业的计算脚本语言,以集算器为例,它除了具有廉价横向扩容能力外,计算能力强特别是异种数据源之间的计算方便、适合复杂计算等特点,也提高了Hadoop的能力。另外它使用的是网格脚本,调试方便。示例如下:
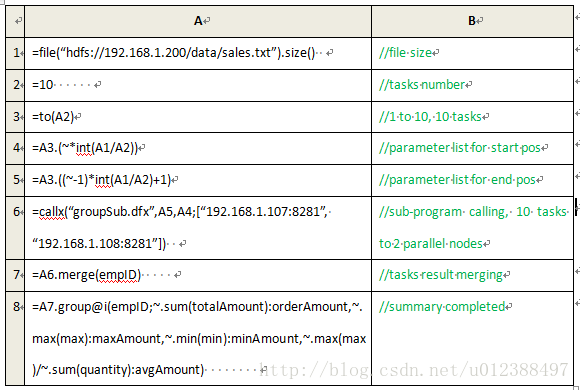
JAVA调用集算器的计算结果时要通过 JDBC,但只能以存储过程的形式调用,不能是任意的SQL语句,这是它的一大缺陷。不开源是它的另一个缺点。
MongoDB,Redis等很多大数据方案都使用了Script,但他们在计算方面不够专业。比如MongoDB的多表关联计算不仅运算效率低,而且代码复杂度太高。
3、 SQL:这里是指完整的SQL/SP,即ANSI 2000或其超集。以Greenplum为例,GreenplumSQL计算能力强,开发效率高,性能高,这是它最大的优势。其他优势包括语言通用性强,学习成本低,维护简单、有一定的移植可能性。当然,它还有个绝招:支持存储过程,可以进行复杂的计算,因此可以方便地从大数据中获得商业价值。示例如下:
CREATE OR REPLACE functionview.merge_emp()
returns void as $$
BEGIN
truncate view.updated_record;
insert into view.updated_record selecty.* from view.emp_edw x right outer join emp_srcy on x.empid=y.empid where x.empid is not null;
update view.emp_edw setdeptno=y.deptno,sal=y.sal from view.updated_record y where view.emp_edw.empid=y.empid;
insert into emp_edw select y.* fromemp_edw x right outer join emp_src y on x.empid=y.empidwhere x.empid is null;
end;
$$ language 'plpgsql';
类似的MPP架构的数据库还有Teradata、Vertical 、Oracle、IBM等,它们的语法特征大多相似。缺点也有相似性。它们的购买成本和后续维护成本极高。其中自称廉价的Greenplum实则价格不菲,它按数据规模收费,被称为披着BigData外皮的BigMoney。其他缺点包括:难以调试、语法不兼容、扩容时停机时间长、难以进行多数据源的计算等。
4、类SQL:这是指具有JDBC/ODBC等输出接口,但仅是标准SQL的子集的一类脚本语言。这里以Hive QL为例。开发方便的同时可以廉价横向扩容,这是Hive QL最大的优势。它具有SQL的语法特征,因此学习成本低,开发效率高,维护简单。另外Hive是Hadoop的组件,开源是它的一大优势。示例如下:
SELECT e.* FROM (
SELECTname, salary, deductions["Federal Taxes"] as ded,
salary* (1 – deductions["Federal Taxes"]) as salary_minus_fed_taxes
FROMemployees
)e
WHEREround(e.salary_minus_fed_taxes) > 70000;
Hive QL的缺点是不支持存储过程,因此难以进行复杂计算,也就难以真正提供有价值的计算结果。稍复杂的计算它需要求助于MapReduce,开发效率很低。性能差,有门槛时间也是个致命弱点,比如分配任务,或执行多表关联计算、行间计算、多级子查询、有序分组计算等算法时。因此很难实现实时的Hadoop大数据应用。
也有其他产品支持类SQL,比如MongoDB,但比Hive尚有差距。
大数据计算的方法不外乎API 、Script、SQL、类SQL这四类,希望它们更进一步,出现更多成本低廉、计算能力强的实用产品。
转载于:https://blog.51cto.com/report5/1325200















 2608
2608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









